
Avec LTAP et Lakehouse//RT, deux annonces phares du « Data + AI Summit 2026 », Databricks s’attaque à une vieille fracture de l’informatique d’entreprise : d’un côté les bases transactionnelles qui font tourner les applications, de l’autre les entrepôts analytiques qui font réfléchir les métiers et alimentent les prises de décision. À l’ère des agents IA, cette séparation ressemble de plus en plus à un ralentisseur posé au milieu de l’autoroute. Un frein historique que Databricks vient enfin de lever.
Pendant quarante ans, les entreprises ont appris à vivre avec deux mondes. Le monde OLTP, rapide, nerveux, critique, où chaque commande, chaque paiement, chaque interaction client doit être enregistré sans trembler. Et le monde OLAP, plus analytique, plus massif, pensé pour les tableaux de bord, les historiques, les requêtes lourdes et les décisions de pilotage.
Entre les deux ? Des pipelines ETL, des copies, des réplicas, des synchronisations CDC, des scripts, des incidents, des coûts cachés et des data engineers qui passent parfois plus de temps à faire circuler la donnée qu’à lui donner du sens. Bref, la plomberie habituelle de la data moderne.
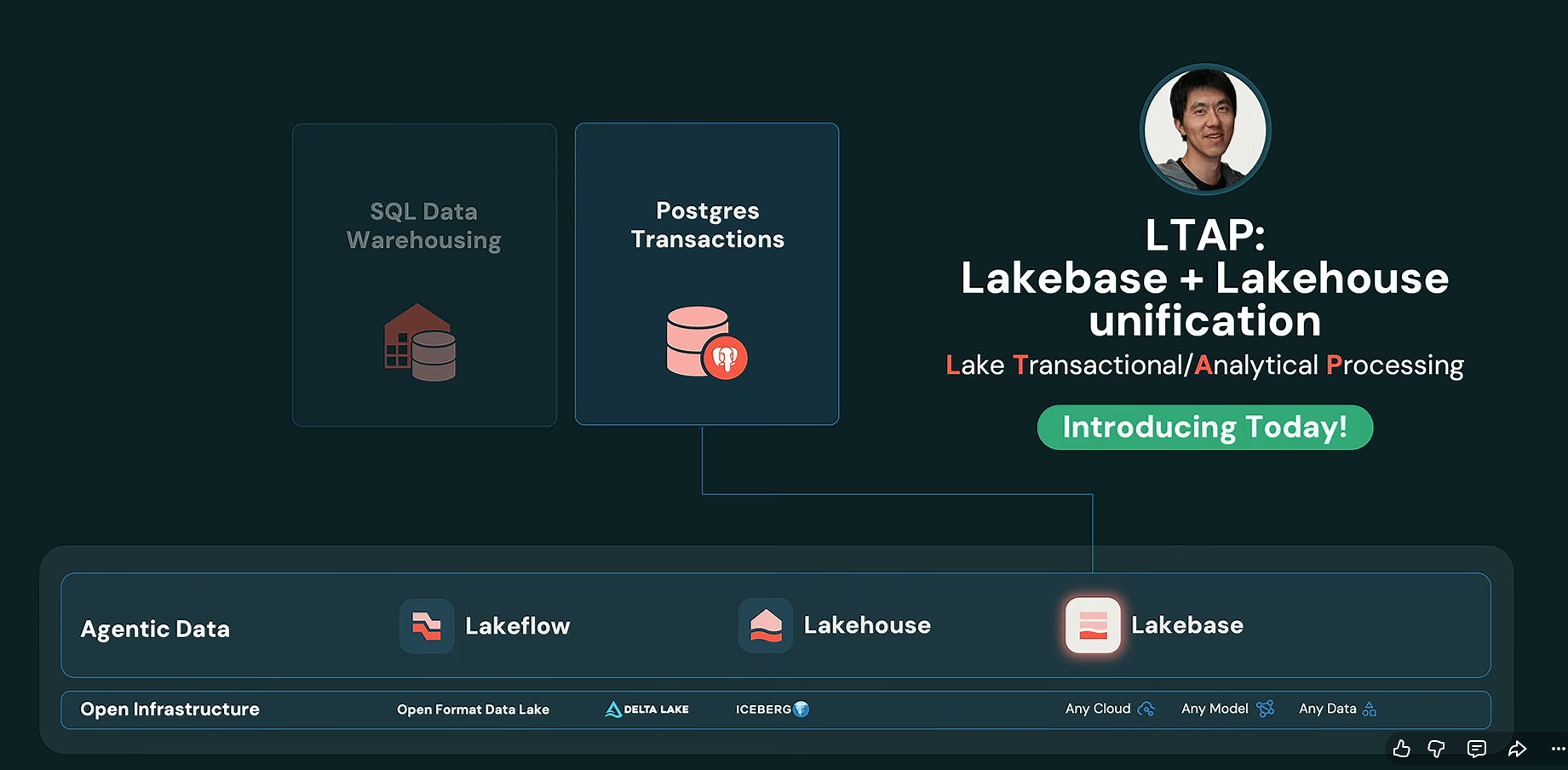
Avec LTAP, pour Lake Transactional/Analytical Processing, Databricks veut faire sauter cette tuyauterie. L’idée est simple à formuler, moins simple à exécuter : réunir transactions, analytics, streaming et données opérationnelles sur une même couche de stockage gouvernée dans le lakehouse demeure une gageure technologique. La promesse : Une seule copie de la donnée, des moteurs différents selon les usages, et une gouvernance commune via Unity Catalog.
LTAP : le lakehouse descend dans le transactionnel
La vraie nouveauté n’est pas seulement de rapprocher OLTP et OLAP. D’autres, avant Databricks, ont tenté l’approche HTAP (Hybrid Transactional/Analytical Processing), souvent au prix de compromis sur la performance, la scalabilité ou l’ouverture.
Mais Databricks choisit une autre voie : ne pas forcer tous les traitements dans un moteur unique, mais unifier la donnée au niveau du stockage.
Là où le HTAP cherche souvent à faire cohabiter transactions et analytics dans une base hybride, le LTAP veut le faire dans une architecture de lakehouse ouverte, gouvernée et pensée pour l’IA.
LTAP est ainsi une architecture de données qui rapproche les traitements transactionnels et analytiques dans le lakehouse afin que les applications, la BI et les agents IA travaillent sur des données plus fraîches, moins dupliquées et mieux gouvernées.
Plus concrètement, Databricks présente LTAP comme une architecture qui unifie OLTP et OLAP dans le lakehouse, avec Lakebase comme couche transactionnelle. Car, dans la vision de Databricks, c’est bien Lakebase qui joue ici le rôle de socle transactionnel. Compatible PostgreSQL, serverless, pensé pour les applications et les agents, la solution apporte les transactions au monde du lakehouse. Les données restent dans des formats ouverts, exploitables par les moteurs analytiques, sans copie intermédiaire. En clair, l’application écrit, l’analytique lit, l’agent raisonne, et tout ce petit monde regarde enfin la même réalité.
C’est évidemment moins glamour qu’un nouveau chatbot agentique, mais pour les DSI, c’est potentiellement bien plus structurant et impactant pour l’architecture générale du SI.
Lakehouse//RT : le temps réel sans usine à gaz
LTAP pose la fondation. Au-dessus de cette dernière, Lakehouse//RT apporte la vitesse. Propulsé par le nouveau moteur Reyden, ce composant vise les usages qui ne supportent plus l’attente : BI interactive, applications analytiques, observabilité, détection de fraude, cybersécurité, supervision industrielle, portails clients ou agents IA qui doivent décider vite.
Jusqu’ici, pour obtenir des réponses en millisecondes, beaucoup d’entreprises ajoutaient une couche spécialisée à côté du lakehouse. Efficace, parfois. Mais coûteuse, redondante, difficile à gouverner et rarement agréable à maintenir. Lakehouse//RT promet de ramener ces workloads temps réel dans l’architecture centrale, directement sur les tables Delta Lake et Apache Iceberg gouvernées.
Autrement dit, Databricks ne veut plus seulement être le lieu où l’on stocke, prépare et analyse la donnée. Il veut devenir l’endroit où l’on agit dessus, en direct.
Pourquoi c’est important maintenant
La bascule vient de l’IA agentique. Un humain peut tolérer un tableau de bord rafraîchi toutes les heures. Un agent qui négocie, recommande, détecte ou automatise un processus métier a besoin de données fraîches, contextualisées et gouvernées. S’il travaille sur des copies retardées, il devient juste très rapide pour prendre de mauvaises décisions.
C’est là que LTAP et Lakehouse//RT se rejoignent. Le premier réduit la distance entre la donnée opérationnelle et analytique. Le second réduit la distance entre la question et la réponse. Ensemble, ils attaquent l’un des grands non-dits de l’IA en entreprise : les modèles sont peut-être impressionnants, mais ils restent dépendants d’infrastructures data souvent lentes, fragmentées et fragiles.
Reste évidemment à éprouver les promesses sur le terrain. Les performances annoncées devront être comparées aux réalités des SI hybrides, des applications legacy, des contraintes réglementaires et des coûts de migration. Mais la direction est claire : Databricks ne vend plus seulement un lakehouse. Il vend une plateforme d’exécution pour entreprises pilotées par les données et, bientôt, par des agents.
La data stack avait besoin d’un bon coup de balai. Databricks, ne fait pas dans la dentelle et sort carrément un aspirateur industriel pour nettoyer quarante années de tuyauteries ETL, de copies de données, de silos transactionnels et de couches temps réel bricolées à la périphérie du SI..
____________________________

 puis
puis