
En combinant performance agentique, gestion optimisée du contexte et efficacité économique, Claude Opus 4.5 confirme la maturité technologique d’Anthropic et relance la course aux modèles agentiques. Comme Gemini 3 et GPT-5.1 illustre les gros progrès réalisés par l’IA en cette fin d’année et le basculement des LLMs vers des capacités opérationnelles concrètes, où raisonnement, automatisation et intégration profonde convergent.
Après Google et OpenAI, c’est au tour d’Anthropic de pousser le curseur un cran plus loin. En quelques jours, nous avons vu émerger le très mal nommé GPT-5.1 qui aurait pu s’appeler GPT-6 tant la différence de qualité des réponses est flagrante par rapport à GPT-5 et tant l’IA dévoile un visage différent. Lancement accompagné de GPT-5.1-Codex Max un modèle de codage “agentique” capable de travailler plus de 24 heures d’affilée inaugurant à des mécanismes avancés de compaction de contexte.
La semaine dernière, Google dégainait son Gemini 3 Pro, nouveau chouchou des classements de benchmarks accompagné d’un Nano Banana Pro époustouflant sur la retouche de photos. Là encore, le saut qualitatif entre « 3 Pro » et « 2.5 Pro » est important.
Alors forcément, dans ce jeu de surenchère, Anthropic ne pouvait restée sans réponse. Et son Claude Opus 4.5 introduit hier soir démontre une nouvelle fois que s’il existe bien un plafond de verre des LLMs, il n’a pas encore été atteint, ou a été repoussé bien plus haut par cette nouvelle génération de modèles frontières.
Un Opus taillé pour le code, les agents et l’usage réel de l’ordinateur
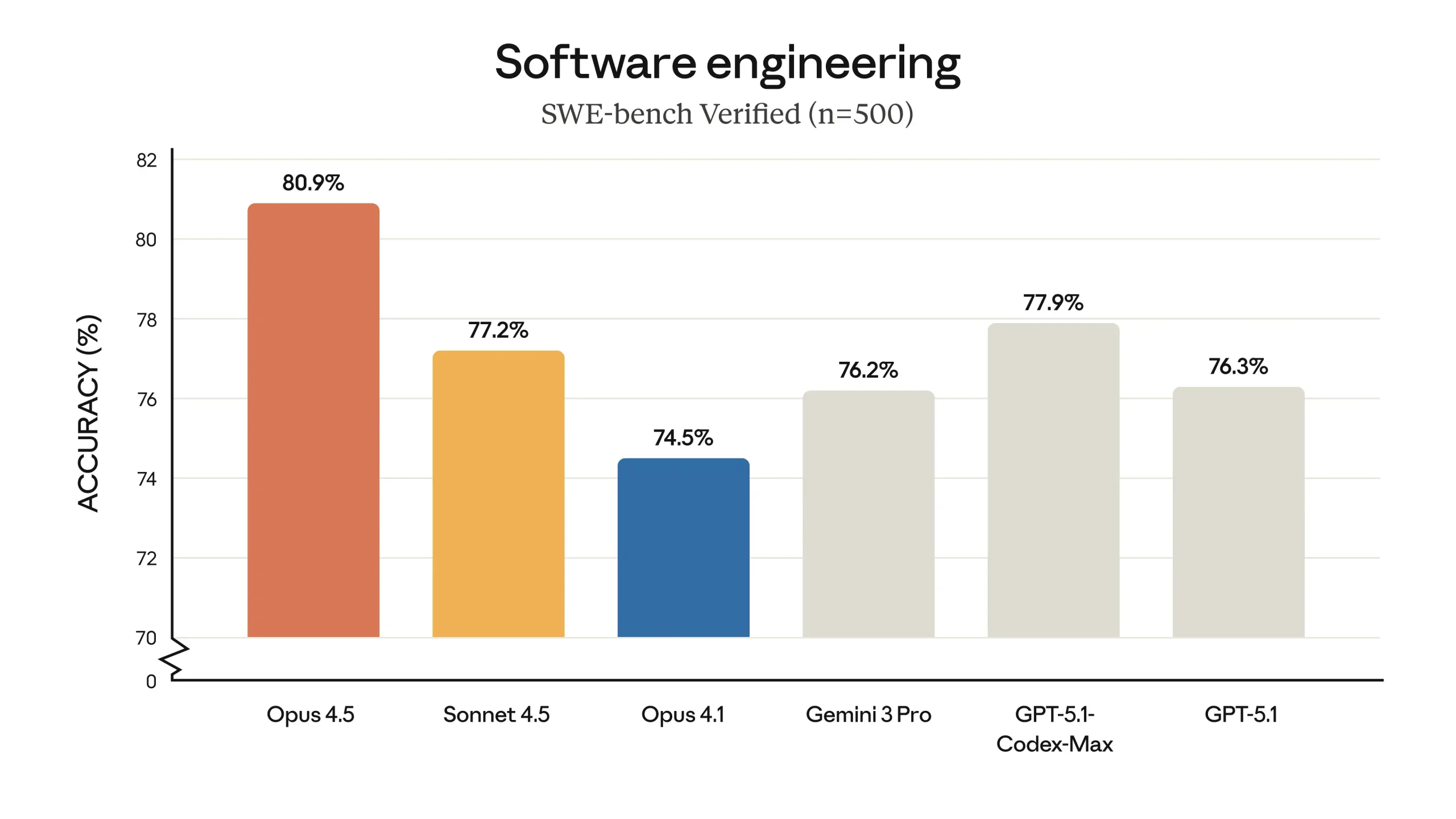
