
Avec Gemma 4, Google DeepMind fait autant preuve de savoir-faire que d’ouverture. La nouvelle famille comporte quatre modèles multimodaux compacts, enfin diffusés sous une licence permissive, affichant des performances agentiques qui viennent clairement bousculer la hiérarchie de l’IA ouverte.
Depuis le lancement de la première génération début 2024, la famille Gemma, petite sœur « ouverte » de Gemini, a été téléchargée plus de 400 millions de fois et a engendré plus de 100 000 variantes communautaires, créant le fameux « Gemmaverse ». Gemma 1, puis Gemma 2 et Gemma 3 ont progressivement élargi les capacités : davantage de paramètres, davantage de langues, apparition de la multimodalité. Mais là où Gemini reste le produit propriétaire de Google, accessible via API payante et intégré à ses propres services cloud, Gemma joue la carte de la proximité développeur : des poids téléchargeables, exécutables en local, et adaptables par fine-tuning.
Le hic, jusqu’à présent ? La licence. Les précédentes versions de Gemma étaient distribuées sous une licence « maison » assortie de restrictions commerciales, de clauses de non-concurrence et de politiques d’usage encadrées. Un carcan qui limitait l’adoption dans les déploiements souverains ou les produits commerciaux à grande échelle.
Apache 2.0 : le grand virage
Gemma 4 rompt avec cette tradition et passe sous licence Apache 2.0, la même licence permissive utilisée par Qwen 3.5 ou Mistral AI (sur la plupart de ses modèles dont Small 4), et plus ouverte que la Community License de Llama 4 chez Meta. Concrètement, cela signifie : plus de plafond d’utilisateurs actifs mensuels, plus de politique d’usage imposée, liberté totale pour les déploiements commerciaux et souverains.
Mais attention : « open-weight » ne veut pas dire « open-source » au sens strict de l’OSI. Les poids du modèle sont librement disponibles, ce qui simplifie sa personnalisation, mais les données d’entraînement, le code complet du processus de formation et la recette d’alignement restent dans les seules mains de Google. Un choix commun à quasiment tous les acteurs du secteur : Llama 4 de Meta, Qwen 3.5 d’Alibaba, DeepSeek V3, Microsoft Phi, IBM Granite, Mistral… Tous partagent les poids, aucun ne partage vraiment tout. La nuance est importante, mais Gemma 4 fait néanmoins un pas de plus que ses prédécesseurs vers l’ouverture. Et c’est tant mieux.
Quatre modèles, deux tiers
Gemma 4 se décline en quatre tailles organisées en deux tiers : « Workstation » pour les charges lourdes (avec les modèles 31B Dense et 26B MoE), et « Edge » pour l’embarqué et le mobile (avec les modèles E2B et E4B).
Le 31B Dense est le fer de lance de la famille : il maximise la qualité brute et constitue la meilleure base de fine-tuning. Ses poids non quantifiés en bfloat16 tiennent sur un seul GPU NVIDIA H100 de 80 Go.
Le 26B MoE (Mixture of Experts) joue la carte de la latence : avec 128 petits experts dont seulement 8 (plus un expert partagé) sont activés pour chaque token, seuls 3,8 milliards de paramètres sont mobilisés à chaque inférence. Résultat : le modèle atteint environ 97 % de la qualité et de la pertinence du modèle 31B Dense pour une fraction du calcul. Google ne précise les capacités de calcul minimales pour son exécution, mais le modèle devrait être véloce sur tous les GPU.
Côté Edge, le E4B et le E2B (le « E » signifiant « effective parameters ») utilisent une technique appelée Per-Layer Embeddings (PLE) : au lieu du MoE, chaque couche du décodeur reçoit un vecteur de conditionnement spécifique par token, ce qui permet au E2B de tourner avec moins de 1,5 Go de RAM sur smartphone via le runtime LiteRT-LM. On parle bien d’un modèle capable de raisonner mais directement exécutable sur un smartphone ou sur un simple Raspberry Pi.
Une architecture qui innove sous le capot
Les quatre modèles partagent un socle architectural commun particulièrement soigné. L’attention hybride alterne des couches d’attention locale à fenêtre glissante (512 tokens pour les petits modèles, 1024 pour les grands) avec des couches d’attention globale sur l’intégralité du contexte, la dernière couche étant toujours globale. Ce design offre la rapidité d’un modèle léger sans sacrifier la compréhension profonde des contextes longs.
Pour gérer ces fameux contextes longs (jusqu’à 128 000 tokens pour les modèles Edge, 256 000 tokens pour les modèles Workstation), Gemma 4 embarque un système Dual RoPE : des embeddings rotatifs de position classiques pour les couches à fenêtre glissante, et des RoPE proportionnels (p-RoPE) pour les couches globales, ce qui préserve la qualité même sur de très longues distances textuelles.
Enfin, le cache KV partagé entre couches permet aux couches globales de réutiliser les tenseurs clé/valeur des couches précédentes, éliminant les projections redondantes et réduisant significativement l’empreinte mémoire à l’inférence.
