
Mistral AI refait parler d’elle et remonte sur le ring des modèles frontières pour défendre l’honneur de l’Europe et les modèles ouverts avec la présentation de sa nouvelle génération de modèles, Mistral 3 et Ministral 3, qui replacent la France au cœur de la scène mondiale de l’intelligence artificielle open source.
Dans un paysage dominé par les géants américains et chinois, la jeune pousse française Mistral AI entend bien continuer d’imposer sa vision d’une IA ouverte, européenne et accessible. Hier soir, l’entreprise a dévoilé la famille Mistral 3, une série de modèles nativement multimodaux, capables de traiter aussi bien le texte que l’image.
Cette nouvelle génération se distingue par son ouverture : tous les modèles sont publiés sous licence Apache 2.0, offrant aux développeurs et aux entreprises une liberté maximale d’utilisation, de modification et de commercialisation.
L’annonce n’était pas vraiment une surprise puisque AWS avait « vendu » la mèche dans son keynote d’ouverture de sa conférence re:Invent 2025 en annonçant fièrement l’arrivée de ces modèles sur son service Model-as-a-Service Amazon Bedrock.
On rappellera également que Mistral avait introduit un modèle Mistral Medium 3.1 cet été, qui n’est pas un modèle ouvert et réservé aux abonnés Premium de sa plateforme et de son chatbot. En juin dernier, Mistral avait aussi lancé en open weight son « Mistral Small 3.2 » désormais très challengé par Ministral 14B.
Un LLM frontière de 675 milliards de paramètres
Le fleuron de cette gamme est donc désormais Mistral Large 3, un modèle de type Mixture-of-Experts (MoE) qui totalise 675 milliards de paramètres (675B), mais n’en active que 41 milliards par token généré (grâce à son architecture MoE), optimisant ainsi puissance et efficacité. Sa fenêtre de contexte atteint 256 000 tokens, ce qui lui permet d’ingérer d’un seul coup des volumes significatifs de données. On n’est pas très loin des 400.000 tokens de GPT-5.1 mais Gemini 3 et Claude Opus 4.5 offre désormais des fenêtres contextuelles de plus d’un million de tokens voire le double.
Destiné aux usages intensifs d’entreprise – analyse documentaire, programmation, assistance personnelle – il se positionne déjà en tête des benchmarks open source, dans la lignée d’un DeepSeek v3.1, d’un Kimi K2 ou d’un GPT-OSS d’OpenAI. Le modèle n’étant pas limité au texte, il analyse et comprend aussi des images, ce qui le rend pertinent pour des cas d’usage comme l’annotation visuelle, l’analyse de documents illustrés ou la génération de code à partir de schémas.
L’une des forces de Mistral Large 3, outre sa rapidité de réponse pour un LLM massif, c’est le multilinguisme avancé. Là où beaucoup de modèles restent centrés sur l’anglais et le chinois, Mistral Large 3 affiche des performances de haut niveau dans les conversations multilingues, ce qui le rend particulièrement adapté à l’Europe et aux environnements internationaux. C’est clairement l’un des modèles les plus constats et équilibrés sur toutes les langues européennes.
