
OpenAI remet un gros coup d’accélérateur sur la génération d’images. Plus précis, plus discipliné et nettement plus solide sur les workflows réels, GPT-Image 2.0 transforme enfin l’IA visuelle en vrai outil de prod. Une nouvelle version plutôt bluffante par la qualité de ses rendus !
Depuis quelques jours, un pseudo-mystérieux modèle de génération d’images dénommé « Duct Tape » trustait les premières places de LM Arena. Dans le même temps, certains utilisateurs de ChatGPT découvraient quelque peu aléatoirement que leur assistant IA devenait capable de nouveaux prodiges visuels lors de certaines requêtes de génération d’images. Depuis hier soir, le suspense est levé ! OpenAI a officialisé l’arrivée de « GPT-Image 2.0 » (alias Duct Tape). Et le saut en avant est une nouvelle fois très important.
Le retour en grâce d’OpenAI
Difficile de parler de GPT-Image sans parler de Nano Banana de Google. Les deux modèles se livrent une intense compétition. À la rédaction, nous considérons que GPT-Image 1.5 est d’une manière générale meilleur à la génération d’images, mais Gemini (et son modèle Nano Banana) souvent plus efficace sur des prompts de retouche et la génération d’images 4K.
Même si le 4K demeure le meilleur atout de Nano Banana Pro, GPT-Image 2.0 reprend le flambeau de meilleur modèle génératif d’images que ce soit en création d’images à partir de prompt textuels, de créations d’infographie à partir de données ou de retravail et retouche d’images existantes. On peut même dire que le modèle nous a bluffé à plus d’un titre sur les essais réalisés ces dernières heures. Et ça fait finalement longtemps désormais qu’OpenAI ne nous avait plus bluffé !
Il est intéressant de voir que le créateur de ChatGPT est en train de revenir au sommet après avoir pris quelques claques par Anthropic ces 6 derniers mois, mais ce retour sous les projecteurs ne s’effectue pas par les LLM. Outre cette sortie de GPT-Image 2.0 vraiment convaincante, on apprend parallèlement qu’OpenAI est en train de faire un carton avec son outil agentique Codex. En deux semaines (et avec l’aide des différentes améliorations apportées pour en faire un outil plus généraliste), l’outil a séduit un million d’utilisateurs supplémentaires portant à 4 millions le nombre d’utilisateurs actifs de Codex !
Mais revenons-en à l’annonce du jour et à l’officialisation des modèles GPT-Image 2.0 Instant et GPT-Image 2.0 Thinking.

Le prompt : « Scène de voyage photoréaliste et spontanée : une personne debout à une halte panoramique en bord de route côtière, matin couvert, pellicule 35 mm. Cadrage naturel imparfait, grain apparent, lumière ambiante, couleurs sourdes, vent dans les vêtements et les cheveux, réalisme cinématographique, atmosphère de photographie documentaire authentique. »
Quoi de neuf ?
GPT-Image 2.0 est bien plus qu’une simple itération du modèle génératif. Il progresse dans de très nombreux domaines clés qui en font un outil bien plus utile au quotidien dans les tâches professionnelles comme dans les tâches agentiques.
Formats d’image et résolution 2K : Fini la résolution figée. GPT-Image 2.0 génère désormais des images allant jusqu’à une résolution 2K dans une grande variété de ratios (portrait, paysage, 16:9, 21:9, 4:3, 9:16, A4, bannières…). Cette souplesse ouvre concrètement la porte à la production d’assets directement utilisables dans un contexte marketing ou éditorial. Le modèle reste derrière Nano Banana Pro sur la résolution 4K pure, mais gagne en polyvalence là où son prédécesseur contraignait souvent à passer par une retouche ou un recadrage sous Photoshop.
Qualité des textes, même sur les petites polices : C’est historiquement le talon d’Achille de tous les générateurs d’images. Certes GPT-Image 1.5 et Nano Banana 2.0 ont beaucoup progressé sur les textes, notamment les gros textes et les titres. Mais bien des défauts connus resurgissaient dès que les polices employées étaient petites ou dans des contextes complexes. GPT-Image 2.0 franchit ici un cap spectaculaire. Titres de une, mentions légales en pied de page, chiffres dans une infographie, code-barres, légendes de graphique, étiquettes de menu, numéros de volume sur une couverture de magazine : tout reste net, aligné, lisible. OpenAI revendique une précision typographique proche des 99% et c’est sans doute la première fois qu’un modèle rend le texte dans une image avec un niveau de fiabilité compatible avec un vrai workflow de PAO. Autre nouveauté notable : la prise en charge qualitative des écritures non-latines (japonais, coréen, hindi, bengali), qui posaient encore de sérieux problèmes à GPT-Image 1.5.

