Après un Opus 4.7 parfois trop sûr de lui, Anthropic dégaine Claude Opus 4.8 avec une promesse simple : réfléchir davantage, bluffer moins. Au menu, moins d’hallucinations, plus d’alignement, du codage agentique renforcé et des workflows capables d’attaquer de très grosses bases de code.
Quarante et un jours. C’est le temps qu’aura mis Anthropic entre Opus 4.7 et Opus 4.8, un rythme inhabituellement rapide même pour cet éditeur. Le cycle, bien plus court que d’ordinaire (les derniers Sonnet et Haiku ont respectivement trois et sept mois), n’est sans doute pas étranger à l’accueil mitigé réservé à Opus 4.7 dont la fonctionnalité de réflexion auto-adaptative a dérouté certains utilisateurs. En outre, Opus 4.7 se montrait parfois trop têtu : le modèle argumentait jusqu’à l’hallucination, résistait aux corrections et produisait par endroits un code de moins bonne qualité qu’Opus 4.6. S’ajoutaient des erreurs énoncées avec aplomb, des comportements par défaut instables et des coûts en hausse.
Bref, Anthropic avait une revanche à prendre. Et la prend par un angle inattendu.
Un modèle plus honnête
Oubliez un instant les benchmarks. La nouveauté la plus marquante d’Opus 4.8, selon Anthropic, c’est son honnêteté. Derrière le mot un peu candide se cache un vrai problème d’IA : ces modèles ont fâcheusement tendance à clamer victoire sans preuves solides voire à « halluciner » du progrès.
Selon les premiers retours des testeurs, Opus 4.8 signale davantage ses incertitudes et formule moins d’affirmations non étayées. Mieux : le modèle serait environ quatre fois moins susceptible que son prédécesseur de laisser passer sans commentaire des défauts dans le code qu’il a lui-même écrit. Pour un développeur, un assistant qui dit « attention, je ne suis pas sûr de ce bout-là » vaut souvent mieux qu’un assistant brillant mais menteur.