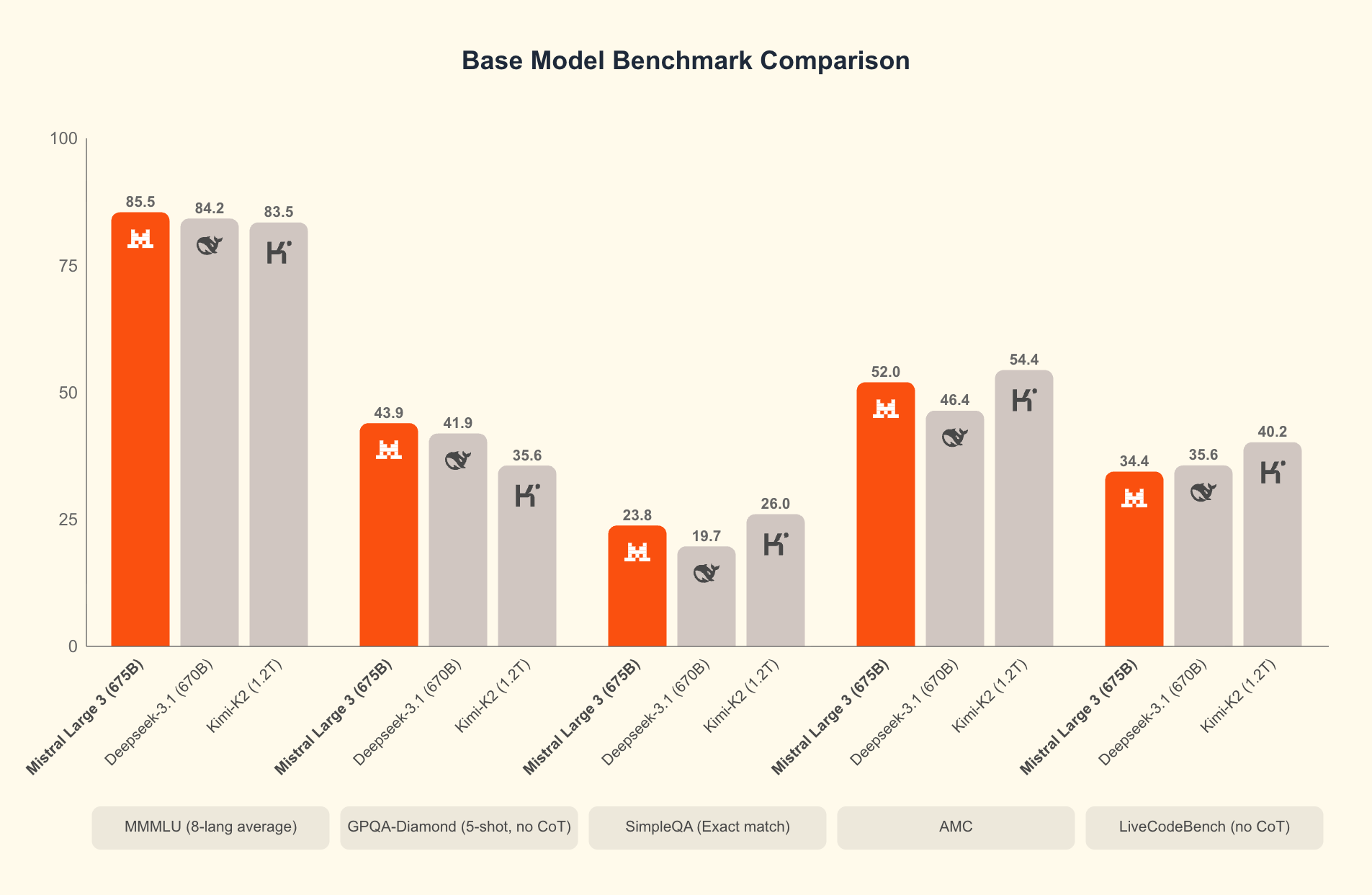
Entraîné sur 3000 GPU NVIDIA H200, il bénéficie d’une co-conception matériel/logiciel avec NVIDIA et Red Hat pour optimiser le déploiement (formats compressés NVFP4, compatibilité avec vLLM). Cela lui donne une accessibilité technique rare pour un modèle de cette taille. C’est d’autant plus important que Mistral AI en a fait un modèle « open-weight » que les entreprises peuvent facilement s’approprier non seulement pour l’héberger en local sur leur datacenter mais aussi et surtout pour le personnaliser et le fine-tuner « à leur sauce », sur leur jargon et leur patrimoine informationnel. Mistral AI propose d’ailleurs sur sa plateforme trois niveaux de personnalisation : du paramétrage avancé associé à du RAG sans toucher aux poids du modèle, un fine-tuning simplifié via son service, et une customisation avancée via son SDK.