Le prompt : « Publicité pour le lancement d’un baume à lèvres effet glow par une célébrité mode, ciblant les 14-30 ans. Ambiance shooting professionnel, mannequin cool, tendance et stylé·e. Esthétique épurée, rendu premium et luxueux, visuel résolument dans l’air du temps. »
Fidélité d’exécution des instructions : Le modèle suit les prompts avec une docilité inédite. Demandez-lui un poster avec six panneaux disposés selon une grille 2×3, un titre en haut, un QR code en bas à droite et une palette précise : il s’exécute sans broncher et sans réinterpréter « créativement » pour ne pas dire « très librement » vos consignes. La capacité à respecter des contraintes stylistiques subtiles (ton éditorial, inspiration d’un mouvement graphique, charte couleur) est également en nette progression. En la matière, GPT-Image 2.0 vogue très au-dessus de la concurrence.
Composition multi-éléments : GPT-Image 2.0 s’en sort remarquablement bien sur les compositions denses et structurées, celles qui cassaient la quasi-totalité des modèles jusqu’ici : planches d’infographie, schémas scientifiques, tableaux de bord, maquettes d’interfaces, diagrammes architecturaux, plans, cartes annotées. On peut désormais lui confier la production d’un one-pager ou d’une couverture de rapport avec un résultat exploitable en première intention, là où les précédentes générations demandaient systématiquement un passage par un outil vectoriel pour corriger les approximations.
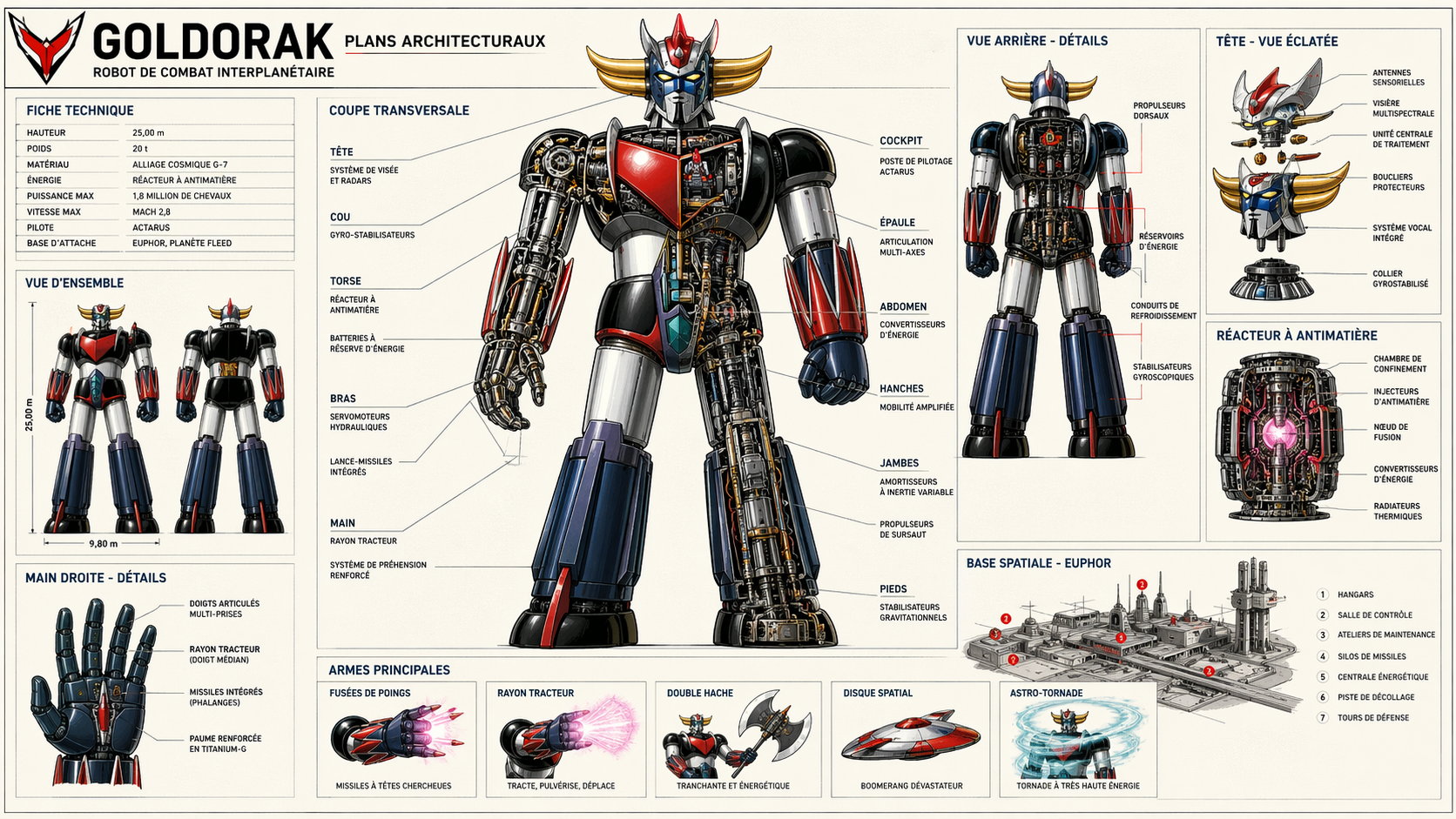
Le prompt : « Regénère les plans architecturaux de Goldorak au format 16:9 »
Cohérence sérielle : Sans doute l’avancée la plus attendue par les usages professionnels. Le modèle sait maintenir un personnage, un produit, un style ou un décor cohérent d’une image à l’autre. Planche de personnage, planches de manga, storyboards, séries de visuels pour une campagne, déclinaisons d’un même visuel dans plusieurs formats, bandes dessinées multi-panels : tout cela devient jouable en une seule conversation. Cette avancée fait basculer GPT-Image 2.0 du statut d’outil d’exploration créative à celui de véritable outil de production.