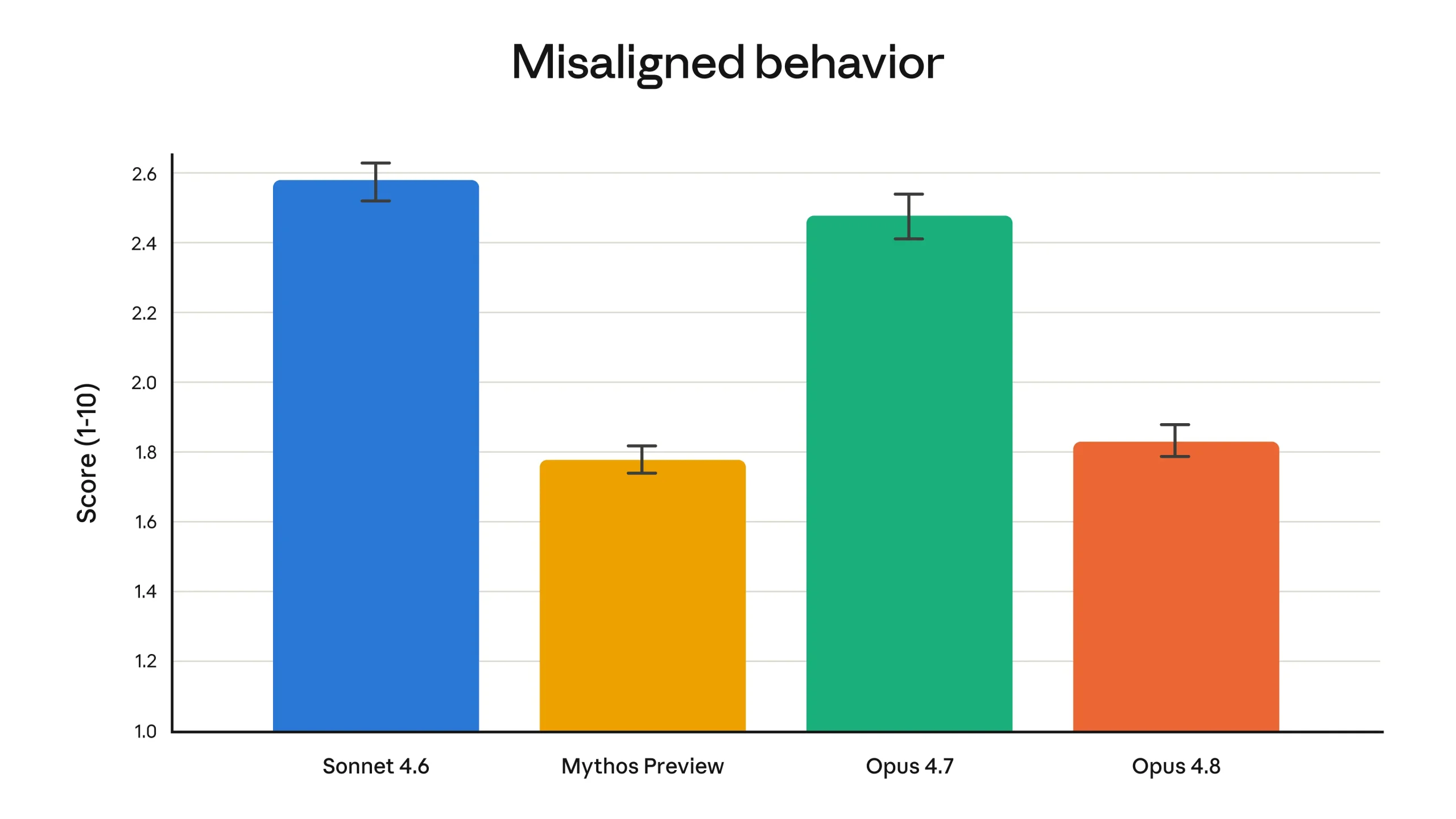
Dans un même ordre d’idées, l’équipe d’Anthropic affirme qu’Opus 4.8 atteint de nouveaux sommets en matière d’alignement. Rappelons que l’alignement désigne le degré auquel le comportement d’un modèle reste fidèle aux intentions et aux intérêts de l’utilisateur comme aux valeurs voulues par ses concepteurs : un modèle bien aligné fait ce qu’on attend vraiment de lui, sans chercher à tromper, à contourner les consignes ou à poursuivre des objectifs détournés. Sur ce terrain, Opus 4.8 progresserait notamment sur les traits dits prosociaux – au premier rang desquels le soutien à l’autonomie de l’utilisateur – tout en affichant des taux de comportements désalignés (déception, complaisance face à un usage malveillant) nettement inférieurs à ceux d’Opus 4.7. Un point d’autant plus scruté que c’est précisément sur ces dérives comportementales que son prédécesseur avait trébuché.
Les benchmarks, quand même
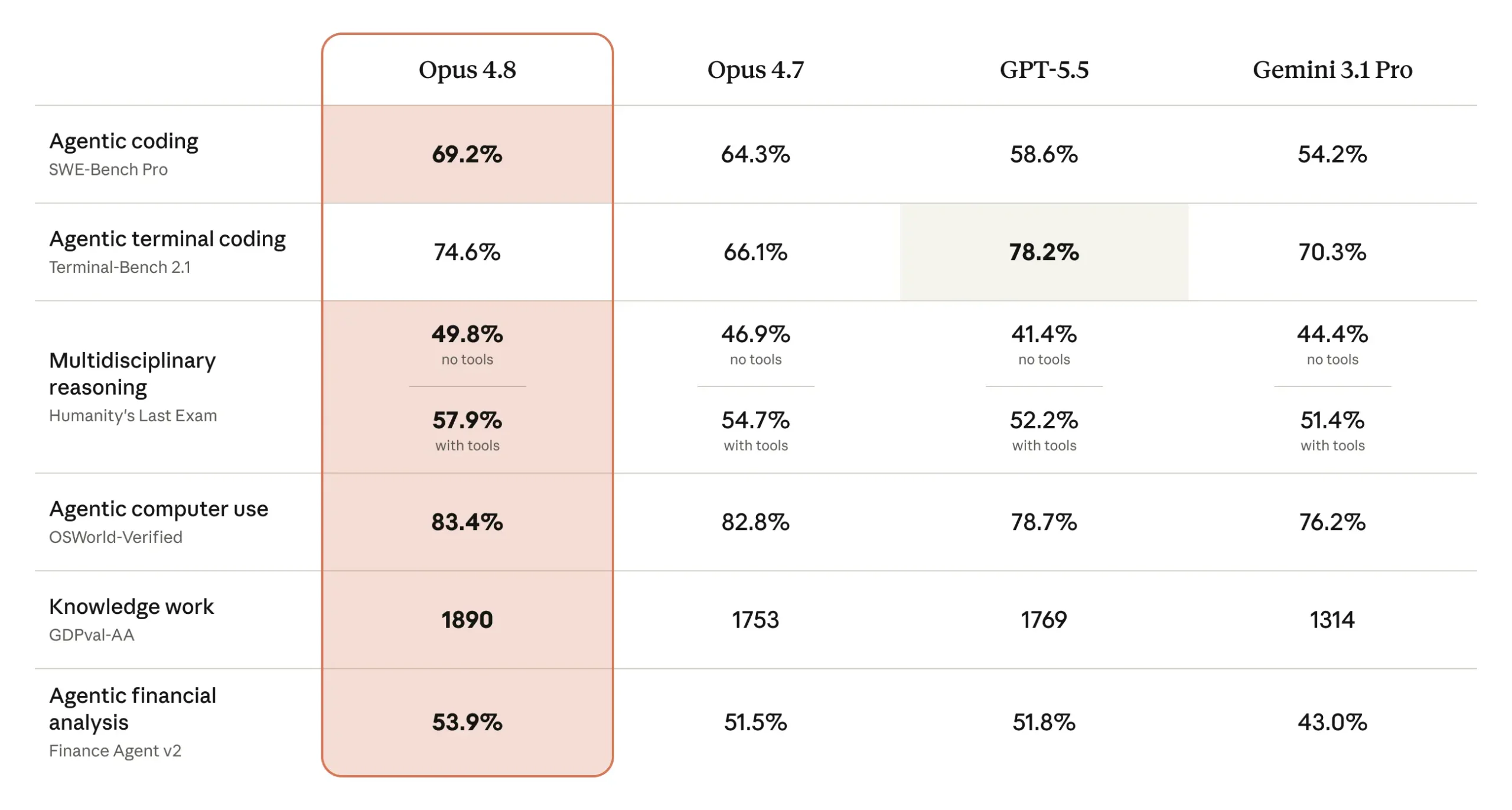
Rassurez-vous, la performance brute progresse aussi. Les gains les plus nets concernent le codage agentique en terminal, le travail de la connaissance et l’analyse financière agentique, trois domaines au cœur des usages professionnels. Sur le terrain du codage, Anthropic met en avant ses résultats sur Terminal-Bench 2.1, le benchmark de référence pour les tâches menées en ligne de commande. Côté usage agentique de l’ordinateur – ces scénarios où le modèle pilote lui-même un navigateur ou une interface – Opus 4.8 atteint 84 % sur Online-Mind2Web, un bond significatif par rapport à Opus 4.7 comme à GPT-5.5.
