
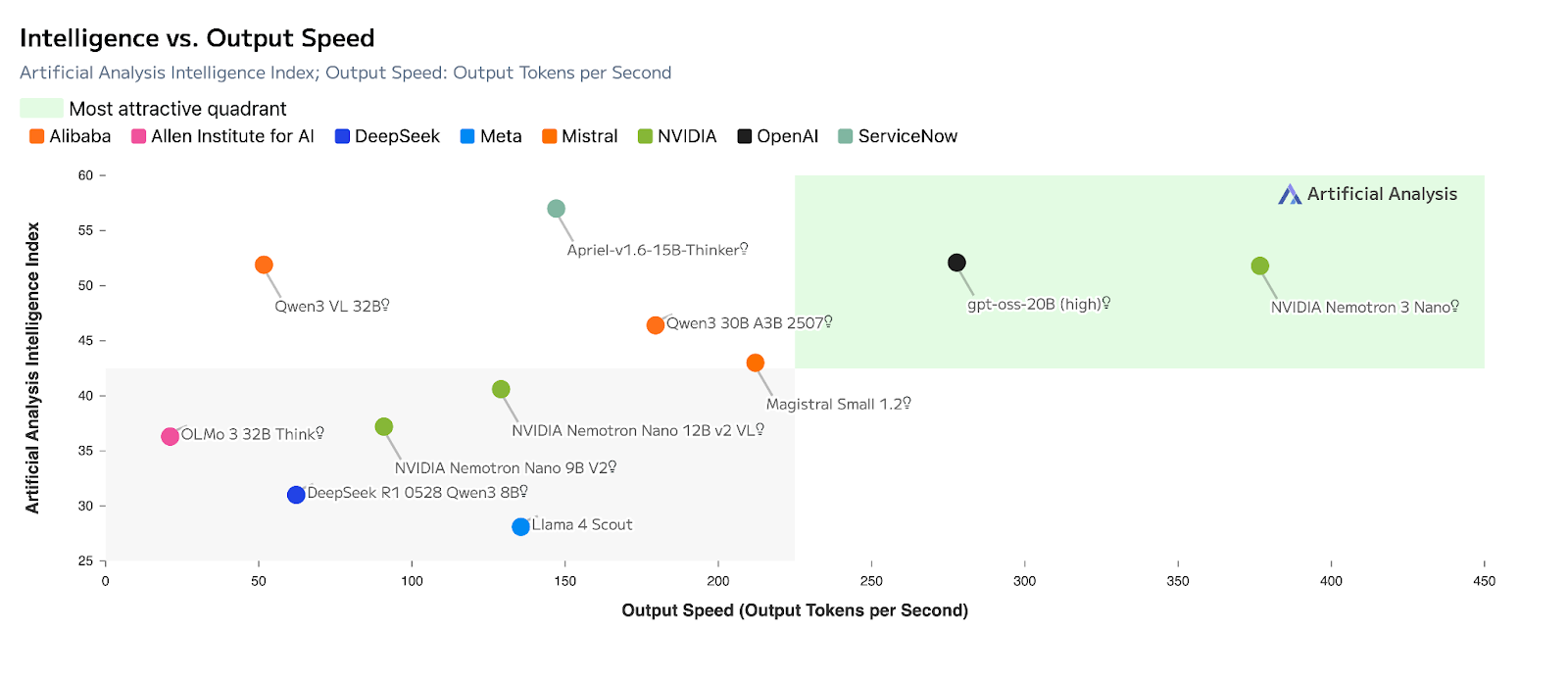
Nvidia ne se cantonne ni aux GPU, ni aux plateformes d’IA. Elle a aussi ses modèles IA. L’entreprise lance la famille Nemotron 3 pour faire tourner des agents, pas juste écrire du texte. Nano débarque avec du débit en hausse, moins de tokens de “raisonnement” et un contexte XXL (jusqu’à 1M), le tout prêt à être emballé en NIM.
En matière de modèles ouverts, on parle souvent de l’Europe (avec Mistral AI) et de la Chine (avec Alibaba, Tencent, DeepSeek ou Kimi), un peu moins des US, terre de l’IA propriétaire. Pourtant IBM (avec Granite), Microsoft (avec Phi), Meta (avec LLama) ou encore Nvidia (avec Nemotron) ou même OpenAI (avec gtp-oss) animent aussi les écosystèmes des modèles en « open-weight ».
