
Six semaines seulement après la sortie de GPT-5.4 et à peine une semaine après celle de Claude Opus 4.7 chez Anthropic, OpenAI annonce ses nouveaux modèles frontières GPT-5.5 Thinking et GPT-5.5 Pro. Le nouveau modèle phare s’impose sur 14 benchmarks et se révèle même plus performant que le fameux « Mythos Preview » d’Anthropic sur certains ! Avec GPT-5.5, OpenAI reprend provisoirement la tête du peloton public et pose la première pierre de son futur « super applicatif » unifié.
La rivalité entre OpenAI et Anthropic a pris, cette année, des allures de course-poursuite à haute intensité. Pas un mois ne passe sans qu’un modèle frontière ne soit annoncé par l’un ou l’autre des protagonistes. Anthropic a méthodiquement pris le dessus sur le segment des entreprises avec Claude Opus 4.6, puis a enfoncé le clou il y a tout juste une semaine avec Opus 4.7, considéré par plusieurs analystes comme la référence pour le développement logiciel, l’écriture de textes et les tâches de raisonnement approfondi. Dans la foulée, la jeune pousse de San Francisco a également présenté Claude Mythos Preview, un modèle encore plus puissant mais volontairement gardé sous clé en raison de ses capacités offensives en cybersécurité, et réservé à la coalition Project Glasswing qui regroupe une poignée de géants technologiques et financiers.
Pour OpenAI, la situation devenait franchement inconfortable. En interne, l’éditeur de ChatGPT aurait même basculé en état de « Code Red » depuis décembre 2025 pour tenter de recoller à son concurrent. La sortie de GPT-5.5, à peine six semaines après GPT-5.4 et une semaine jour pour jour après Opus 4.7, n’a donc rien d’un hasard de calendrier. Elle résulte de cet effort pour redevenir la référence.
Une série GPT-5 qui a fait grincer des dents
Il faut dire que la saga GPT-5 n’a pas été un long fleuve tranquille. Le lancement initial de GPT-5, à l’été 2025, avait viré au cauchemar de communication. Sam Altman lui-même avait reconnu publiquement que son entreprise avait « totalement raté » le déploiement : routeur automatique capricieux entre sous-modèles, réponses parfois incohérentes, personnalité jugée froide et mécanique par les utilisateurs historiques de GPT-4o, et une telle vague de protestations qu’OpenAI avait dû réactiver l’ancien modèle en urgence. Les itérations suivantes – GPT-5.1, GPT-5.2 puis GPT-5.3 – ont permis de recoller les morceaux en travaillant sur le raisonnement adaptatif et la stabilité en usage agentique, sans pour autant permettre à OpenAI de refaire la course en tête.
C’est GPT-5.4, sorti début mars, qui avait amorcé une vraie inflexion : personnalité et expression plus agréables, raisonnement multi-étapes plus fiable, meilleure adhérence aux instructions, premières capacités de pilotage d’ordinateur et surtout une persistance accrue sur les tâches longues. Suffisant pour rester dans la course face à Gemini 3.1 Pro et Claude Opus 4.6, mais pas forcément pour reprendre la couronne sur les benchmarks et sur les cas d’usage d’entreprise.
Alors OpenAI maintient la cadence et continue d’oeuvrer à reprendre un lead incontestable. D’où cette sortie précipitée de GPT-5.5 à peine six semaines plus tard.
« Spud », le modèle qui ne veut surtout pas être une patate
Le nom de code interne de GPT-5.5, amuse la presse américaine : « Spud », soit « patate » en argot anglais. Derrière le sobriquet potager se cache en réalité une refonte d’ampleur : selon plusieurs observateurs, il s’agirait du premier modèle entièrement réentraîné depuis GPT-4.5, et non d’un simple ajustement post-entraînement.