Reste que, si le modèle est évidemment capable de raisonnement et de correctement comprendre et gérer des requêtes complexes, ce Mistral Large 3 demeure un modèle classique et non un modèle hybride (façon Gemini 3 et Claude Opus 4.5) ou un pur modèle de raisonnement avancé (comme GPT-o3). Il est donc plus limité qu’un OpenAI GPT-5.1, Claude Opus 4.5 ou Gemini 3 sur des problèmes STEM (Science, Technology, Engineering & Mathematics), sur les calculs mathématiques et sur les problèmes de codage avancés. Mais Mistral AI serait en train de plancher sur une version « reasonning » de Large 3.
Néanmoins, Mistral AI embarque de vraies capacités agentiques et dispose d’un « Function Calling » natif (le modèle peut appeler directement des fonctions définies par l’utilisateur ou par une application, ce qui permet d’intégrer des API, des bases de données ou des systèmes métiers dans un flux conversationnel), de sorties structurées (il génère des réponses formatées en JSON, ce qui facilite son intégration dans les pipelines automatisés et le pilotage d’agents) et d’une fonctionnalité native « Agent & Conversations » (qui permet de configurer le modèle comme un agent doté d’un état propre afin de retenir les contextes d’interaction sur plusieurs tours).
Selon Mistral et Microsoft (qui héberge également les modèles sur Azure Foundry), Mistral Large 3 est aussi optimisé pour minimiser les hallucinations, suivre précisément les instructions et maintenir une cohérence dans les dialogues longs, ce qui le rend adapté aux environnements de production et aux workflows automatisés.
Ministral 3, petits mais qui en font max…
À côté de ce mastodonte, Mistral dégaine dans la famille une série de modèles plus denses, plus légers, pensés pour l’exécution locale et embarquée : Ministral 3. Déclinée en trois tailles – 3 milliards, 8 milliards et 14 milliards de paramètres – cette gamme vise une utilisation sur des machines grand public, allant du smartphone au MacBook Air. Les modèles existent en plusieurs variantes : Base (pré-entraîné), Instruct (optimisé pour le dialogue) et Reasoning (spécialisé dans les problèmes complexes). Leur atout majeur est leur rapport coût/performance, qui permet de bénéficier d’une IA performante sans infrastructure lourde. Sur un ordinateur portable, par exemple, Ministral 3-3B peut tourner en quantization 4 bits avec moins de 3 Go de RAM, générant environ 22 tokens par seconde.
