
À peine un modèle frontière est-il en production qu’un autre débarque avec davantage de raisonnement et de meilleures aptitudes agentiques. Avec Gemini 3.1 Pro en préversion, Google remet les gaz et cherche à convertir des percées “Deep Think” en raisonnement par défaut, tout en capitalisant sur ses capacités de distribution massive.
Restée très stagnante entre mi-2024 et mi-2025, la course à l’innovation autour des LLM frontières s’est accéléré à un rythme très intense depuis août 2025 et la sortie de GPT-5. En moins de 6 mois GPT-5.1 Pro, GPT-5.2 Pro, Claude Opus 4.5, Claude Opus 4.6 et bien sûr Gemini 3 Pro ont très significativement repoussé les limites du savoir et des capacités cognitives des grands LLM. L’intervalle entre deux annonces « majeures » laisse à peine le temps de déployer un modèle frontière en production avant qu’une alternative significativement plus douée ne débarque.
Cette fois, c’est à Google de reprendre la main sur l’avance technologique dans l’IA avec la sortie hier soir en préview de Gemini 3.1 Pro qui promet un doublement des capacités de raisonnement et compte bien transformer les percées du mode avancé « Deep Think » de la précédente génération en capacités de base prêtes à l’emploi.
En sortant Gemini 3 Pro à l’automne dernier, Google démontrait avoir complètement refait son retard sur les pionniers OpenAI (GPT-5.2) et Anthropic (Claude Opus 4.5). Mais il faut reconnaître que, ces derniers mois, avec son Gemini 3, Google a surtout gagné là où les autres acteurs peuvent difficilement le suivre : la distribution à grande échelle avec les 2 milliards d’utilisateurs mensuels d’AI Overviews (dans Google Search) et les 750 millions d’utilisateurs mensuels de son App Gemini. Au point que les modèles Gemini 3 traitent désormais plus de 10 milliards de tokens par minutes !
Cependant, depuis novembre dernier, Anthropic et OpenAI avaient repris l’avantage sur plusieurs métriques clés, reléguant Gemini 3 Pro au rang de challenger. Il était donc temps pour Google de se réagir et contre-attaquer. Et la réponse se nomme « Gemini 3.1 Pro ».
Un saut remarquable
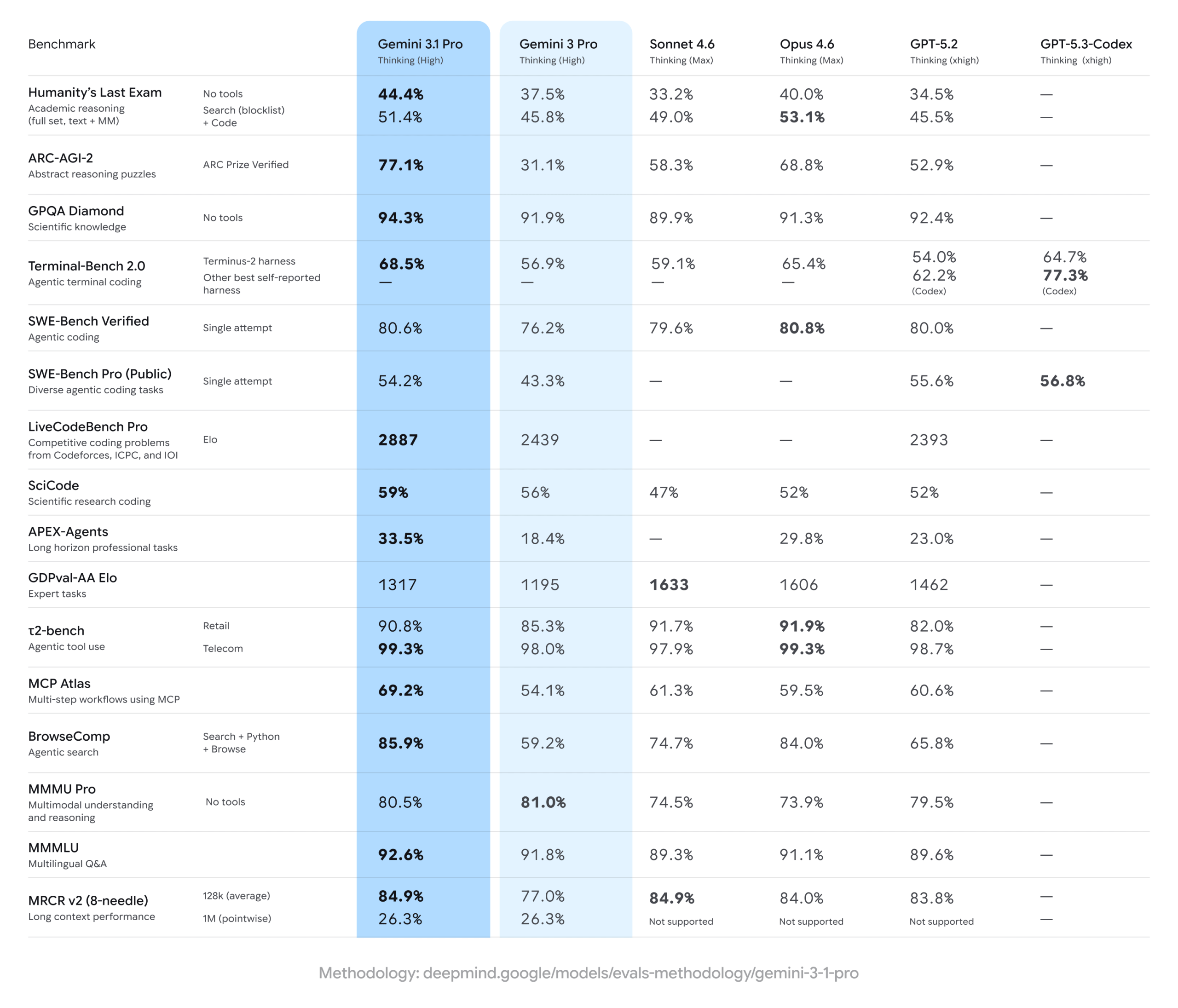