La finance n’est pas en reste avec le benchmark Finance Agent v2, tandis que l’analyse de documents non structurés (PDF, diagrammes) bénéficie des progrès multimodaux du modèle.
Surtout, ces gains s’accompagnent d’une meilleure efficience : à effort égal, le modèle tend à atteindre le même résultat en sollicitant moins d’étapes et moins de tokens, un détail qui pèse vite lourd sur la facture à grande échelle.
Du nouveau dans Claude AI et Cowork
Le modèle ne vient pas seul. Première nouveauté grand public : un contrôle d’effort débarque dans claude.ai et Cowork, à côté du sélecteur de modèle. Concrètement, l’utilisateur choisit l’intensité de raisonnement : un effort plus élevé pour des réponses plus réfléchies, un effort plus réduit pour des réponses plus rapides qui consomment bien moins vite vos quotas. Cinq niveaux d’effort sont désormais proposés : Low, Medium, High (par défaut), Extra, Max.
La fonctionnalité est disponible sur tous les forfaits.
La deuxième nouveauté, plus musclée, est à chercher du côté de Claude Code : les Dynamic Workflows. En preview de recherche, cette fonction permet à Claude de planifier une tâche, puis de lancer des centaines de sous-agents en parallèle dans une même session, avant de vérifier ses résultats. L’exemple donné fait rêver (ou frémir) les DSI : Claude Code avec Opus 4.8 peut désormais mener des migrations à l’échelle d’une base de code, sur des centaines de milliers de lignes, du lancement jusqu’au merge, avec la suite de tests existante comme juge de paix.
Le bon plan tarifaire
La facture, elle, ne bouge pas. Le tarif reste identique à Opus 4.7 : 5 dollars par million de tokens en entrée, 25 dollars en sortie. Surprise : le mode rapide, qui travaille à 2,5× la vitesse, est désormais trois fois moins cher qu’auparavant.
____________________________

 puis
puis