La multimodalité est native sur l’ensemble de la famille : texte, images à résolution et ratio d’aspect variables, vidéo jusqu’à 60 secondes (sur les 26B et 31B), et audio (reconnaissance vocale, traduction) sur les modèles Edge E2B et E4B.
Une densité fonctionnelle impressionnante
Au-delà de l’architecture, c’est la densité fonctionnelle de Gemma 4 qui impressionne. Les modèles intègrent nativement l’appel de fonctions (function calling), la sortie JSON structurée, la planification multi-étapes, un mode de raisonnement étendu configurable (« thinking mode ») et même la détection de boîtes englobantes pour identifier des éléments d’interface, un atout pour l’automatisation de navigateurs web et le parsing d’écrans (mode computer use).
Autrement dit, Gemma 4 n’est pas qu’un modèle de génération de texte : c’est un moteur d’agents autonomes clé en main.
Des benchmarks qui parlent d’eux-mêmes
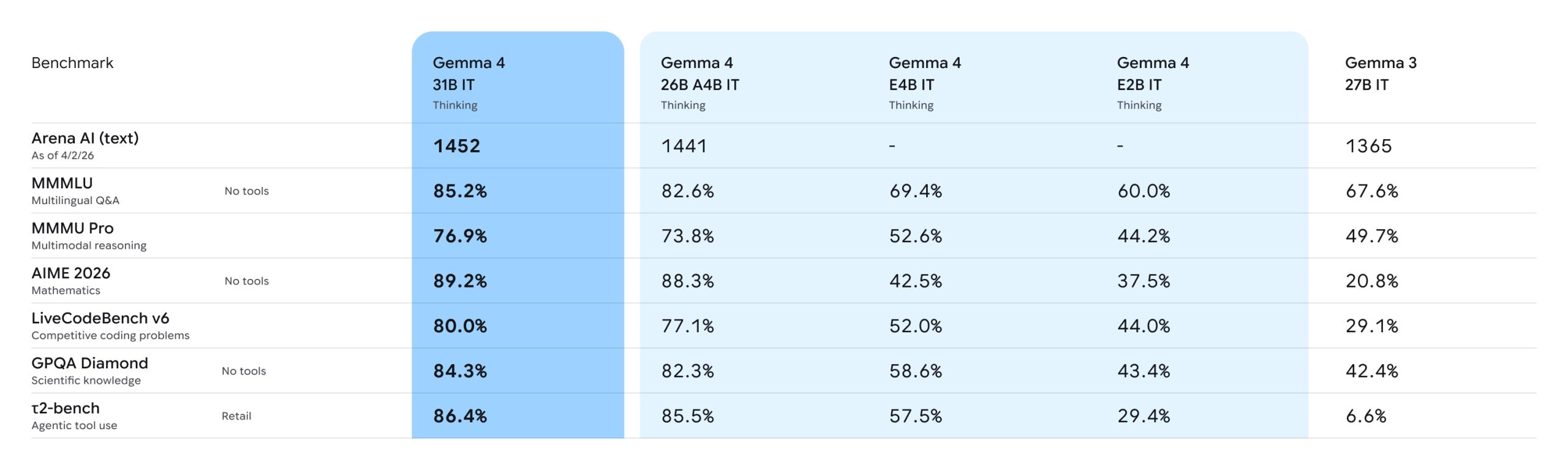
Et les benchmarks viennent confirmer les hautes ambitions de cette nouvelle famille. Sur AIME 2026 (mathématiques), le 31B atteint 89,2 % contre 20,8 % pour Gemma 3 27B. Le 26B MoE grimpe à 88,3 % avec seulement 3,8 milliards de paramètres actifs. Sur LiveCodeBench v6 (code compétitif), le 31B passe de 29,1 % (Gemma 3) à 80,0 %. Sur τ2-bench (usage agentique d’outils), le bond est vertigineux : de 6,6 % à 86,4 %.
