
Avec IronWood, Google Cloud signe une rupture technologique et stratégique dans l’architecture des accélérateurs IA. Conçu pour l’inférence à très grande échelle, ce TPU de septième génération conjugue puissance de calcul, efficience énergétique et intégration logicielle au sein de l’AI Hypercomputer. Une avancée qui redéfinit les performances du cloud d’inférence et met une forte pression sur la concurrence.
Depuis plus d’une décennie, les Tensor Processing Units (TPU) de Google irriguent les charges d’entraînement et de service de ses modèles IA phares, avant d’être proposés aux clients via Google Cloud et Gemini. Ils sont au cœur des avancées technologiques de Google AI et Google Deepmind telles que les Transformers. Les TPU ont servi à entraîner et assurent aujourd’hui l’inférence de Gemini, Veo, Imagen et même des modèles Claude d’Anthropic.
Et désormais, Google Cloud enfonce l’accélérateur. L’hyperscaler annonce la disponibilité de sa toute dernière génération de TPU, « IronWood », dévoilée en mai dernier à l’occasion de Google Cloud NEXT 2025 et jusqu’ici réservée aux usages internes de Deepmind et Google.
IronWood, un TPU pensé pour l’âge de l’inférence
IronWood est la septième génération de TPU et la première explicitement conçue pour l’inférence à très grande échelle. Chaque puce atteint un pic de 4 614 TFLOPS en FP8 et embarque 192 Go de mémoire vive HBM3e avec une bande passante mémoire de 7,37 To/s.
Google annonce surtout un doublement de la « performance par watt » par rapport au Trillium (TPU v6e) et près de 30× d’efficacité énergétique en plus versus le premier Cloud TPU de 2018.
Dit autrement non seulement IronWood est plus efficient et économe en énergie que les précédents TPU mais il est aussi terriblement plus performant comme le résume le graphique ci-dessous :
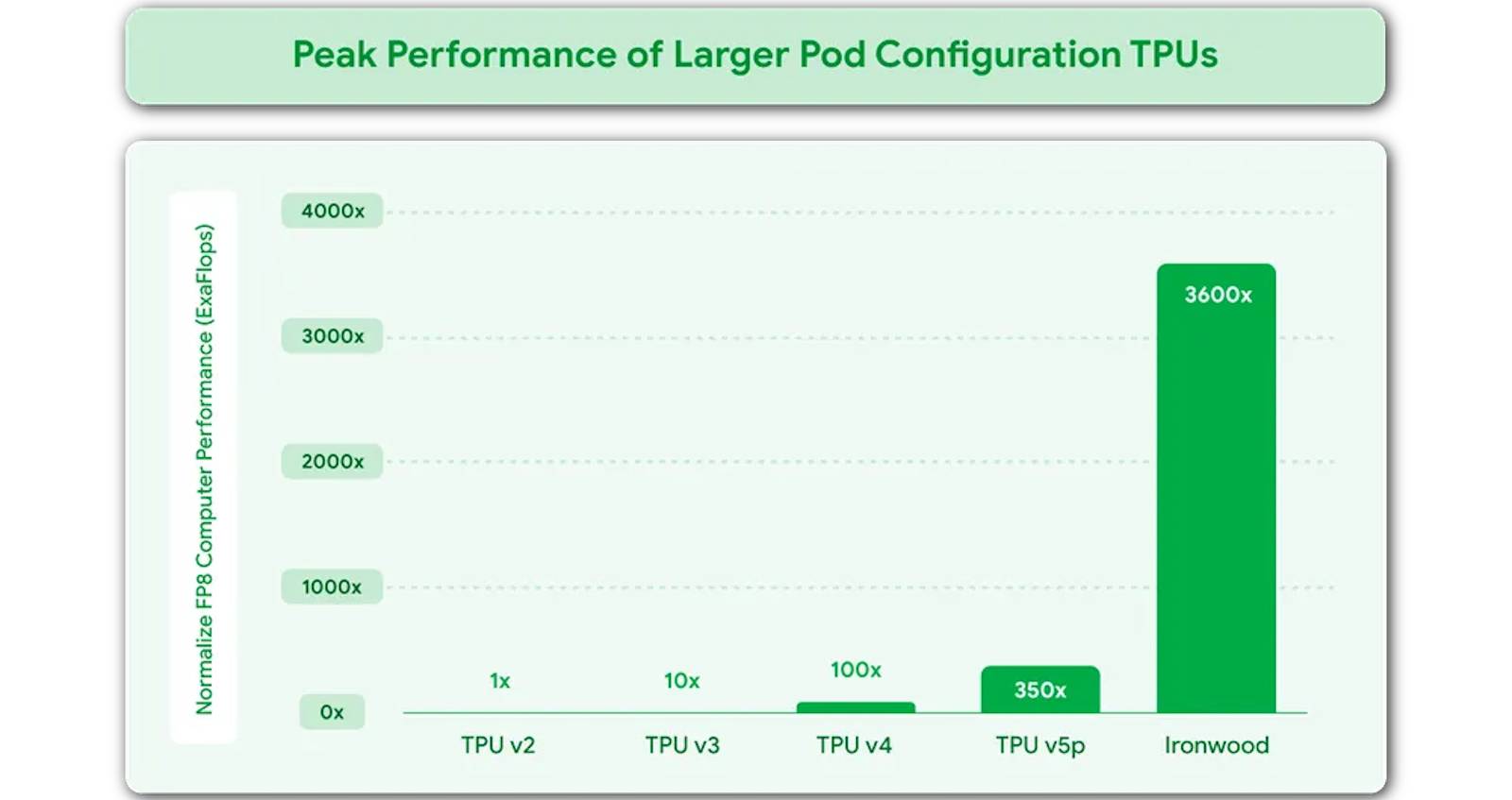
Toute la conception du IronWood vise ainsi à minimiser les mouvements de données et la latence au sein de la puce, tout en soutenant des communications synchrones à l’échelle d’un cluster complet pour assurer l’inférence à très grande échelle des “modèles pensants” comme Gemini 2.5 Pro. « Ironwood est notre TPU le plus puissant, le plus capable et le plus efficient, taillé pour des modèles qui pensent et infèrent à l’échelle » explique ainsi Google.
Les TPU Pods IronWood explosent les frontières
Mais chez Google, la puce TPU n’est qu’une partie de la magie. Elle n’est jamais exploitée seule mais au sein de ce que les ingénieurs de Google Cloud nomme un « TPU POD ». C’est un rack hébergeant une immense grappe d’accélérateurs TPU. Et chaque nouvelle génération de TPU donne naissance à une nouvelle génération de Pods !
Ainsi, un pod Ironwood assemble jusqu’à 9 216 puces IronWood (il existe une version mini-POD de 256 puces) en un domaine de calcul partagé avec 1,77 Po de mémoire vive HBM3e s’appuyant sur une interconnexion « maison » dénommée Inter‑Chip Interconnect (ICI) qui offre une bande passante de 9,6 Tb/s agrégés au niveau du pod. L’architecture en tore 3D relie les puces via ICI pour former un “grand système” où le débit inter‑puce et la mémoire vue quasi‑partagée limitent les goulots d’étranglement.
Il résulte d’un tel assemblage une performance d’inférence encore jamais vue. Un seul Pod IronWood procure une performance de 42,5 ExaFLOPS en FP8.
A titre de comparaison, le rack NVL72 en GB300 de Nvidia ne dépasse pas les 0,36 ExaFLOPS !
AI Hypercomputer : l’assemblage au‑delà des pods
Ironwood est également destiné à devenir prochainement le moteur de l’AI Hypercomputer, la plateforme unifiée de Google qui agrège calcul, stockage, réseau et logiciel sous une seule couche de gestion, et qui peut combiner des pods en clusters de centaines de milliers de TPU. Cette plateforme est bien plus qu’un giga-cluster de Pods et TPU. C’est une plateforme complète où le matériel et le logiciel sont conçus ensemble. Elle repose d’une part sur des Pods IronWood mais aussi des GPU Nvidia et d’autre part sur une architecture logicielle composée de multiples briques complémentaires. Le logiciel Pathways permet de répartir les calculs sur des milliers de puces en même temps. L’outil MaxText aide à ajuster les modèles de langage (fine‑tuning) ou à les entraîner par essai‑erreur (reinforcement learning, RL). Lz moteur vLLM est ici spécialisé pour faire tourner les grands modèles de langage de façon optimale sur les Pods IronWood. Enfin, la GKE Inference Gateway optimise la manière dont les requêtes sont traitées sur cet assemblage complexe qu’est un AI Hypercomputer. Cette dernière réduit le temps d’attente avant la première réponse (TTFT, time to first token) de près de 96 % et diminue les coûts de service d’environ 30 %. Autrement dit, les utilisateurs obtiennent des réponses plus vite et les entreprises paient moins cher pour les produire.
Selon IDC, l’adoption d’un AI Hypercomputer en IronWood offre un ROI moyen à trois ans de 353 %, 28 % de baisse des dépenses IT et 55 % d’efficacité opérationnelle en plus pour les clients.
La valeur de l’Hypercomputer tient à la continuité de bout en bout : les CPU Axion (Armv9) orchestrent ingestion et APIs, les GPU Nvidia complètent les calculs d’entrainement selon les besoins logiciels, et les pods TPU assurent l’inférence “gros débit”, le tout sous une fabric optique reconfigurable et une pile managée pour des SLO tenables.
Au final, cette disponibilité d’IronWood met une forte pression sur la concurrence (AWS avec ses puces Inferencia2 et Azure avec ses Maia-100) mais aussi sur le leader des puces IA, Nvidia. Google envoie aussi un signal clair au marché rappelant que l’inférence à très grande échelle est le nerf de la guerre et que son cloud est désormais super-armé en la matière. Les enjeux économiques et opérationnels sont majeurs. Réduire le coût par requête est désormais une préoccupation majeure chez tous les DSI… et toutes les startups de l’IA. Anthropic vient d’ailleurs de réserver l’accès jusqu’à 1 million de TPU pour assurer ses besoins d’inférence de Claude AI.

 puis
puis