Greg Brockman, président et cofondateur d’OpenAI, a planté le décor lors de la conférence de presse : « Ce modèle constitue une véritable avancée vers le type d’informatique que nous attendons pour l’avenir, mais ce n’est qu’une étape parmi beaucoup d’autres que nous anticipons. C’est un penseur plus rapide et plus affûté, pour moins de jetons consommés comparé à GPT-5.4. Cela signifie qu’il y a tout simplement davantage d’intelligence frontière à disposition des entreprises comme des particuliers, ce qui fait partie de nos objectifs. »
Plus loin dans le même échange avec les journalistes, le dirigeant a résumé la philosophie du modèle dans une formule qui claque : « Ce qui rend vraiment ce modèle spécial, c’est tout ce qu’il peut accomplir avec moins de guidage. Il sait regarder un problème flou et déterminer ce qui doit se passer ensuite. »
Un modèle pensé pour l’autonomie, pas pour la conversation
OpenAI n’en fait pas mystère : GPT-5.5 est vendu comme le socle des futurs agents d’entreprise. La promesse tient dans une phrase que l’éditeur martèle dans sa communication officielle : « Au lieu de piloter soigneusement chaque étape, vous pouvez confier à GPT-5.5 une tâche confuse et à multiples facettes, et lui faire confiance pour planifier, utiliser des outils, vérifier son travail, naviguer dans l’ambiguïté et poursuivre jusqu’au bout. »
Autrement dit, OpenAI ne vend plus un agent conversationnel, mais une machine à boucler des tâches. D’ailleurs, selon nos premiers tests, GPT 5.5 progresse peu dans la fluidité de son expression et reste plutôt derrière Opus 4.7, tout au moins sur l’expression en Français.
Les domaines cibles de cette nouvelle mouture sont ailleurs et clairement énoncés par l’éditeur : analyse de données, écriture et correction de code, pilotage d’applicatifs bureautiques, recherche en ligne, production de documents et de tableurs.
Mark Chen, directeur scientifique d’OpenAI, a insisté sur les usages les plus pointus : le modèle « montre des progrès significatifs sur les flux de travail de recherche scientifique et technique » et pourrait, selon lui, « aider de véritables experts scientifiques à faire progresser leurs travaux », notamment dans le domaine de la découverte de médicaments.
Les retours de testeurs vont dans le même sens. Dan Shipper, fondateur d’Every, le qualifie de « premier modèle de développement logiciel que j’aie utilisé qui possède une véritable clarté conceptuelle » et témoigne : « J’ai réellement l’impression de travailler avec une intelligence supérieure, avec presque un sentiment de respect. »
Un ingénieur de NVIDIA bénéficiant d’un accès anticipé va encore plus loin : « Perdre l’accès à GPT-5.5, c’est comme se faire amputer d’un membre. »
Bien sûr tout ceci n’est que de la Comm’ mais on voit se dessiner derrière ces impressions les axes de progression de cette itération.
Des benchmarks qui remettent OpenAI sur le trône… public
Côté évaluations, le retour d’OpenAI en tête des classements est spectaculaire. Selon les chiffres publiés par OpenAI, GPT-5.5 affiche l’état de l’art sur quatorze tests tiers, contre quatre seulement pour Opus 4.7 et deux pour Gemini 3.1 Pro.