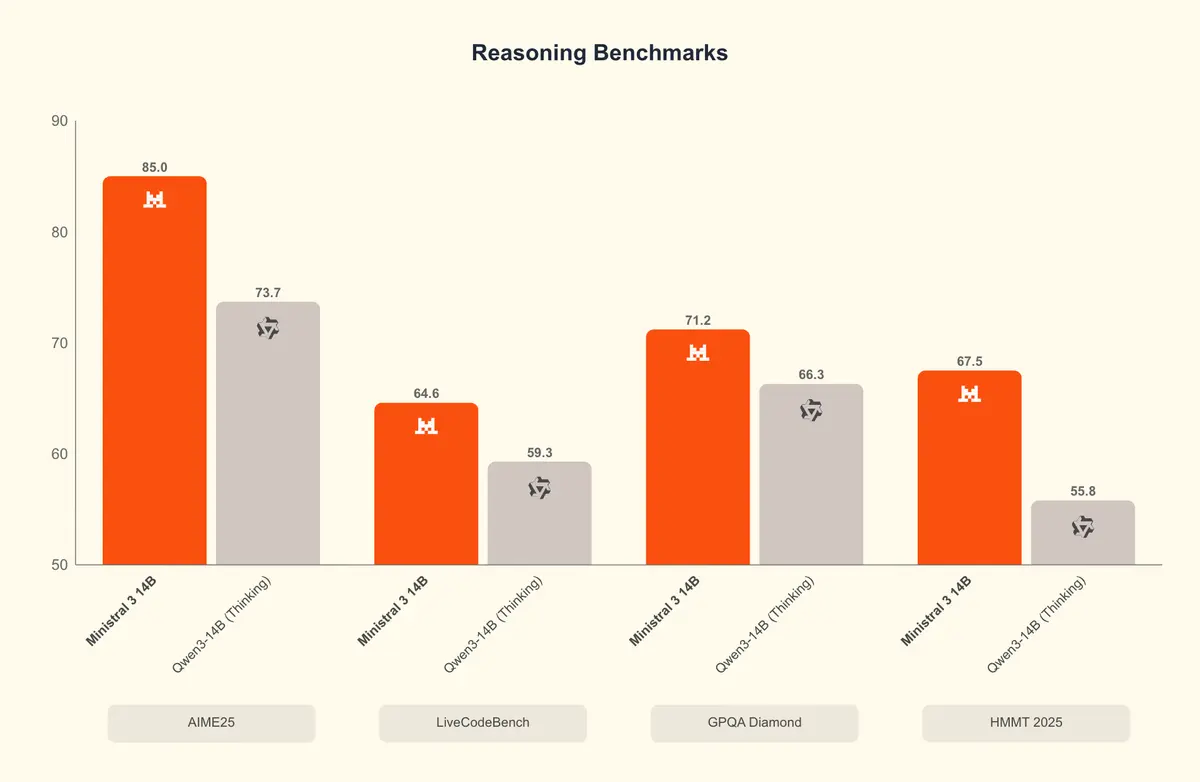
Cette double stratégie illustre la volonté de Mistral AI : proposer à la fois un modèle de pointe pour les usages industriels et des déclinaisons légères pour démocratiser l’IA. En misant sur l’open weight en Apache 2.0 et une exécution locale (dans votre datacenter pour Large 3, sur des devices ou une carte GPU pour les Magistral 3), la startup française se distingue de concurrents comme Meta ou DeepSeek, qui imposent des licences plus restrictives. Elle cible aussi un public non-anglophone, avec une attention particulière aux langues européennes, renforçant son ancrage culturel et stratégique.
Les modèles Mistral Large 3 et Ministral 3 sont immédiatement disponibles sur la Plateforme Mistral pour un accès API direct et sur Mistral AI Studio mais également sur Hugging Face, Amazon Bedrock, Azure Foundry, IBM watsonx, Modal, OpenRouter, Fireworks, Unsloth AI et Together AI. Ils seront très prochainement intégrés au portfolio NIM de Nvidia et à la solution AWS SageMaker.
Reste qu’il est désormais temps pour Mistral AI de simplifier son portfolio. Si les modèles spécialisés comme Mistral Embed, Codestral, Devstral, ou Voxtral sont clairement identifiables et identifiés, l’ensemble des autres modèles forment une nébuleuse complexe où de nombreuses variantes semblent désormais se chevaucher : Mistral Large, Mistral Small, Mistral Medium, Ministral, Magistral Small, Magistral Medium, Pixtral Large, Mistral Nemo, etc… Pas simple de s’y retrouver, même pour des développeurs expérimentés.
Au final, force est de reconnaître que les modèles Mistral Large 3 et Ministral 3 incarnent une certaine vision politique, éthique et économique de l’IA, souveraine, ouverte, distribuée et accessible, à même de soutenir la quête d’autonomie technologique de l’Europe dans le domaine de l’IA mais aussi à même d’inviter les DSI à réévaluer leur portfolio de modèles pour réduire les coûts et servir des applications critiques dans des secteurs très règlementés. Mistral AI est clairement toujours dans la course et la meilleure chance pour l’IA européenne d’exister et de briller à l’échelle mondiale.

 puis
puis