Avec 80,9 % sur SWE-bench Verified, devant GPT-5.1-Codex-Max (77,9 %) et Gemini 3 Pro (76,2 %), le nouveau modèle d’Anthropic reprend la “couronne du code” et de l’ingénierie logicielle automatisée pour l’IA. Car, oui, une fois encore, c’est bien sur le terrain du codage que le marketing d’Anthropic insiste comme si c’était l’usage premier de ses modèles IA.
Anthropic présente Claude Opus 4.5 comme son modèle « le plus intelligent, le plus efficace, et le meilleur au monde pour le code, les agents et l’usage de l’ordinateur ».
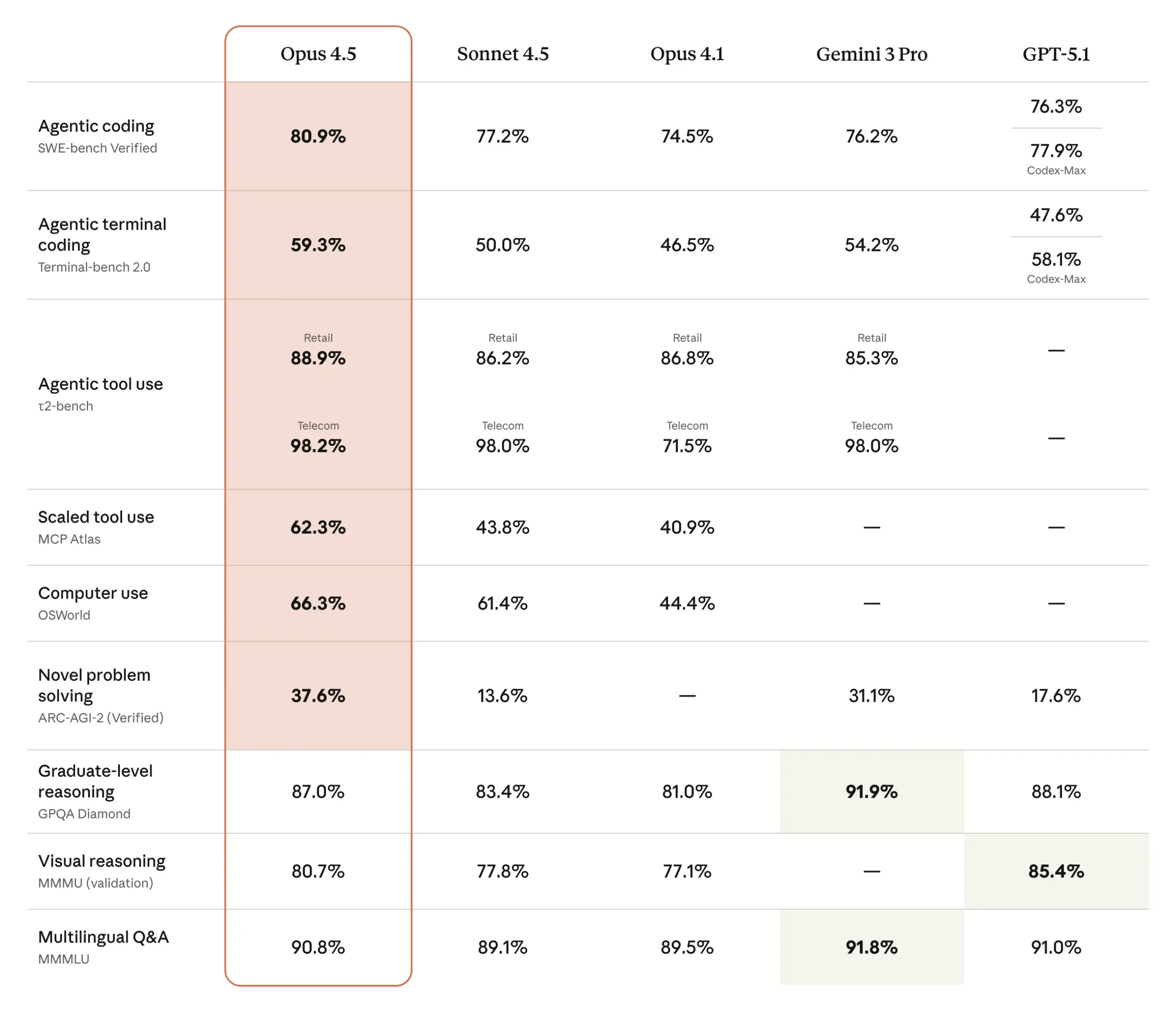
Au-delà de la formule, plusieurs éléments objectifs viennent étayer cette promesse. D’abord, les benchmarks. Opus 4.5 atteint 80,9 % sur SWE-bench Verified, un corpus de tickets GitHub réalistes où il faut comprendre un bug, naviguer dans un code existant, appliquer un correctif et faire passer les tests. Le modèle domine également SWE-bench Multilingual sur 7 langages sur 8, démontrant un bond de plus de 10 points sur Aider Polyglot (problèmes de code complexes). Enfin le progresse fortement sur des benchmarks agentiques comme BrowseComp-Plus, Vending-Bench ou τ2-bench, qui testent la capacité à dérouler des scénarios longs dans des systèmes réels.
Surtout, Opus 4.5 se distingue sur l’usage direct de l’ordinateur (la capacité agentique « Computer Use »). Sur OSWorld, un benchmark qui mesure la capacité d’un modèle à piloter une interface graphique (ouvrir des fenêtres, manipuler des fichiers, configurer des outils), il atteint 66,3 %, là où les générations précédentes restaient nettement en dessous.