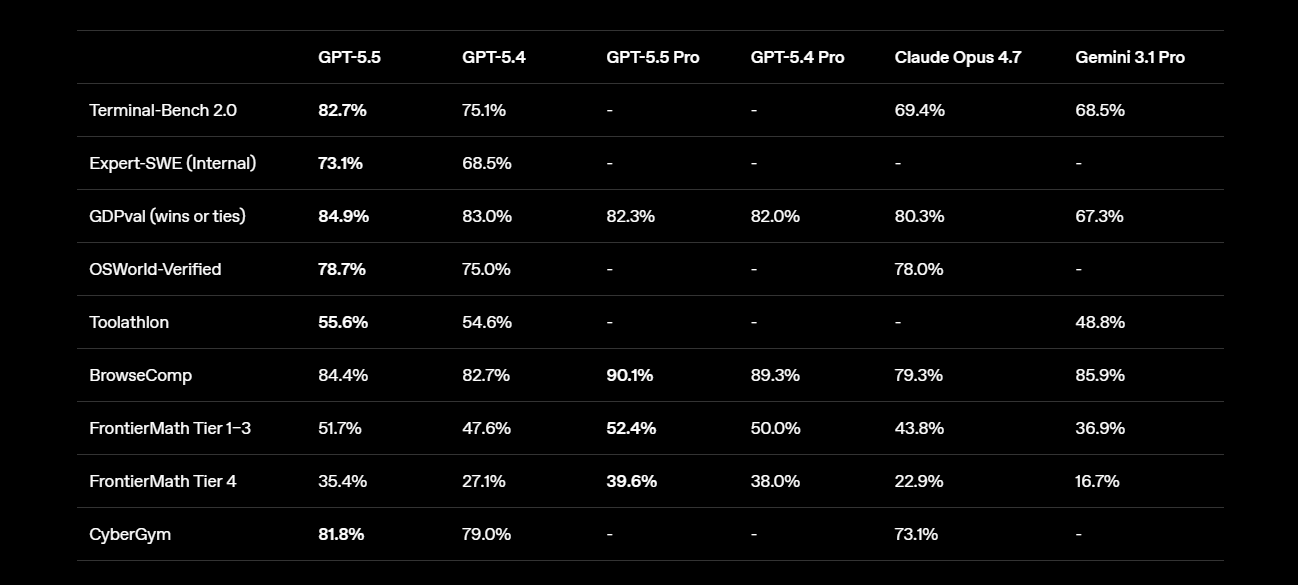
Le chiffre le plus spectaculaire ?: 82,7 % de réussite sur Terminal-Bench 2.0, le bench qui mesure la capacité d’un modèle à mener à bien des tâches complexes dans un environnement terminal. Opus 4.7 plafonne à 69,4 % sur le même test, et même le très confidentiel Claude Mythos Preview est coiffé d’un cheveu (82 %).
Sur GDPval, qui évalue la production d’un travail intellectuel qualifié dans 44 métiers, GPT-5.5 grimpe à 84,9 %.
Sur OSWorld-Verified, qui teste l’usage autonome d’un ordinateur, il atteint 78,7 %.
Sur FrontierMath enfin, il culmine à 51,7 %.
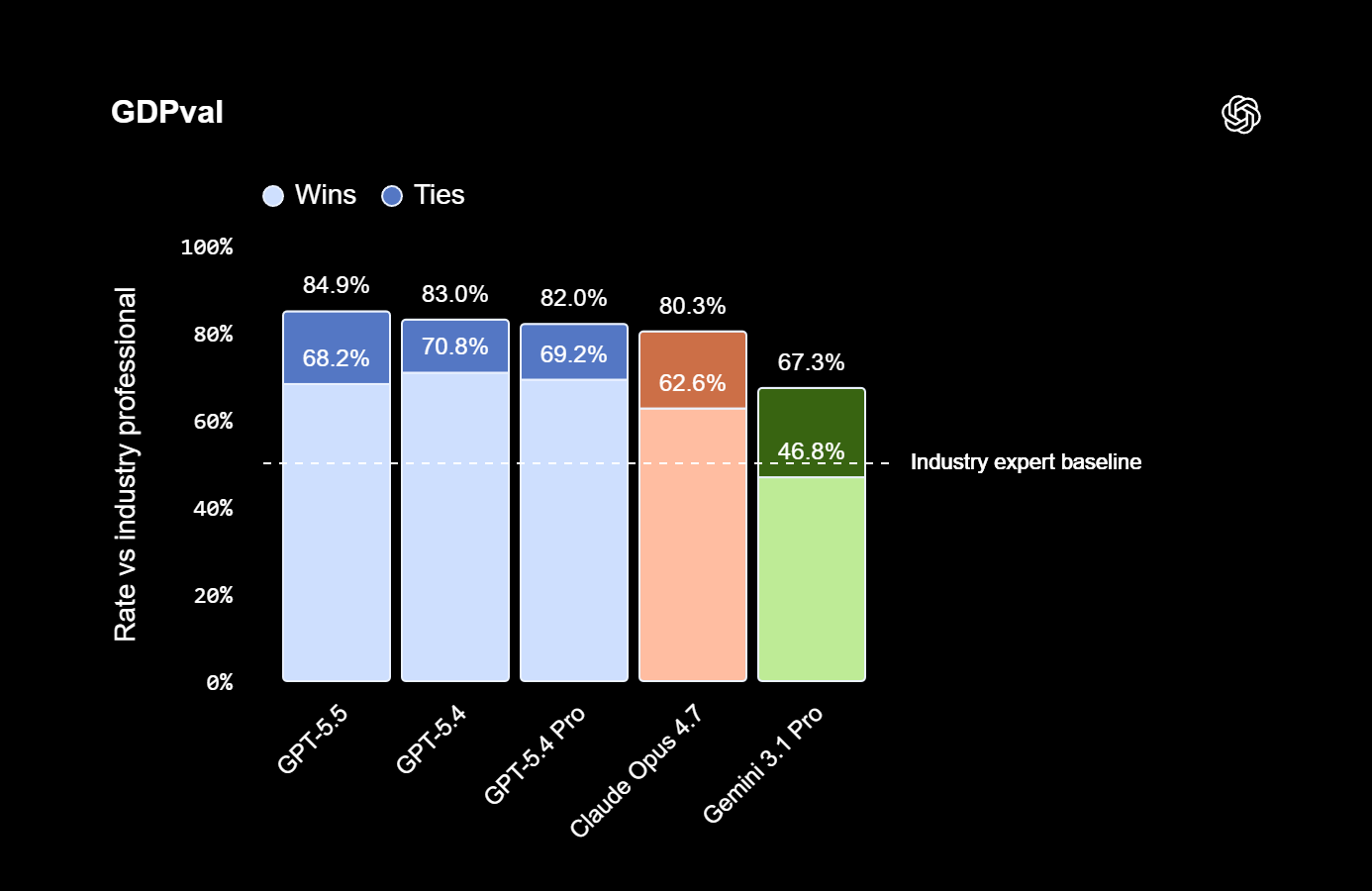
OpenAI reprend largement la tête sur les benchmarks les plus réputés. Ce qui ne veut pas dire qu’il en sera de même sur vos usages et vos contextes. D’autant que les choses sont un plus nuancées dans le détail. Opus 4.7 conserve l’avantage sur SWE-bench Pro, l’épreuve reine de la résolution de tickets GitHub, ainsi que sur certains exercices de raisonnement sans outils comme Humanity’s Last Exam. Et Mythos Preview, lorsqu’on le sort de son placard, reste devant sur la majorité des évaluations où les comparaisons sont possibles.
Mia Glaese, vice-présidente de la recherche chez OpenAI, préfère d’ailleurs rester sobre : « C’est incontestablement notre modèle le plus performant à ce jour sur le développement logiciel, qu’on se fie aux tests ou aux retours de nos partenaires de confiance, ainsi qu’à notre propre expérience. »
La cybersécurité, terrain miné
Sur le terrain sensible de la cybersécurité, OpenAI marche sur des œufs. GPT-5.5 atteint le niveau « High » du cadre de préparation de l’éditeur, ce qui signifie qu’il peut amplifier des menaces existantes s’il tombait en de mauvaises mains, sans pour autant franchir le seuil « Critical » qui ouvrirait la voie à des capacités totalement inédites.
« GPT-5.5 a fait l’objet de tests tiers approfondis de nos dispositifs de sécurité et d’exercices d’équipes rouges concentrés sur les risques cyber et biologiques, et nous itérons depuis plusieurs mois sur nos garde-fous à mesure que nos modèles deviennent plus capables dans ce domaine », explique Mia Glaese.
