
Lors de sa conférence sur l’économie digitale, dans ses nouveaux locaux de Levallois Perret, SAP n’a pas annoncé « en grande pompe » la version SPS 10, la mise à jour « la plus importante » depuis son lancement de SAP HANA. C’est à Nice que la nouvelle version, en fait un service pack, a été présentée lors de la conférence de HANA SAPinsider 2015, qui se déroulait du 16 au 18 Juin, des informations relayées en direct via les tweets du site et sur le blog sapana.com. Plus ouverte vers de nouvelles sources de données, elle va tenter de séduire les nouveaux acteurs de la transformation numérique, les responsables des divisions métiers. Une manière de réconcilier parfois dans certaines structures un peu rigides, une informatique traditionnelle avec les innovateurs. L’approche métier, la redéfinition des usages fait partie prenante de la nouvelle version de SAP qui veut offrir justement ces approches métiers grâce en grande partie à cette ouverture sur le Big data, la gestion des objets (IOT) via internet et la mobilité. Un discours repris à Levallois lors du Digital Economic Forum.( lire le résumé de la conférence : Sap enfonce le clou de la transformation digitale).
Une version 10 plus ouverte
Le président du groupe SAP Platform Solutions, Steve Lucas,( image d’ouverture) a donc profité de ce rendez-vous pour annoncer la version 10 de SAP qui étend les capacités de gestion des données dans la plate-forme IN memory tout en intégrant des fonctions complémentaires pour « pomper des données » venues de l’extérieur ou simplement les analyser plus aisément. On retiendra l’utilisation simplifiée du programme Predictive Analytic à partir de la version 2.2 .
La principale fonction annoncée par Steve Lucas est la synchronisation bidirectionnelle entre les systèmes sur site (on premise) et les terminaux distants. Elle permet de mettre à jour de manière cohérente les données entre l’entreprise et les sites distants. A priori, cela parait tellement important que l’on se pose des questions sur la méthode utilisée actuellement. Le coté « bijectif » n’était pas automatique apparemment, surtout au travers du cloud.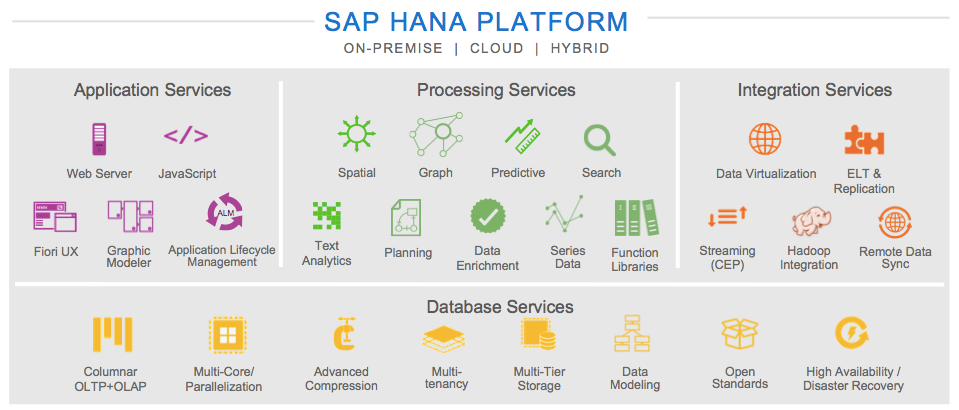
Les autres fonctions notables comprennent la hiérarchisation dynamique des données, selon des règles bien définies par l’administrateur, entre les différentes classes de système de stockage à l’intérieur et hors de HANA. Il faut noter aussi l’intégration élargie des distributions Hadoop de Cloudera, celle d’Hortonworks et de Map R.
Cette version a aussi la capacité de nettoyer les résultats des recherches en identifiant par exemple les données en double, et surtout la version combinée qui utilise les outils Hadoop exploitera le logiciel Ambari (issu de l’open source Apache) pour offrir une interface utilisateur commune pour l ‘administration de cluster. Ceux qui associeront SAP HANA et Hadoop. Cette évolution comprend le transfert de données plus rapide avec Spark SQL. Rappelons que pour simplifier l’exploration des données, Spark SQL offre une API de haut niveau avec une syntaxe SQL. Spark SQL permet ainsi de réaliser, très rapidement, de nombreuses opérations sans écrire de code, ou presque.
Vive l’open Source
Bill Mac Dermott lors de sa visite à Paris il y a peine deux mois, s’était gaussé des afficionados de l’open Source mais désormais sa firme surfe aussi sur l’accompagnement des outils Hadoop, et sur Ambari. Mais il est vrai aussi que les intégrateurs cités sont en train d’en faire des versions propriétaires. La firme allemande a montré aussi son implication dans l’internet des objets avec l’utilisation des technologies contenues dans SAP SQL Anywhere.
Une intégration qui vient de loin
De ce coté, SAP réchauffe les plats car depuis plus de 20ans, existent des applications M2M (machine to machine) qui utilisent la technologie de Sybase, SQL anywhere; elle revendique d’ailleurs 12 millions de licences, un record pour un logiciel de communication de ce type. 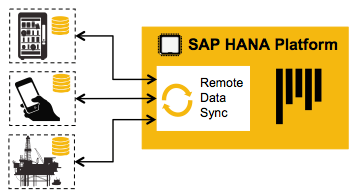 Cette firme rachetée par SAP en 2010 pour 5,8 milliard d’euros disposait de ce produit issu du rachat de Powersoft qui lui même l’avait racheté à la firme Watcom en 1994, le produit s’appelant au départ Watcom SQL en 1992, puis SQL Anywhere studio. Bref, cette technologie a fait ses preuves dans ce secteur et c’est sûrement le logiciel de collecte d’informations sur des objets le plus répandu sur terre. Il fonctionne sans souci sur des milliers de sites mais sans avoir utilisé forcement le réseau internet, le système pouvant s’interconnecter sur les messageries SMS et le GSM data.
Cette firme rachetée par SAP en 2010 pour 5,8 milliard d’euros disposait de ce produit issu du rachat de Powersoft qui lui même l’avait racheté à la firme Watcom en 1994, le produit s’appelant au départ Watcom SQL en 1992, puis SQL Anywhere studio. Bref, cette technologie a fait ses preuves dans ce secteur et c’est sûrement le logiciel de collecte d’informations sur des objets le plus répandu sur terre. Il fonctionne sans souci sur des milliers de sites mais sans avoir utilisé forcement le réseau internet, le système pouvant s’interconnecter sur les messageries SMS et le GSM data.
Sur le Blog sapana. Com tenu par Mike Eacrett, le vice-président de la gestion de produit pour SAP, on peut lire que du coté matériel : » le logiciel est désormais pris en charge sur les systèmes IBM Power8 sous SUSE Linux (pour SAP BW sur HANA). D’autre part, hanap profite désormais des processeurs Intel Haswell avec TSX qui améliorent significativement les traitements transactionnels jusqu’à 6x. Pour les centres de données et la virtualisation du cloud, ont été ajoutés le support de VMware vSphere 5.5 dans les déploiements scale-out (en disponibilité contrôlée), ainsi que le partionnement logique (LPAR)d’IBM et Hitachi Data Systems (HDS).
Du côté des chiffres annoncés par SAP, on retiendra qu’il y aurait maintenant 6400 clients SAP HANA et près de 815 000 utilisateurs actifs, soit deux fois plus que l’an dernier. La plate forme Cloud « SAP HANA Cloud Platform » serait exploitée par ces clients.
Enfin, SAP a précisé que près de 1.900 éditeurs de logiciels indépendants étudient la plate-forme pour créer des passerelles ou des outils à part entière,150 d’entre eux ayant déjà applications viables.

 puis
puis