C’est ce socle qui alimente les nouveaux cas d’usage que met en avant Anthropic : agents capables d’automatiser des tâches bureautiques complexes, de conduire des workflows financiers ou de traiter des scénarios d’investigation cyber en croisant logs, renseignement sur la menace et référentiels de vulnérabilités.
Anthropic insiste également sur la capacité d’Opus 4.5 à “tenir dans la durée”. Sur un test interne de type “take-home exam” pour ingénieurs performance, le modèle a obtenu, en deux heures, un meilleur score que n’importe quel candidat humain passé par cette évaluation. Les retours de partenaires comme Warp, Cursor ou Notion convergent d’ailleurs : moins de dead-ends dans les tâches longues, davantage de tâches menées à terme, et une consommation de tokens nettement réduite à qualité égale.
Sous le capot : compaction, “effort” et intégration profonde dans les outils
Techniquement, Opus 4.5 ne gagne pas seulement en “QI”, mais aussi en hygiène de travail. Comme GPT-5.1-Codex-Max, le modèle est conçu pour mieux gérer son contexte dans la durée, grâce à des mécanismes de compaction et de mémoire qui permettent de résumer intelligemment ce qui s’est passé plutôt que de simplement dérouler un gigantesque contexte de 1 million de tokens.
 Il n’y a pas que les devs qui en profitent. Côté utilisateur, cela se traduit par une fonctionnalité d’“endless chat” : les conversations longues ne butent plus sur une limite de contexte, le modèle résume et poursuit sans alerter l’utilisateur.
Il n’y a pas que les devs qui en profitent. Côté utilisateur, cela se traduit par une fonctionnalité d’“endless chat” : les conversations longues ne butent plus sur une limite de contexte, le modèle résume et poursuit sans alerter l’utilisateur.