L’éditeur profite du lancement pour élargir son programme Trusted Access for Cyber, qui donne aux défenseurs vérifiés, éditeurs de sécurité, opérateurs d’infrastructures critiques, agences gouvernementales, un accès à des variantes moins bridées comme GPT-5.4-Cyber. Un écho assumé au débat ouvert par Anthropic autour de Mythos et de son Project Glasswing.
La « super app » et Microsoft Foundry : le vrai cap stratégique
La sortie de GPT-5.5 s’inscrit dans un plan plus vaste. Greg Brockman l’a réaffirmé : ce modèle doit servir de socle à la future « super app » d’OpenAI, une application unifiée combinant ChatGPT, l’agent de développement Codex et un navigateur agent sous une même session, lancée dans une première mouture le 16 avril dernier mais qui attendait son moteur définitif. Sam Altman aurait lui-même confié à ses équipes que le modèle pourrait « réellement accélérer l’économie ».
Côté Microsoft, GPT-5.5 sera disponible dans Microsoft Foundry dès aujourdh’ui. Le billet officiel d’Azure positionne cette arrivée dans la continuité de la série : « GPT-5.5 fait progresser cette trajectoire avec un raisonnement plus profond sur les contextes longs, une exécution agentique plus fiable, une précision accrue du pilotage d’ordinateur et une meilleure efficacité en nombre de jetons — conçu pour des flux de travail professionnels soutenus et à enjeu élevé. » Combiner ce modèle frontière avec une plateforme de gouvernance d’entreprise doit permettre aux DSI de mettre enfin l’IA agentique en production sans avoir à réinventer leurs contrôles de sécurité et de conformité.
Disponibilité : d’abord ChatGPT et Codex, ensuite l’API
Le déploiement de GPT-5.5 démarre immédiatement pour les abonnés payants de ChatGPT : les formules Plus, Pro, Business et Enterprise accèdent à GPT-5.5 Thinking, tandis que la variante GPT-5.5 Pro (dédiée aux charges de travail les plus exigeantes, avec du calcul de test parallèle supplémentaire) est réservée aux abonnements Pro, Business et Enterprise. Codex, l’agent de développement d’OpenAI qui revendique désormais quatre millions d’utilisateurs hebdomadaires, en bénéficie également dès le premier jour. On notera toutefois que sur ChatGPT, le mode « Instant » demeure figé sur GPT 5.3.
Pour les développeurs tiers en revanche, il faudra patienter. L’accès API n’est pas disponible au lancement : OpenAI invoque la nécessité d’intégrer des garde-fous supplémentaires en matière de cybersécurité avant d’ouvrir les vannes. Les grilles tarifaires qui circulent situent GPT-5.5 à 5 dollars par million de jetons en entrée et 30 dollars en sortie, avec un GPT-5.5 Pro à 30 et 180 dollars pour les usages les plus lourds. Plus cher que Claude Sonnet 4.6, moins cher qu’Opus 4.7 sur l’entrée. L’éditeur met toutefois en avant une baisse d’environ 40 % du nombre de jetons nécessaires pour produire un résultat équivalent, ce qui rétablit à peu près l’équilibre économique face à la génération précédente.
Les entreprises vont devoir s’habituer à une cadence de sortie accélérée. Six semaines entre deux itérations, cela laisse peu de temps pour évaluer un nouveau modèle sur les usages internes des entreprises. Mais il va falloir se synchroniser sur ce tempo. Jakub Pachocki, directeur scientifique d’OpenAI, prévient d’ailleurs sans détour : « Nous observons des améliorations assez significatives à court terme, et extrêmement significatives à moyen terme. À vrai dire, je pense que les deux dernières années ont même été étonnamment lentes. » Avis aux amateurs.
____________________________

 puis
puis