
APIs incomplètes, limites de débit, frais de sortie : l’éditeur d’intégration de données publie un scorecard public qui mesure à quel point les fournisseurs SaaS ouvrent – ou pas – l’accès aux données de leurs clients. Un sujet qui devient brûlant à l’heure où l’IA réclame des flux massifs et permanents.
Soyons clairs dès le départ. Fivetran n’est pas forcément l’acteur le plus impartial pour évaluer ce marché. Il y est trop impliqué. Mais c’est aussi sa force. Car en tant que plateforme américaine d’intégration de données (ELT), la plateforme extrait automatiquement les données des applications d’entreprise (CRM, ERP, marketing, finance, bases de données, etc.) pour les consolider dans des data warehouses ou un data lakes. Ce qui lui impose de disposer d’une multiplicité de connecteurs qu’elle déploie sous forme managée pour alimenter les socles analytiques et IA de ses clients (LVMH, Pfizer, Verizon ou… OpenAI). Du coup, les équipes de Fivetran sont directement confrontées à l’ouverture ou au manque d’ouverture des sources SaaS qu’il doit interconnecter.
L’éditeur annonce aujourd’hui l’ODI Data Access Benchmark, un comparatif public, accessible sur opendatainfrastructure.com, qui évalue la façon dont les grands fournisseurs de logiciels d’entreprise laissent (ou non) leurs clients accéder à leurs propres données. Le benchmark s’inscrit dans une démarche plus large baptisée Open Data Infrastructure (ODI), censée promouvoir une architecture où la donnée circule sans entrave entre les systèmes.
Un problème très concret pour les DSI
Une façon de rappeler à tous, et particulièrement aux DSI que les goulots d’étranglement ne se trouvent pas seulement dans la data platform interne, mais aussi chez les éditeurs SaaS en amont.
Selon Fivetran, trois verrous reviennent en permanence :
1 – des API incomplètes qui ne donnent accès qu’à une partie des objets de données ;
2 – des limites de débit qui plafonnent la vitesse de réplication à grande échelle, en particulier pour le Change Data Capture (CDC);
3 – des frais de sortie (egress) qui transforment tout déplacement massif de données en opération coûteuse.
On pourrait penser que dans un monde de platformisation, tout va en s’améliorant. Il n’en est rien. George Fraser, CEO de Fivetran : des coûts cachés, constate que « l’accès aux données devient plus restreint, à la fois sur le plan technique et commercial. Bien souvent, ces contraintes prennent la forme de coûts cachés ou de dépendances qui poussent les entreprises vers des écosystèmes fermés spécifiques. À mesure que l’IA devient plus centrale dans le fonctionnement des entreprises, celles-ci ont besoin d’une infrastructure de données ouverte qui leur donne la flexibilité d’accéder à leurs données, de les déplacer et de les utiliser sans enfermement propriétaire. »
Dit autrement, Fivetran s’inquiète d’un enfermement progressif dans des écosystèmes propriétaires qui entre en collision frontale avec une IA qui, par nature, a besoin d’aller chercher la donnée partout et à grande échelle. Et avec son Business. D’où l’idée de cet étonnant Benchmark !
