
Azure passe la seconde. Après avoir récemment lancé son CPU maison de seconde génération « Cobalt 200 », Microsoft a dévoilé cette semaine la seconde génération de son propre accélérateur d’inférence IA : le Maia 200. Et attention, ça décoiffe…
Dans la bataille pour la suprématie de l’infrastructure IA, les hyperscalers ont compris qu’ils ne pouvaient plus dépendre exclusivement d’Intel, AMD et Nvidia. Afin de se libérer des marges et contraintes d’approvisionnement de ces géants des semiconducteurs, les géants du Web trouvent une rentabilité à développer leurs propres puces. Un moyen pour différencier leurs offres, optimiser leurs infrastructures et mettre la pression sur leurs fournisseurs classiques.
Google a ouvert la voie dès 2015 avec ses TPU, dont la septième génération (Ironwood), dévoilée fin 2025, affiche 4,6 PFLOPS en FP8 et alimente désormais plus de 75 % des calculs du modèle Gemini. Amazon a suivi avec la famille Trainium, dont la troisième génération atteint 2,52 PFLOPS en FP8 grâce au procédé 3 nm de TSMC. Dans un même ordre d’idées, AWS a été le premier à fabriquer ses propres CPU avec ses Graviton avant d’être imité par Google et son CPU Axion.
Cette stratégie d’intégration verticale permettrait aux géants du cloud de réduire de 40 à 65 % leur coût total de possession par rapport aux solutions génériques du marché.
Azure a été le dernier à se placer sur ce terrain. L’hyperscaler a dévoilé sa première génération de CPU (Cobalt-100) et d’accélérateur IA (Maia-100) en novembre 2023. Mais ses processeurs n’ont réellement été accessibles aux clients qu’en octobre 2024, Microsoft ayant donné la priorité à ses besoins internes.
En novembre 2025, Microsoft officialisait l’arrivée de son second CPU, le Cobalt 200 une puissante puce ARM dotée de 132 cœurs.
Cette semaine, l’éditeur annonce l’arrivée de sa seconde génération d’accélérateur IA : le Maia-200.
Un accélérateur IA vraiment puissant
Présenté comme l’accélérateur propriétaire le plus performant jamais déployé par un hyperscaler, il est gravé en 3 nm chez TSMC et embarquant plus de 140 milliards de transistors.
Le nouveau silicium maison se distingue par une architecture entièrement repensée pour l’inférence à grande échelle, avec une ambition très explicite, « améliorer l’économie de la génération de jetons ». La bataille de l’IA dans le Cloud ne se limite plus à battre des records bruts mais à livrer faible latence et haut débit, de manière prévisible, au meilleur coût et au meilleur rendement énergétique, dans des datacenters déjà sous tension.
Les chiffres parlent d’eux-mêmes : le Maia 200 délivre plus de 10 PFLOPS en précision 4 bits (FP4) et plus de 5 PFLOPS en 8 bits (FP8), le tout dans une enveloppe thermique de 750 watts. Microsoft revendique des performances FP4 trois fois supérieures à celles du Trainium 3 d’Amazon et une puissance FP8 dépassant le TPU v7 IronWood de Google. Le sous-système mémoire a fait l’objet d’une attention particulière, avec 216 Go de HBM3e offrant une bande passante de 7 To/s, complétés par 272 Mo de SRAM intégrée pour minimiser les allers-retours vers la mémoire externe. Un effort sur la mémoire qui s’explique par une volonté de maintenir les unités de calcul « alimentées » pour améliorer le débit de tokens, là où l’inférence devient vite plus contrainte par le flux de données que par la puissance de calcul.