Première mise à jour incrémentale de ce type chez Google (jusqu’ici la firme procédait par bond de « .5 »), cette itération se concentre sur une amélioration drastique des capacités de raisonnement fondamental du modèle. Les résultats sont là : sur le benchmark ARC-AGI-2, qui évalue la résolution de schémas logiques totalement inédits, le modèle pulvérise son prédécesseur avec un score de 77,1 %, doublant ainsi ses capacités (Gemini 3 Pro se contentait d’un 31,1%). Il excelle également sur le test scientifique GPQA Diamond avec un record de 94,3 %, surpassant les solutions concurrentes sur les tâches professionnelles de longue haleine (Claude Opus 4.6 atteint 91,3 % et GPT-5.2 obtient 92,4 %).
Au total, Gemini 3.1 Pro domine 13 des 16 benchmarks présentés par Google, incluant des métriques sur le codage agentique (80,6 % sur SWE-Bench Verified), les tâches professionnelles longues (33,5 % sur APEX-Agents, contre 29,8 % pour Opus 4.6 et 23 % pour GPT-5.2) ou la compréhension multimodale (92,6 % sur MMMLU).
Capable de générer des animations SVG codées prêtes pour le web ou de configurer des flux de télémétrie spatiale complexes, ce nouveau modèle vise directement les workflows avancés.
« Gemini 3.1 Pro est idéal pour les tâches hyper complexes comme la visualisation de concepts difficiles, la synthèse de données ou la concrétisation de projets créatifs. Nous le déployons sur nos produits grand public et développeurs pour apporter ce bond en intelligence à vos applications quotidiennes » explique Sundar Pichai, CEO de Google.
Google avance d’ailleurs d’autres exemples montrant les étonnantes capacités de réflexion et de résolution de problèmes complexes. Dans un exemple, le modèle crée un dashboard temps réel exploitant une télémétrie publique pour visualiser l’orbite de l’ISS. Un autre exemple montre une expérience 3D de « murmuration » d’étourneaux manipulable via hand‑tracking, avec une musique générative, une façon de rappeler que Gemini va bien au-delà des capacités textuelles. Un troisième exemple illustre les capacités de Gemini 3.1 Pro pour créer une interface de portfolio inspirée de l’atmosphère des Hauts de Hurlevent. Des démos plutôt bluffantes.
[arve url= »https://storage.googleapis.com/gweb-uniblog-publish-prod/original_videos/Gemini_3.1_Demo_GC_V6-lr.mp4#t=0.001″ /]
Pas un carton plein pour autant
Les bons résultats affichés ne constituent cependant pas un grand chelem, preuve que la bataille reste tendue au sommet des modèles LLM. Claude Opus 4.6 d’Anthropic conserve la première place sur Humanity’s Last Exam (avec outils), sur SWE-Bench Verified selon certaines configurations, et sur τ²-bench. Son modèle Sonnet 4.6, en configuration « Thinking Max », affiche le meilleur score Elo sur GDPval-AA (1 633 contre 1 317 pour Gemini 3.1 Pro). Côté OpenAI, GPT-5.3-Codex domine sur Terminal-Bench 2.0 avec son propre environnement d’évaluation (77,3 % contre 68,5 %) et sur SWE-Bench Pro (56,8 % contre 54,2 %).
Bien sûr, les benchmarks restent très limités dans leur capacité à refléter les progrès sur les usages réels. Tout dépend des entreprises et de leurs cas d’usage. Ainsi, sur les premiers tests effectués par la rédaction d’InformatiqueNews, Gemini 3.1 Pro s’est montré sans conteste supérieur à Gemini 3 Pro et d’une très convaincante concision (un point qui a souvent fait défaut aux modèles Gemini) mais dans l’ensemble un tout petit peu moins convaincant que Claude Opus 4.6 qui ne cesse de nous épater quotidiennement depuis sa sortie (malgré une tendance à l’hallucination qui semble désormais quasiment totalement absente chez GPT-5.2).
Un écosystème de distribution massif
Reste que la force de Google tient dans sa capacité de diffusion. Gemini 3.1 Pro est déployé en « preview » sur un périmètre large.
Les développeurs y accèdent via l’API Gemini dans Google AI Studio, Gemini CLI, la plateforme de développement agentique Google Antigravity et Android Studio.
Les entreprises peuvent l’exploiter via Vertex AI et Gemini Enterprise.
Côté grand public, le modèle est disponible dans l’application Gemini et dans NotebookLM, pour les abonnés Google AI Pro et Ultra.
Fait notable : le modèle est également accessible depuis les outils Microsoft, notamment GitHub Copilot, Visual Studio et Visual Studio Code, preuve s’il en est que le géant de Redmond joue désormais la carte du choix étendu des modèles sans systématiquement pousser ceux d’OpenAI.
D’autant que Google reste très pertinent sur un autre axe de cette guerre des modèles frontières : le coût. Le tarif de Gemini 3.1 Pro reste inchangé à 2 dollars par million de tokens en entrée, et à 12$ par million de tokens en sortie. Ce qui revient à offrir un saut de performance significatif à coût constant. Le modèle conserve par ailleurs sa fenêtre de contexte d’un million de tokens. On notera quand même que Google (comme ses concurrents) pratiquent une surtaxe dès que l’on dépasse la fenêtre contextuelle de base (200.000 tokens) puisque, au-delà de cette barre et pour exploiter la fenêtre d’un million de tokens, la tarification grimpe ) 4 dollars en entrée et 18 dollars en sortie, des tarifs qui restent inférieurs à ceux pratiqués par la concurrence dans leurs modèles à contexte étendu.
Après la sortie récente et super convaincante de Claude Opus 4.6 et maintenant celle de Google avec ce très prometteur Gemini 3.1 Pro, on attend désormais la réponse d’OpenAI alors que son récent modèle spécialisé GPT-5.3-Codex a repris les devants en matière de « codage ». Une chose est sûre, la bataille des modèles frontières ne semble visiblement pas devoir connaître de trêve en 2026.

 puis
puis