Trois axes d’évaluation, à partir de la doc publique
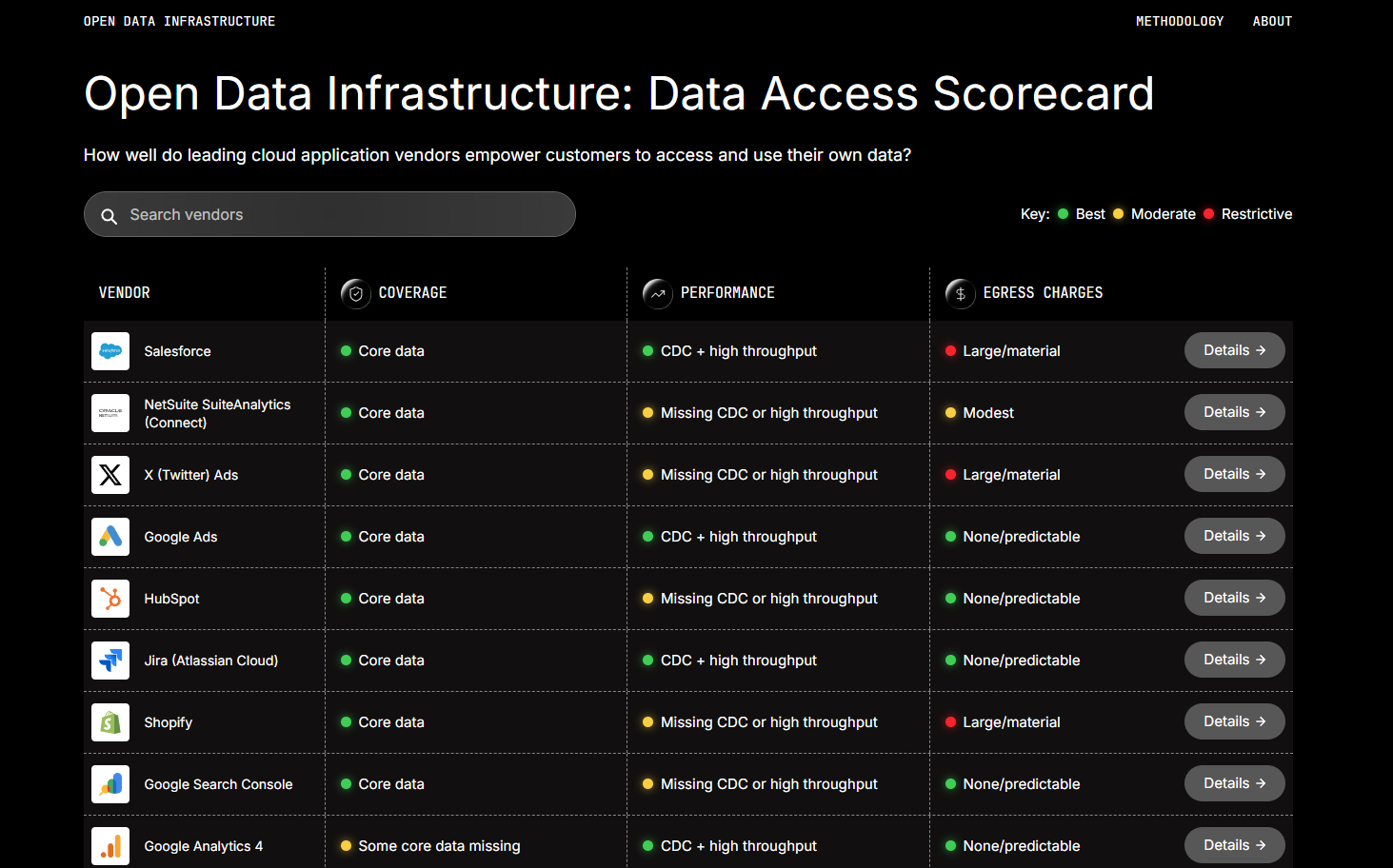
Concrètement, ce benchmark évalue la capacité réelle d’un éditeur à laisser sortir les données de façon exploitable, à cadence industrielle, et sans surtaxe pénalisante. Plutôt que d’attribuer un score global, il note chaque fournisseur sur trois dimensions, exclusivement à partir des capacités publiquement documentées :
* La Couverture : les objets de données essentiels sont-ils accessibles par programmation ?
* La Performance : l’éditeur prend-il en charge une réplication à haut débit, CDC inclus ?
* Les Frais de sortie : les données peuvent-elles être répliquées sans coût additionnel ni condition restrictive ?
L’idée est d’offrir aux entreprises une grille de lecture standardisée pour juger si leur stack actuelle peut vraiment suivre la mise à l’échelle IA, avant d’investir davantage ou de signer un nouveau contrat.
Juge et partie, mais cartes sur table
Bien sûr, Fivetran s’intègre à une bonne partie des acteurs qu’il note. L’éditeur l’assume. Il est juge et partie. Mais l’éditeur affirme que les scores sont établis à partir de la documentation publique, aucun fournisseur n’a payé ni influencé sa note, et le même cadre s’applique à tous – y compris aux partenaires commerciaux de Fivetran. La méthodologie complète est publiée en ligne et les notes seront actualisées au fil du temps, avec un élargissement prévu à de nouveaux fournisseurs et sources de données.
Pour l’instant, seuls 28 « vendeurs SaaS » sont officiellement évalués. Ce qui n’est qu’une infime partie des sources auxquelles la plateforme Fivetran se connecte. Parmi les éditeurs qui cochent favorablement les trois dimensions évaluées on retrouve des noms comme Google Ads, Jira, