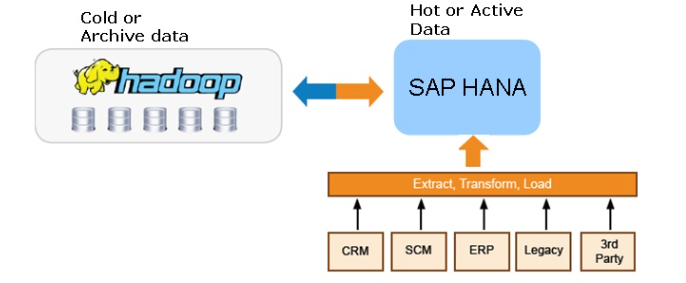
SAP HANA Vora, annoncé ce matin, est un moteur de requête en mémoire pour Hadoop et Spark.
Pour les ingénieurs allemands, cela devrait en tous cas démocratiser l’accès aux données scientifiques et améliorer l’analyse de type OLAP sur des données Hadoop. La passerelle converse avec l’outil Spark d’Apache qui génère des requêtes dans des données non structurées, mais pour SAP, l’objectif de Vora n’est pas de remplacer Spark. Vora doit permettre d’analyser de gros volumes de données dans certains secteurs « dans le contexte des processus financiers, celui les télécommunications, des soins de santé et de la fabrication de produits manufacturés. »
Spark et Hadoop seront valorisés
En tous cas, face à la multiplication des informations provenant de capteurs dans le monde de l’Internet des objets et des lacs de données, les « datalakes », Vora qui sera disponible en version cloud et sur site devrait permettre de consolider des informations « brutes ». En les convertissant dans l’univers très structuré de la gestion commerciale et la facturation, l’opération de transformation sera appréciée.
Dans les chaînes de fabrication d’automobiles où SAP règne en maître, doubler les informations officielles d’avancement des véhicules par des informations provenant de milliers capteurs sur le terrain, dans la chaine, permettra, par exemple, de mieux rapprocher le monde des informations comptables automatisées de celui de la production réelle. Pour la firme allemande, l’intérêt de ce moteur sera d’utiliser la puissance du « In memory » pour analyser les données stockées dans Hadoop et prendre des décisions plus précises. Le système serait bijectif et l’on peut imaginer qu’une analyse économique effectuée dans SAP pourra« Remonter » dans les processus et augmenter ou interrompre automatiquement des processus de traitement coûteux.
L’ouverture à l’Open source, une mesure lancée doucement, il y a déjà longtemps
Pour les passionnés de l’Open Source, il s’agit d’une simple pompe de données pour valoriser les outils payants d’analyse de SAP avec les outils provenant d’une communauté qui elle ne vend rien, mais donne ses logiciels, pour le seul bonheur de ses intégrateurs.
Le nom Vora a été choisi, selon notre interlocuteur, parce » qu’il est à la racine latine du mot « vorace », et que le logiciel Vora peut consommer de grandes quantités de données. Cela fera sourire tous ceux qui suivent de prés les prix des licences logicielles et en particulier le service informatique d’Unilever. Celle-ci fait tourner prés de 250 ERP dans ses usines et pilote l’usine française de moutarde Savora.
Cette passerelle n’est pas, à notre avis, un luxe car elle permettra d’endiguer la progression d’autres approches. En offrant une solution de passerelles intermédiaire entre logiciel payant et gratuit, SAP réduit le risque de voir certains clients étudier de près des solutions complètement gratuites d’un point de vue licences et qui remettraient à terme en cause tout l’existant SAP. Dés 2010 , SAP avait mis les pieds dans Eclipse et dans les outils Hadoop via l’outil Sybase et ses services de fichiers mais toujours dans une optique de centralisation des données et des opérations vers ses produits.
Ci-dessous une présentation issue du blog de SAP
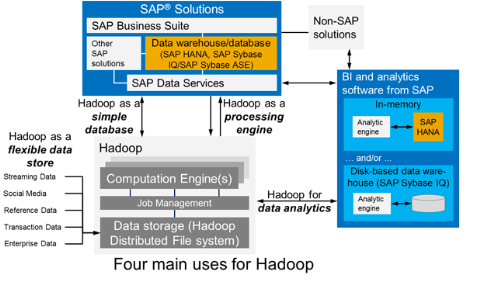
Trois projets open source soutenus par SAP
En juillet dernier, lors d’une conférence open source aux États-Unis, changement d’approche, SAP a annoncé qu’il était devenu l’un des sponsors de deux communautés open source clés : la plate-forme-as-a-service de Cloud Foundry initiée par Pivotal, et la Fondation OpenStack. Chez SAP, la notion d’Open Source est pou le moins très limitée. Elle donne une partie du support pour sa base de données SAP HANA en mémoire de ces deux plates-formes, même dans la passerelle VORA, ce sont les API qui sont décrites, mais l’ensemble reste payant.
SAP dispose d’un troisième projet open source, OpenUI5, une importante bibliothèque JavaScript UI commue sous le nom SAPUI5. Le code est disponible sur le Site sur GitHub. De son côté, la communauté Open source avait déjà repéré le créneau d’interface pour exploiter les données issues de SAP. Talend propose depuis plusieurs années pour nourrir son ETL des liens via les protocoles BAPI et RFC. Autre amateur de données issues de SAP, Palo connue pour ses cubes multimensionnels aptes à malaxer les données pour en faire des tableaux de bord. Mais que ce soit pour l’un ou l’autre, ce marché de l’extraction de données depuis SAP reste faible, il faut dire. Mais le mouvement inverse sera peut être plus lucratif.
on ne change pas les logiciels qui font tourner des structures importantes
Que la prudence des clients SAP soit légendaire n’est pas une légende puisque pour uniquement pour l’adoption de la base de données HANA le bureau d’étude Gartner prévoit que seulement 35 % des clients SAP utiliseront l’outil Hana d’ici 2020 à la place de leurs SGBD Oracle ou SQL Server. Et pourtant les prix des licences HANA sont beaucoup plus intéressantes. Pour le spécialiste SAP du bureau d’étude, la plupart des clients attend simplement d’être convaincu que la base de données HANA soit suffisamment fiable pour gérer leurs données les plus vitales. Du coup, on imagine la quasi-indifférence portée par les clients pour un produit ouvert « aux bugs de l’Open source ». A priori, le produit sera surtout le bienvenu dans les entreprises ou les silos de données existent déjà et où les outils analyses au sein des outils SAP, bien connus pourront être facilement ré exploités
SAP a également annoncé aux États-Unis un nouvel ensemble de services de micro entreprises basés sur le cloud, y compris les forfaits de marketing client et un service de fonctions qui calcule automatiquement les taxes locales dans le monde entier. Un outil qui devrait être apprécié dans l’Hexagone, leader dans ce domaine.
La solution SAP HANA Vora sera proposée à la fin septembre avec trois options de licences, qui vont d’une édition gratuite de développeur à une version entreprise avec le support de SAP.

 puis
puis