Le prompt : « Planche de bande dessinée dans le style d’un manga japonais seinen : noir et blanc, trames, cases dynamiques, trait réaliste et mature.
Quelles différences entre Instant et Thinking ?
Comme OpenAI l’a déjà fait sur ses LLM, le modèle est décliné en deux variantes aux usages très différents.
GPT-Image 2.0 Instant est la version par défaut, pensée pour la rapidité. Elle encaisse un prompt, réfléchit peu, et renvoie une image en quelques secondes. C’est le modèle qu’on dégaine pour une illustration d’article, une vignette pour réseaux sociaux, un visuel rapide. OpenAI revendique une vitesse de génération environ deux fois supérieure à celle de GPT-Image 1.5.
GPT-Image 2.0 Thinking pousse le curseur de l’autre côté. La variante applique les capacités de raisonnement avancées de GPT-5.4 Thinking à la génération visuelle. Concrètement, elle prend plus de temps, peut interroger le web pour récupérer du contexte, analyser des documents uploadés (un PDF, des données brutes, un brief), raisonner sur la mise en page avant de produire, vérifier sa propre sortie, et générer plusieurs images cohérentes en une seule requête – jusqu’à huit visuels sériellement cohérents. C’est le mode à privilégier pour les tâches de conception : couverture de magazine à partir d’un sommaire, déclinaison d’une campagne publicitaire en plusieurs formats, planche de BD, infographie construite à partir d’un jeu de données, moodboard argumenté.
En résumé, Instant est le modèle utilisé pour l’illustration rapide, Thinking pour la conception professionnelle.

Le prompt : « Crée à partir de cet article une infographie au format 21:9 et au style cartoon 3D humoristique avec un même personnage chatbot sympathique pour illustrer les différents axes de progression de GPT-Image 2.0 ».
Des choses à essayer avec GPT-Image 2.0
Quelques terrains de jeu où le modèle brille particulièrement et qui, pour beaucoup, étaient tout simplement hors de portée des générateurs précédents :
* Recréer une couverture de magazine complète avec titre, accroches, numéro, code-barres, mentions légales. Le rendu est bluffant de crédibilité éditoriale.
* Générer une infographie à partir de données brutes (un CSV, un tableau, un extrait de rapport). Thinking excelle ici en structurant la mise en page avant de générer.
* Produire une planche de BD ou de manga en plusieurs cases avec un même personnage, un même décor et une continuité narrative.
* Concevoir une maquette d’UI ou un écran d’application mobile avec textes lisibles, icônes cohérentes et éléments d’interface identifiables. Les designers vont gagner un temps précieux pour leurs phases d’idéation.
* Créer une character sheet (fiche personnage sous plusieurs angles, expressions, tenues) exploitable pour un projet de jeu, un livre illustré ou un storyboard.
* Décliner un même visuel en plusieurs formats (bannière web, post carré, story verticale, vignette LinkedIn) en conservant parfaitement la charte.
* Produire un poster événementiel avec hiérarchie typographique soignée, logos, dates, partenaires.
* Générer un menu de restaurant, une carte de vin, une affiche de conférence : des livrables où la moindre faute de frappe ou d’alignement trahissait immédiatement l’origine IA.