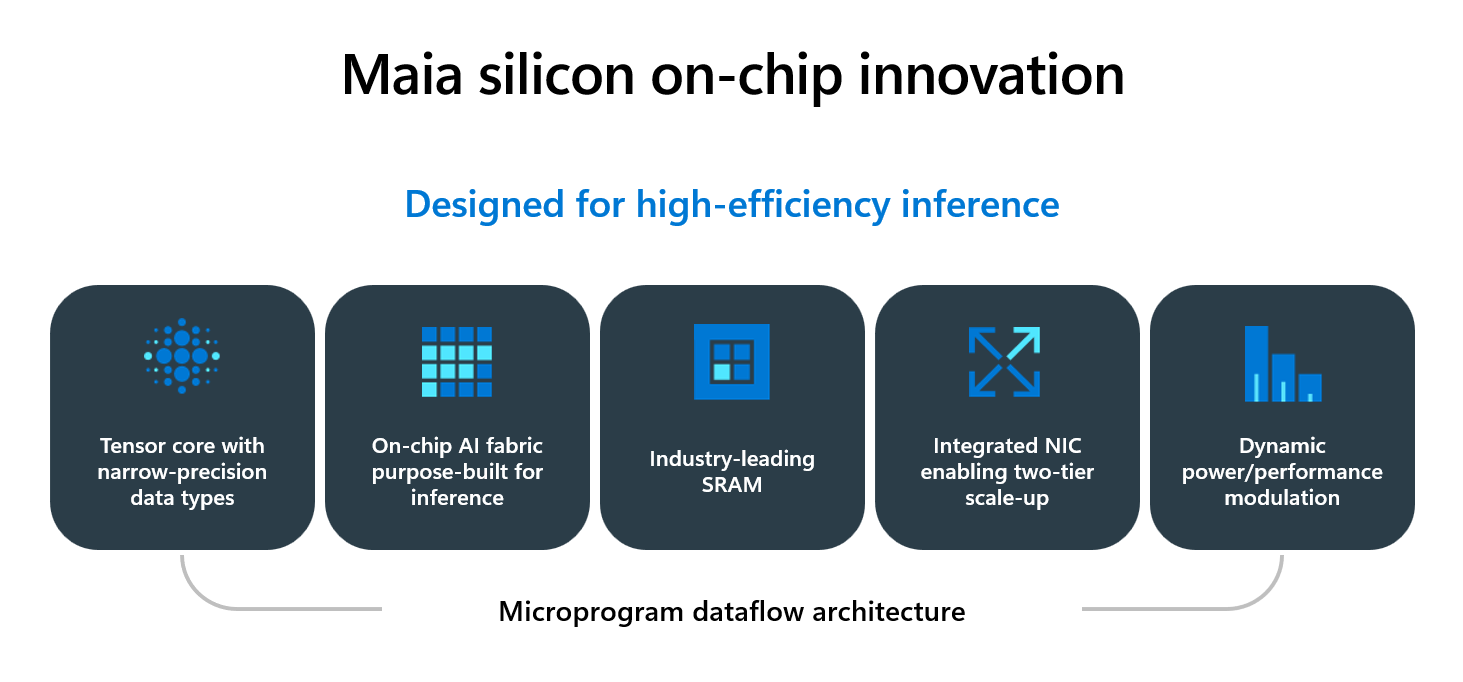
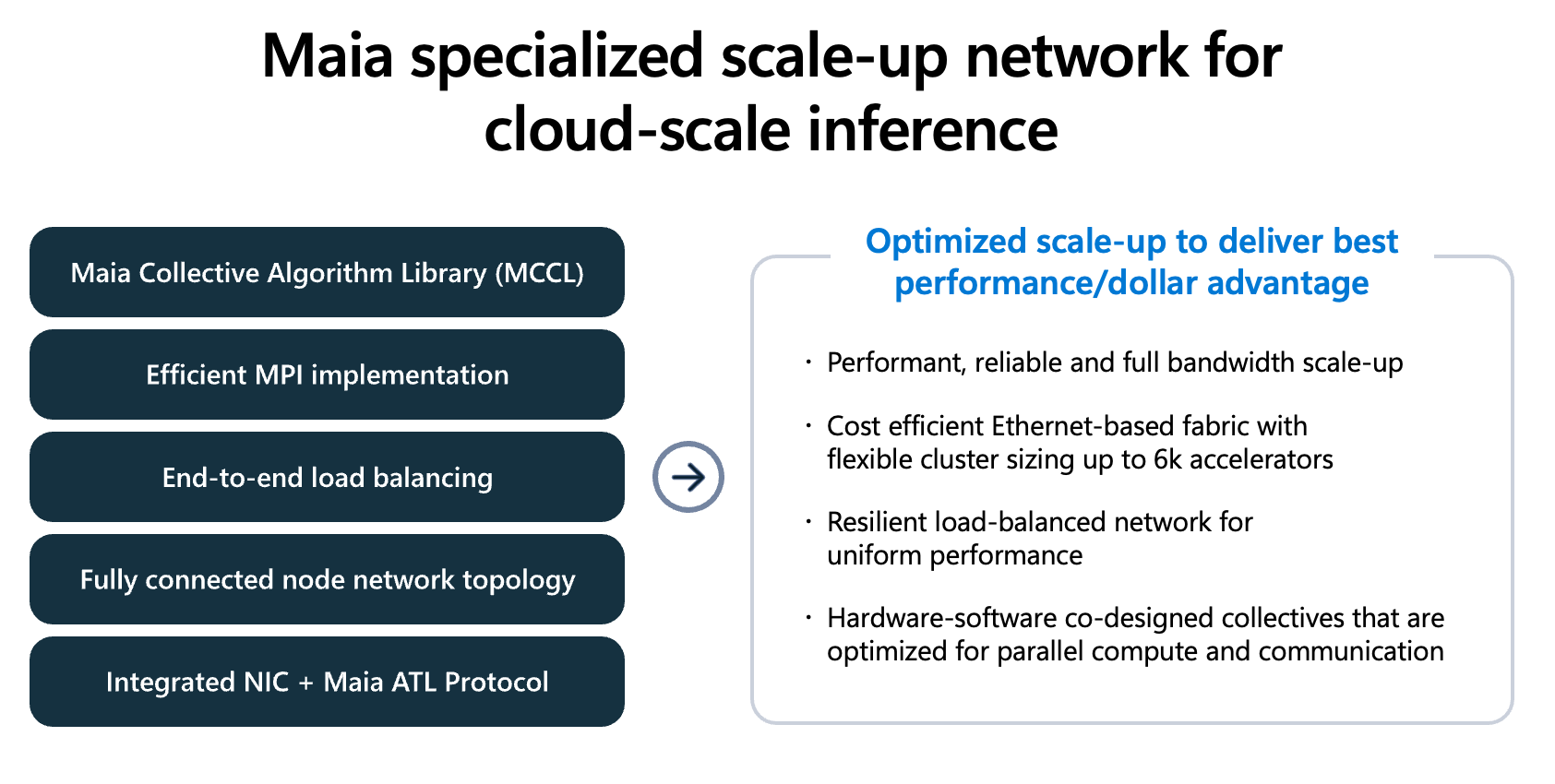
L’interconnexion réseau constitue un autre axe d’innovation majeur. Chaque puce intègre un contrôleur réseau (NIC) capable de gérer 2,8 To/s en bidirectionnel, permettant de relier jusqu’à 6 144 accélérateurs au sein d’un même domaine de calcul sans recourir à des commutateurs propriétaires. Cette architecture à deux niveaux, combinant des liaisons directes entre groupes de quatre puces et un réseau commuté Ethernet standard, vise à optimiser le rapport performance-coût pour les charges d’inférence distribuées.
Longtemps resté discret sur son silicium, Microsoft assume donc désormais les confrontations directes. C’est aussi un message fort envoyé à Nvidia et AMD : « on n’a pas tant besoin que ça de vos accélérateurs, nous aussi on peut être performants ».
Sur le plan opérationnel, les premiers systèmes Maia 200 sont d’ores et déjà déployés dans le datacenter de Microsoft situé près de Des Moines, dans l’Iowa. La région US West 3, près de Phoenix en Arizona, suivra prochainement. Ces infrastructures bénéficient d’un système de refroidissement liquide de seconde génération, conçu pour les racks haute densité.
Le déploiement a déjà massivement commencé
Conçus pour fonctionner dans des architectures hybrides combinant GPU Nvidia et Maia-200, les premiers systèmes dotés du nouvel accélérateur alimentent déjà des travaux de l’équipe Microsoft Superintelligence, accélèrent Microsoft Foundry et soutiennent Copilot, et sont même pris en charge par les derniers modèles GPT-5.2 d’OpenAI dans l’infrastructure hétérogène d’Azure.