Et justement Nvidia, que l’on voir encore trop souvent fournisseur de GPU en oubliant que sa plateforme Enterprise AI (et notamment NIM) sert de socle à toutes les infrastructures IA « clé en main » des fournisseurs IT, vient rappeler à tous que ses modèles Nemotron (qui servent de terrain de jeux à beaucoup d’expérimentation de sa R&D et de celles d’industriels) ne comptent pas pour du beure et qu’ils ont leur place dans les workloads des entreprises.
Des modèles ouverts pour l’ère agentique
Nemotron 3 marque ainsi le retour offensif de Nvidia sur le terrain des modèles ouverts, un espace devenu stratégique pour les DSI qui veulent déployer de l’IA générative sans dépendre entièrement d’API propriétaires.
Avec Nemotron 3, le groupe promet des coûts d’inférence plus bas et davantage de transparence sur les données et outils associés.
Surtout, la nouvelle famille « Nemotron 3 » est présentée comme une famille de modèles orientée IA agentique, autrement dit des systèmes qui enchaînent des actions, des appels d’outils et des sous-tâches plutôt que de simplement produire un texte isolé. Nvidia dit cibler les frictions typiques de ces architectures, notamment la surcharge de coordination entre agents et la dérive du contexte quand les interactions s’allongent.
La gamme est découpée en trois tailles. La variante Nano est annoncée disponible immédiatement. Nvidia affirme que Nano quadruple le débit par rapport à Nemotron 2 Nano. Le modèle revendique aussi une réduction de la génération de jetons de raisonnement, ce qui revient à dire moins de tokens “intermédiaires” à produire pour arriver à la réponse, donc potentiellement moins de latence et moins de coûts selon les tâches.
Enfin, Nvidia annonce une fenêtre de contexte pouvant aller jusqu’à un million de jetons, un argument visant directement l’analyse de documents longs, l’assistance support basée sur de larges bases de connaissance, et la recherche documentaire à l’échelle.
Les variantes Super et Ultra sont annoncées pour le premier semestre 2026.
Sur le plan d’architecture, Nvidia met en avant une approche hybride de type mixture-of-experts, pensée pour limiter le coût de calcul en n’activant pas systématiquement l’ensemble du réseau. C’est une promesse classique des MoE, mais Nvidia la relie ici à l’usage multi-agents, où la facture d’inférence grimpe vite.
Jensen Huang résume la posture avec l’idée que l’innovation en IA dépend de l’ouverture et que Nemotron doit rendre des capacités avancées “utilisables” et “transparentes” pour les développeurs qui construisent des systèmes agentiques en production. Dit autrement, Nvidia veut convaincre que l’open peut être industrialisable, pas seulement expérimental.
Plus d’ouverture annoncée
Sur le plan pratique, Nvidia met en avant un pack complet. En plus des modèles, l’entreprise annonce des jeux de données, dont un ensemble “agentic safety”, et des briques open source pour l’entraînement et l’évaluation, via NeMo Gym et NeMo RL, avec une distribution sur GitHub et Hugging Face.
La promesse d’ouverture ne se juge pas seulement sur les poids du modèle, mais sur l’accès aux artefacts qui permettent audit, fine-tuning, évaluation et garde-fous.
Côté exploitation, Nvidia cite une disponibilité via des canaux et environnements connus des équipes IT. L’entreprise évoque une présence sur AWS via Bedrock en mode serverless, et pousse bien évidemment en parallèle son approche NIM, des microservices pensés pour empaqueter le modèle et accélérer un déploiement maîtrisé. Histoire de faire passer auprès des DSI que le chemin le plus simple pour déployer l’IA est encore de s’aligner sur l’écosystème Nvidia.
Au final, avec Nemotron 3, Nvidia compte imposer une sorte de standard opérationnel pour l’IA agentique, tout en répondant à la demande de contrôle et d’audit de bien des DSI. Reste désormais à mettre ces modèles à l’ouvrage et vérifier leur pertinence sur vos propres cas d’usage. Une pratique que bien des entreprises vont devoir désormais industrialiser tant les modèles évoluent vite et l’offre est pléthorique.

 puis
puis