
Mistral AI veut en finir avec l’empilement de briques IA spécialisées. Avec Small 4, la start-up française condense raisonnement, compréhension visuelle et génération de code dans un modèle unique, calibré pour aller vite, coûter moins cher et simplifier la vie des équipes techniques.
En moins de trois ans d’existence, Mistral AI a construit un catalogue de modèles qui ferait pâlir bien des acteurs historiques. Une richesse de portfolio qui n’a rien à envier à celle d’OpenAI, Anthropic, Alibaba Cloud ou Google. La start-up parisienne propose une gamme complète couvrant tous les étages de la fusée IA : Mistral Large 3 (675B paramètres) pour les tâches les plus exigeantes, les Ministral (3B à 14B) pour l’edge et l’embarqué, Codestral pour la génération de code, Pixtral pour le multimodal, Magistral pour le raisonnement avancé, Devstral et Leanstral pour le code agentique, et bien sûr la famille Mistral Small, positionnée comme le couteau suisse de l’entreprise.
Cette dernière occupe une place clé dans ce dispositif. Depuis Mistral Small 3, Mistral AI pousse l’idée d’un modèle capable de couvrir “80 %” des usages génératifs utiles en entreprise : assistant conversationnel rapide, orchestration de fonctions, spécialisation métier par fine-tuning, le tout avec une latence faible et une empreinte plus raisonnable que les très gros modèles. C’est précisément ce qui les rend attractifs pour les DSI : moins de complexité, moins de coûts d’inférence, et davantage de contrôle sur le déploiement. Et c’est aussi ce qui fait de cette famille l’une des références incontournables des modèles ouverts à l’échelon mondial.
Un petit modèle qui combine le meilleur du savoir-faire Mistral
Mistral AI dévoile cette semaine Mistral Small 4, une nouvelle génération de modèle open source pensée pour simplifier l’usage de l’IA avancée. Pour la première fois, l’éditeur français regroupe dans un seul modèle les capacités de raisonnement avancé (vues dans Magistral), de compréhension multimodale (expérimentées dans Pixtral) et d’assistance au code (peaufinées avec Devstral), jusque‑là réparties entre plusieurs briques spécialisées. Résultat : un outil polyvalent capable de passer d’une réponse rapide à une analyse approfondie, selon les besoins.
Sur le plan technique, Small 4 s’appuie sur une architecture Mixture of Experts de 119 milliards de paramètres, avec seulement 6 milliards activés par requête (8 milliards si l’on inclut les couches d’embeddings et de sortie), gage d’efficacité et de maîtrise des coûts. On notera que cet équilibre avec notamment 6 milliards de paramètres activés semble avoir la grande préférence de Mistral AI en ce moment, puisqu’on le retrouve également sur son nouveau modèle de codage à preuve formelle LeanStral.
Multimodal, Small 4 accepte texte et images, propose une fenêtre de contexte étendue à 256 000 tokens et introduit un réglage fin du niveau de raisonnement (via l’option reasoning_effort), permettant d’arbitrer entre latence et profondeur d’analyse.
Cette approche change fondamentalement le schéma de déploiement. Au lieu de maintenir en production un modèle rapide ET un modèle de raisonnement (avec le routage, le load balancing et la complexité opérationnelle que cela implique), les équipes techniques peuvent servir un seul modèle et ajuster le comportement d’inférence à la volée, requête par requête. Pour un DSI, c’est un facteur de simplification considérable de la pile applicative IA : un seul modèle pour le chatbot interne, l’analyse documentaire, l’assistant de support, l’agent de code et certains cas de recherche avancée.
