
La société californienne annonce la disponibilité de son « entrepôt de données » sur le cloud Microsoft Azure. Cette offre multicloud de « Data Warehouse as a Service » qui vient compléter l’offre sur Amazon AWS, est donc aujourd’hui unique sur le marché.
Les Data Wharehouses classiques ne sont pas bien adaptés pour le Cloud
Crée en 2012 par deux ingénieurs Français, Benoit Dageville et Thierry Cruanes, Snowflake a connu un rapide développement avec son data warehouse natif sur le cloud AWS d’Amazon. Le data warehouse (entrepôt de données) est connu de toutes les sociétés qui reçoivent et stockent d’important volumes de données qu’ils souhaitent traiter et analyser dans le temps pour mieux conduire leurs activités quotidiennes. Les bases de données classiques ont été conçues en premier lieu pour gérer les transactions et les opérations. Le data warehouse est donc une base de données qui rassemble des données provenant de différentes sources (bases de données) dans l’entreprise (ERP, CRM, etc.).
Après avoir recueilli en temps réel les données des transactions, de façon optimisée grâce à des outils spécifiques (ETL, et boutons d’optimisation) le data warehouse conserve ces données transformées. Elles sont vérifiées, sujet-orientées, historiques et inaltérables, prêtes à être utilisées avec des requêtes SQL pour des applications d’analyse plus sophistiquées, en temps réel, etc. Le data warehouse sépare donc les processus d’opérations des processus analytiques et apporte un environnement qui facilite les requêtes.
Les entreprises ont aujourd’hui besoin d’analyser leurs données quasiment en temps réel.
Mais, conçus bien avant l’arrivée du Cloud pour des ressources fixes, les data warehouses classiques sont mal équipés pour profiter de l’élasticité du Cloud. Les outils et procédures qu’ils utilisent ne permettent pas de manipuler des données semi-structurées provenant de différents cloud. Ils n’offrent donc pas la flexibilité et la réactivité dont ont besoin un nombre croissant entreprises qui ne veulent pas dépendre d’un seul Cloud public.
Lors d’interviews qu’ils nous ont accordé récemment (voir B Dageville et T Cruanes), les cofondateurs de Snowflake expliquent avoir développé leur propre base de données relationnelle SQL avec l’objectif de créer des data warehouses pour le Cloud (data warehouse as a service). Cette approche permet à l’utilisateur de s’affranchir des contraintes d’administration et de gestion connues sur les plateformes big data ou avec les data warehouses traditionnels.
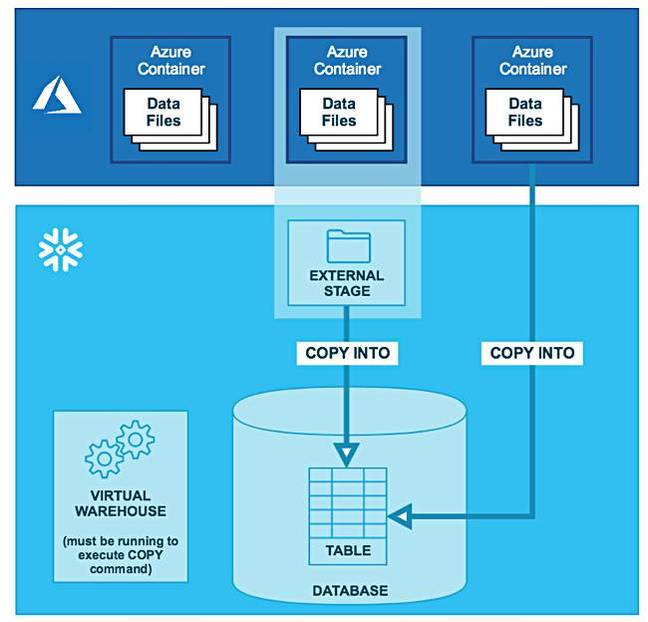
L’architecture de Snowflake s’appuie donc sur des micro-partitions pour stocker et sécuriser les données des utilisateurs dans le Cloud. Il utilise le stockage objet du cloud pour récupérer et stocker des données structurées et semi-structurées dans des formats de type JSON, AVRO ou XML De là sont extraites les méta-données qui seront utilisées dans différentes requêtes SQL pour alimenter les applications analytiques. Les lourdes procédures d’ETL des data warehouses classiques sont désormais reléguées à une couche élastique de traitements dans le cloud qui est parfaitement scalable dynamiquement. L’objectif est de permettre aux utilisateurs de se centrer entièrement sur les requêtes qui doivent être exécutées le plus rapidement possible, même si les requêtes SQL s’adressent à des données peu structurées ou même non structurées.
Un même Data Wharehouse as a service sur AWS et Azure Cloud
La nouvelle offre de Snowflake sur Azure Cloud offrira les mêmes fonctionnalités que sur AWS. L’utilisation de Snowpipe, un service automatique basé sur une API REST, permet d’écouter l’arrivée des nouvelles données dans l’environnement de stockage sur le Cloud et de charger les flux de données dans Snowflake. Déjà disponible sur S3 d’Amazon, Snowpipe fonctionnera de façon identique avec les données qui arrivent dans Azure Blob, un système de stockage d’objets massivement scalables pour les données non structurées. L’utilisation de Snowpipe ne demande pratiquement aucune configuration manuelle et opère sur des serveurs séparés pour assurer une parfaite isolation entre les charges de travail. Le principe de tarification de Snowflake sur AWS et sur Azure Cloud sera le même. Il repose sur deux fonctions distinctes dans le cloud, le stockage et le traitement. Le coût est donc basé sur la consommation de ces 2 fonctions.
Au fur et à mesure que les sociétés migrent leurs opérations sur le cloud, le concept de récupération et de traitement des données qui est au cœur des data warehouse change complètement parce que les fournisseurs de services Cloud peuvent maintenant virtualiser une grande partie des aspects techniques de la gestion des données. Très clairement les grands fournisseurs de Cloud ont aussi compris qu’ils devaient avoir leur propre data warehouse. Chez Microsoft il s’appelle Azure SQL DataWarehouse, chez Amazon il s’appelle Redshift, chez Google il s’appelle BigQuery. Snowflake peut être vu comme un concurrent de Redshift ou d’Azure SQL DW, mais la valeur de Snowflake est d’offrir les mêmes outils et les mêmes approches à des entreprises qui souhaitent partager des données avec leurs clients et/ou leurs partenaires dont les données sont sur des Cloud différents.

 puis
puis