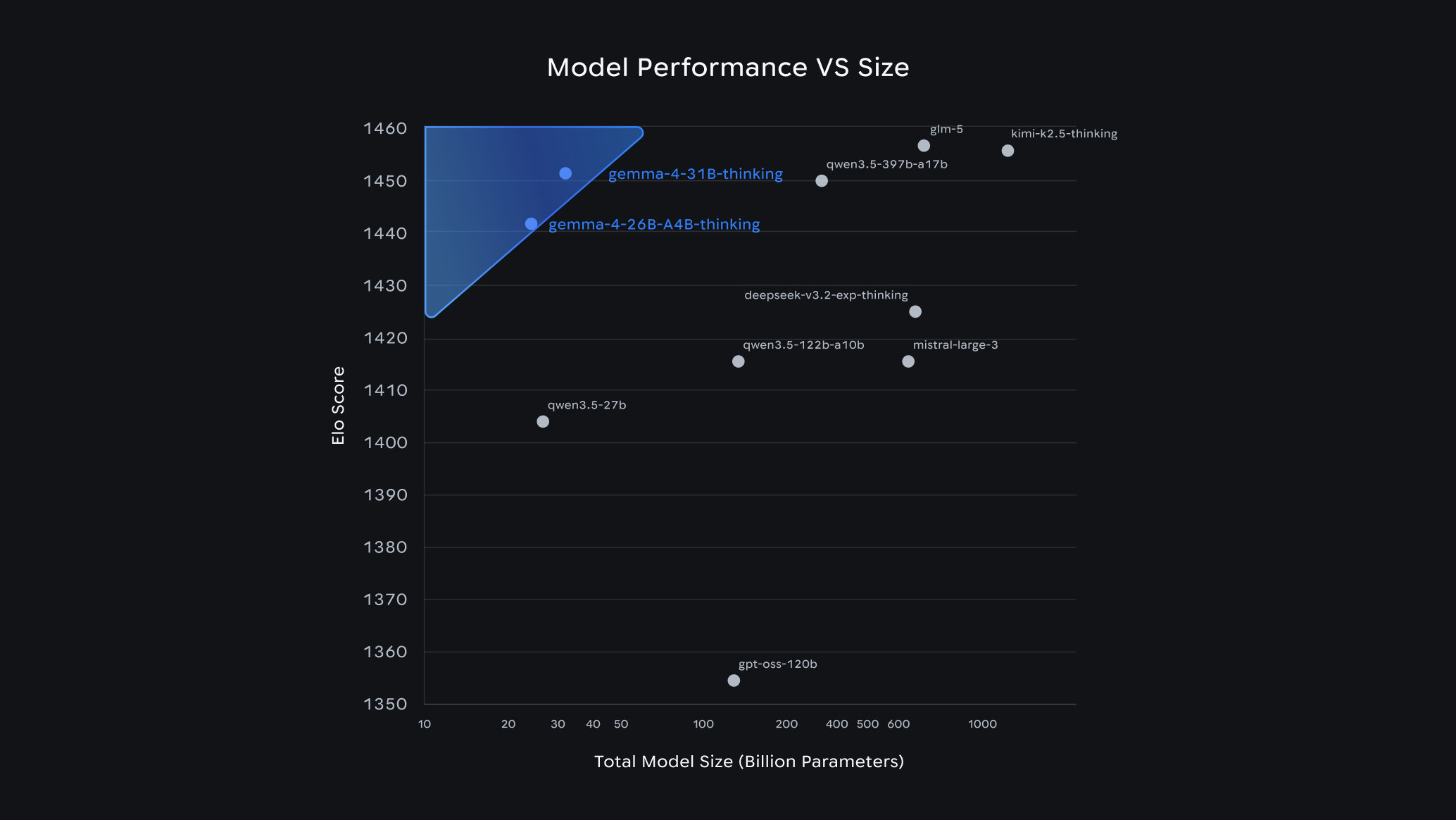
Sur le classement LMArena en texte seul, le 31B se hisse à la 3e place mondiale des modèles ouverts, juste derrière glm-5 de Z.ai et kimi k2.5-thinking mais devant gpt-oos-120b et Mistral Small, avec un score ELO d’environ 1452. Plus surprenant encore : le petit E2B surpasse Gemma 3 27B sur plusieurs tâches alors qu’il est 12 fois plus petit en paramètres effectifs.
Disponibilité immédiate
Les quatre modèles sont disponibles dès maintenant sur Hugging Face, Kaggle et Ollama. Google AI Studio permet de tester le 31B et le 26B MoE directement dans le navigateur. Le support « jour un » couvre Hugging Face Transformers, vLLM, llama.cpp, MLX, NVIDIA NIM, SGLang, LM Studio, Unsloth, Keras, Docker et bien d’autres.
Côté cloud, Vertex AI, Cloud Run et GKE sont bien évidemment de la partie. Les modèles Edge sont optimisés en partenariat avec Pixel, Qualcomm, MediaTek, ARM et NVIDIA.
L’ère agentique à portée de main
L’arrivée de Gemma 4 n’est pas qu’une itération de plus dans la course aux benchmarks mais un signal assez stratégique. En combinant une licence véritablement permissive, des capacités agentiques natives (function calling, planification multi-étapes, raisonnement configurable) et un déploiement allant du Raspberry Pi au datacenter, Google propose une réponse crédible aux Llama, Qwen et DeepSeek.
Pour les entreprises, cette sortie ouvre à un déploiement utile, pragmatique et économique de l’IA en local ou en cloud souverain, sans dépendance à une API propriétaire, avec des capacités agentiques suffisamment mûres pour automatiser des workflows réels. Le tout gratuitement et sans restriction commerciale.
L’IA ouverte en 2026, c’est du sérieux avec des capacités très étendues. Et Gemma 4 en est la meilleure illustration à ce jour.
____________________________

 puis
puis