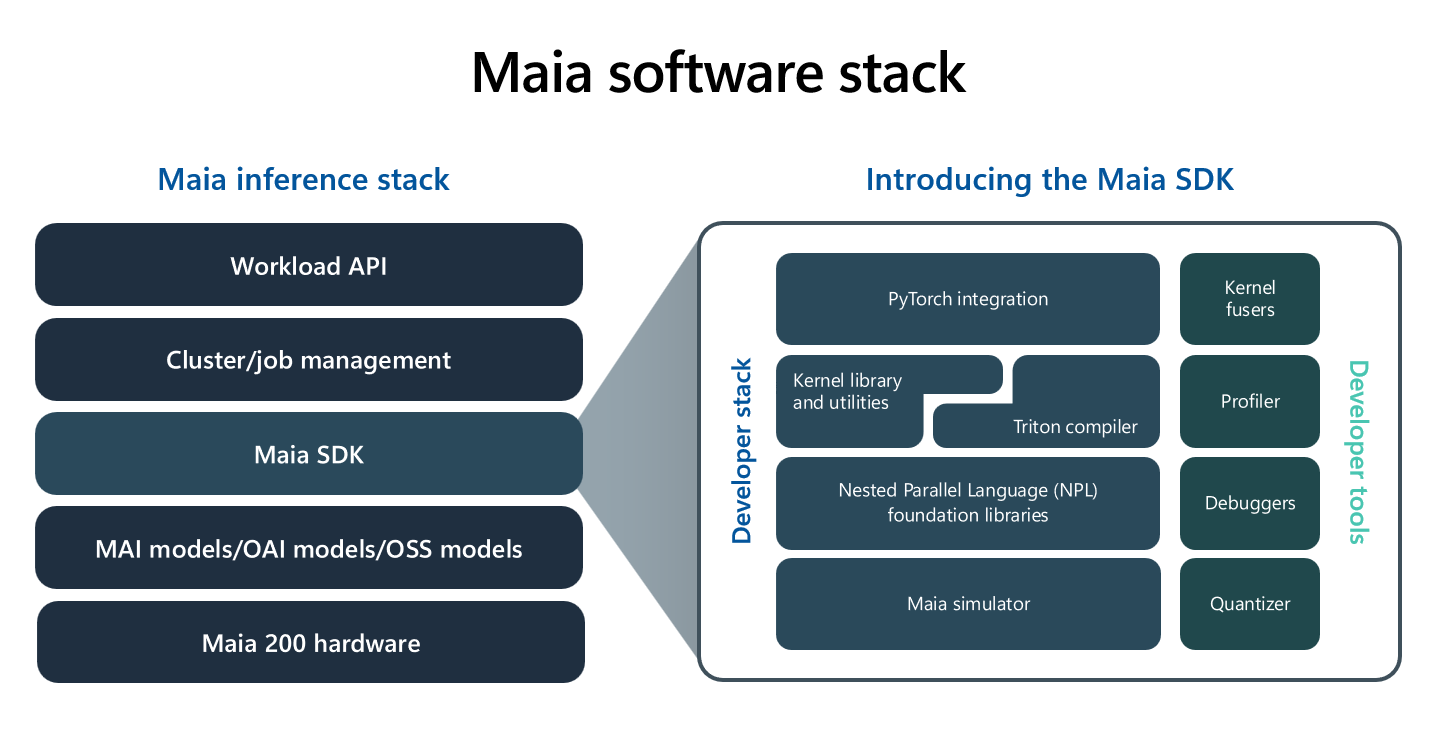
Par ailleurs, Microsoft semble plus décider cette fois à ouvrir ses accélérateurs Maia-200 à ses clients, ce qui n’avait pas été vraiment le cas de la première génération. Pour les développeurs, l’éditeur propose ainsi en preview un kit de développement (SDK) comprenant un compilateur Triton, une intégration PyTorch, des bibliothèques de noyaux optimisés et un accès au langage de programmation bas niveau NPL. L’objectif affiché est de permettre un portage fluide des modèles entre différentes architectures matérielles.
Bref, l’IA reste la grande priorité de Microsoft et d’Azure, et cette puce Maia-200 semble bien partie pour être déployée massivement et mondialement dans les datacenters du groupe.

 puis
puis