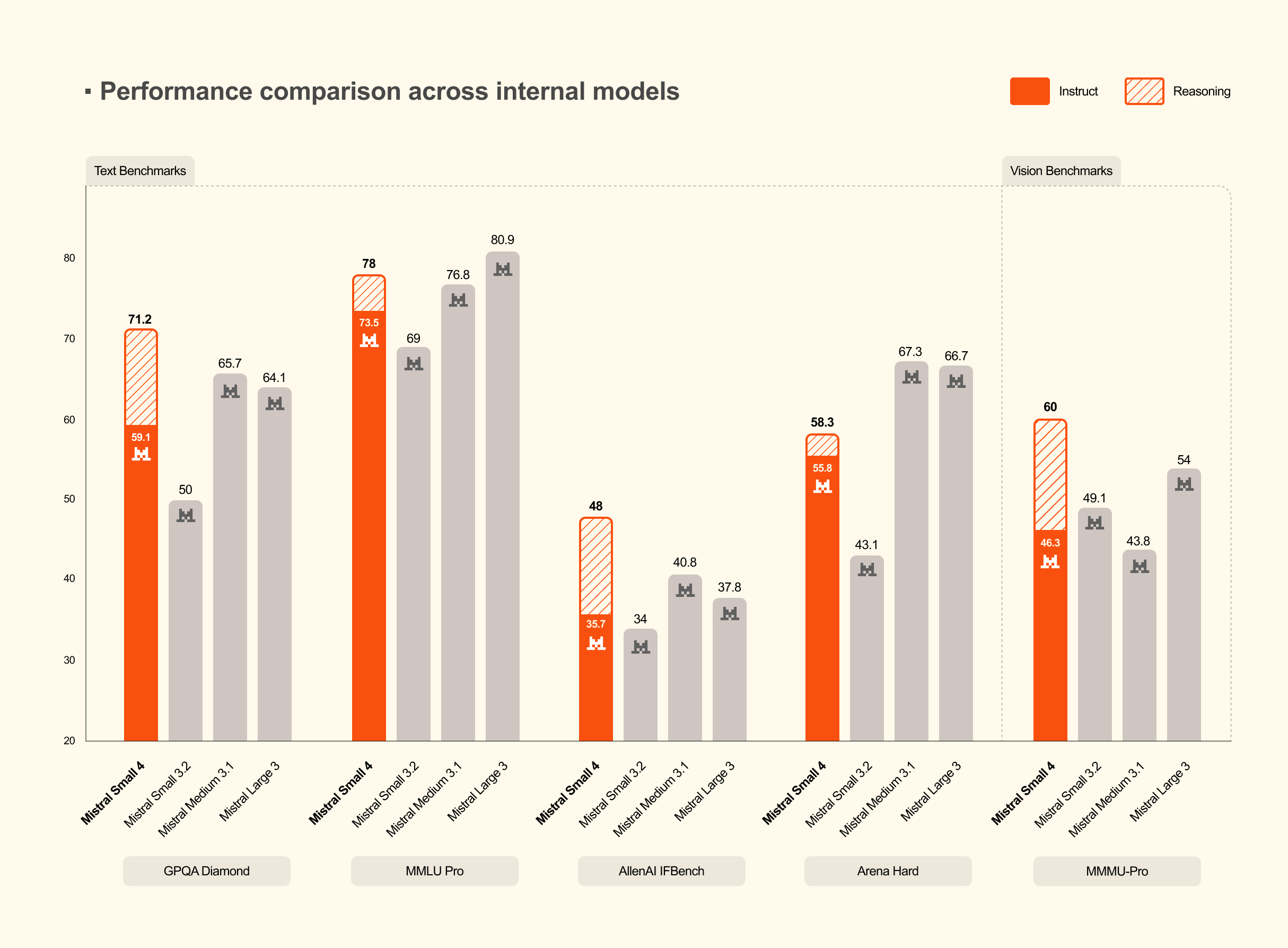
Des performances hautes à prix mini
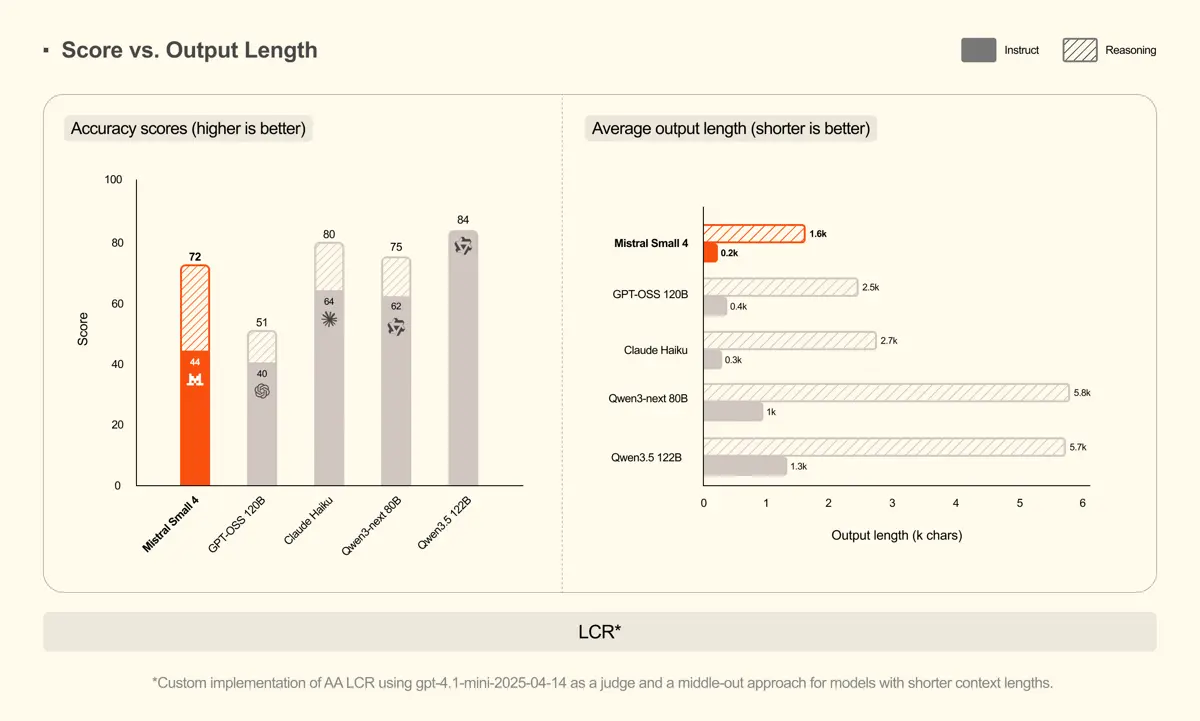
Sur les benchmarks, Mistral Small 4 avec raisonnement activé égale ou dépasse GPT-OSS 120B sur trois axes (AA LCR, LiveCodeBench, AIME 2025), tout en générant des réponses nettement plus courtes. Sur LiveCodeBench, le modèle surpasse GPT-OSS 120B avec 20 % de tokens en moins. Sur AA LCR, il atteint un score de 0,72 avec seulement 1 600 caractères de sortie, là où les modèles Qwen produisent 3,5 à 4 fois plus de texte pour des performances comparables. Et c’est tout sauf un détail. Des réponses plus courtes signifient une latence réduite, une meilleure expérience utilisateur mais surtout des coûts d’inférence plus bas !
Côté tarification API, Mistral Small 4 est proposé à 0,15 $ par million de tokens en entrée et 0,60 $ par million de tokens en sortie, sur « La Plateforme » d’OpenAI, un positionnement très agressif qui le place en concurrence directe avec les modèles « mini prix » des hyperscalers.
Fidèle à sa volonté de aire de l’open model non pas un produit d’appel, mais l’infrastructure de base d’une IA industrialisable, gouvernable et adaptable aux contraintes métier, Mistral AI distribue le modèle Mistral Small 4 sous licence Apache 2.0. Optimisé pour les infrastructures NVIDIA et déjà intégré aux principaux frameworks open source, le modèle vise aussi bien les développeurs que les entreprises cherchant une IA performante, adaptable et économiquement soutenable.
En termes d’infrastructure minimale pour un déploiement interne, Mistral Small 4 nécessite 4 GPU NVIDIA HGX H100, ou 2 GPU HGX H200, ou encore 1 seul GPU DGX B200. La configuration recommandée pour des performances optimales est cependant de 4x HGX H100, 4x HGX H200, ou 2x DGX B200. On est donc encore assez loin d’un modèle « portable sur laptop » comme l’étaient les précédents Mistral Small à 24B paramètres, mais le rapport capacité/infrastructure reste remarquable pour un modèle de cette envergure.
Au fond, Mistral Small 4 n’est pas juste un “petit modèle” de plus. C’est la tentative, très assumée, de transformer la catégorie des modèles compacts en véritables couteaux suisses d’entreprise. Et si la promesse tient en production, beaucoup d’organisations pourraient bien préférer ce type de modèle unifié, plus léger à opérer et plus simple à gouverner, à l’empilement de briques spécialisées. Pour Mistral AI, c’est aussi une manière habile de rappeler qu’en IA, le vrai luxe n’est plus seulement la puissance brute. C’est la capacité à faire beaucoup, vite, et sans enfermer le client.
____________________________

 puis
puis