Le prompt : « Crée une infographie au format 16:9, sans aucun texte, dans un style très « Lifestyle » photoréaliste pour illustrer différentes choses à essayer avec GPT-Image 2.0 selon cet article »
Disponibilité et prix
GPT-Image 2.0 est déployé progressivement dès aujourd’hui pour l’ensemble des utilisateurs de ChatGPT et de Codex, y compris sur le tier gratuit avec toutefois un accès aux fonctions les plus avancées (notamment le mode Thinking et la génération multiple) réservé aux abonnés Plus, Pro, Team et Enterprise.
Côté API, le modèle « gpt-image-2 » sera progressivement ouvert aux développeurs dans les jours qui viennent, avec une tarification calée sur celle de GPT-Image 1.5 : 8 $ le million de tokens en entrée image (2 $ en cached), 30 $ le million de tokens en sortie, et 5 $ / 10 $ pour la partie texte. Traduit en ordre d’idées pratique, la facture va d’environ 0,006 $ pour une image 1024×1024 en qualité basse à 0,21 $ en qualité haute, avec un plafond de résolution officielle fixé à 2K (les sorties supérieures sont possibles avec l’API mais restent en bêta, OpenAI précisant que les résultats peuvent être incohérents). À noter : OpenAI va déprécier GPT-Image 1.5 comme modèle par défaut dans son écosystème, même s’il restera accessible via l’API pour assurer la continuité des intégrations existantes.

Le prompt : « Plan large cinématographique 16:9 d’un studio créatif numérique futuriste en pleine nuit, éclairage volumétrique spectaculaire en teintes bleu-sarcelle profond et ambre chaud. Au premier plan, une station de travail holographique incurvée et épurée affiche une constellation de panneaux de sortie en lévitation : une couverture de magazine nette avec un titre lisible « IMAGE 2.0 » et des mentions légales en petits caractères, une infographie aux données chiffrées précises et aux graphiques en barres, une maquette d’interface mobile au texte parfaitement lisible, une planche de bande dessinée montrant un même personnage dans trois poses cohérentes, et une affiche bilingue (caractères latins et japonais). Tous les panneaux sont d’une netteté absolue, parfaitement alignés, avec une typographie impeccable. En arrière-plan, une structure subtile de réseau neuronal doré rayonne vers l’extérieur, symbolisant le moteur d’IA. Étiquette minimaliste flottante « GPT-IMAGE 2.0 » en sans-serif épuré dans le coin supérieur droit. Esthétique photographique éditoriale haut de gamme, rappelant les couvertures de Wired ou de MIT Technology Review, profondeur de champ, reflets chromatiques subtils sur les surfaces vitrées, ultra-détaillé, rendu photoréaliste, qualité 2K. »
Bien évidemment, tout n’est pas encore parfait et la marge de progression reste importante. OpenAI concède d’ailleurs que quelques angles morts importants persistent : la modélisation cohérente du monde physique reste perfectible : origamis, Rubik’s Cube, surfaces cachées ou inversées donnent encore du fil à retordre au modèle. Les détails très denses ou répétitifs (pensez aux grains de sable) peuvent aussi le mettre en difficulté, tout comme les schémas et diagrammes reposant sur des flèches ou étiquettes précises, qui méritent toujours une relecture attentive.
Avec ce lancement, OpenAI reprend très clairement la main sur le terrain de la génération d’images, un terrain de jeu sur lequel Anthropic ne s’est pas encore aventuré. On notera que les précédentes versions avaient souvent fait le buzz sur les réseaux sociaux. Ça ne sera pas forcément le cas avec cette version, OpenAI visant désormais en priorité les cas d’usage professionnels.
La pression est désormais dans le camp de Google, dont la prochaine itération de Nano Banana va devoir trouver autre chose que le seul argument du 4K pour continuer à exister dans le match.
PS : toutes les illustrations de cet article sont l’œuvre de GPT-Image 2.0.
____________________________

 puis
puis