Autre nouveauté intéressante pour les DSI et leurs équipes : le fameux paramètre “Effort”. Sur l’API Claude, il devient possible de piloter le niveau d’effort de raisonnement du modèle, et donc le compromis coûts/latence/capacité. À “effort” moyen, Opus 4.5 égalise le meilleur score de Sonnet 4.5 sur SWE-bench Verified tout en utilisant 76 % de tokens de sortie en moins ; à effort maximal, il gagne encore 4,3 points tout en restant 48 % plus économe que Sonnet.
Autrement dit, le modèle ne se contente pas d’être plus fort : il “travaille mieux”, en faisant moins de détours pour arriver au même résultat.
Et avec un dynamisme qui rappelle celui de Google qui a imposé instantanément son Gemini 3 partout, Anthropic accompagne le lancement d’une salve d’intégrations concrètes. Claude Code évolue avec un mode Plan plus structuré (questions de clarification, fichier plan.md éditable, exécution orchestrée), et arrive dans l’application Desktop de Claude pour lancer plusieurs sessions locales ou distantes en parallèle.
Surtout, deux intégrations très parlantes pour le quotidien des équipes font leur apparition : Claude for Chrome et Claude for Excel, jusqu’ici en pilote, deviennent disponibles plus largement pour les offres Max, Team et Enterprise. De quoi laisser entrevoir des agents capables de manipuler automatiquement des feuilles Excel complexes, des présentations ou des documents, avec des gains de 15 à 20 % sur les tâches d’automatisation financière selon les évaluations internes d’Anthropic.
Enfin, Opus 4.5 est lancé avec une baisse de prix significative : 5 dollars le million de tokens en entrée et 25 dollars en sortie, soit environ un tiers du coût des précédents modèles Opus et jusqu’à 67 % de réduction selon certaines analyses. Et forcément, c’est un atout clé pour les DSI souvent freinés par les tarifs pratiqués par Anthropic face à Google et OpenAI : le “haut de gamme” d’Anthropic devient envisageable non plus seulement pour quelques POC ou cas d’usage limités, mais pour des workloads de production à grande échelle.
Anthropic prend rang d’acteur enterprise… et les hyperscalers accourent
Sur le segment des usages enterprise, Anthropic rivalise désormais, voire devance ses grands concurrents en parts de marché déclarées. Notamment sur le marché américain. Et l’on ne peut que noter la précipitation des grands partenaires Cloud à revendiquer la disponibilité immédiate de Cloud Opus 4.5 sur leurs plateformes.
Microsoft, qui longtemps n’a pas eu accès aux modèles d’Anthropic en raison de son partenariat avec OpenAI, s’est empressé d’annoncer l’intégration du modèle dans Microsoft Foundry, la nouvelle fabrique d’agents IA sur Azure, ainsi que dans les offres payantes GitHub Copilot et dans Copilot Studio. Avec un discours aligné sur celui de Microsoft Ignite 2025 diffusé la semaine dernière : nous sommes à un “point d’inflexion” où les modèles ne sont plus seulement des assistants mais de véritables collaborateurs capables de piloter des workflows multi-outils de bout en bout, et Claude Opus 4.5 est un modèle agentique phare.
Partenaire des premières heures de la startup, Google a également sorti le mégaphone marketing pour annoncer l’arrivée d’Opus 4.5 sur Vertex AI, dans un contexte où Gemini 3 reste la locomotive maison. Sur Vertex, Claude bénéficie des briques d’Agent Builder et de l’Agent Development Kit, d’un contexte jusqu’à 1 million de tokens, du prompt caching, des batch predictions et des protections de sécurité avancées comme Model Armor pour contrer l’injection de prompts et le “tool poisoning”.
Enfin, l’un des principaux financiers d’Anthropic, Amazon, annonce quasi simultanément la disponibilité de Claude Opus 4.5 dans Amazon Bedrock, présenté comme le nouveau standard pour le code de production, les agents sophistiqués et les tâches bureautiques complexes, le tout “à un tiers du coût” de la génération précédente.
Bref, les fans d’IA et les DSI ont du pain sur la planche. Ils ont une pléthore de nouveaux à expérimenter sur leurs propres scénarios métiers afin de découvrir lequel de ces modèles réalisent le mieux leurs objectifs car les Benchmarks ne donnent qu’une vision parcellaire de la « vérité ». Mais il paraît évident qu’avec Gemini 3, GPT 5.1 et Claude Opus 4.5, l’IA générative agentique a fait un bond considérable en cette fin d’année.

 puis
puis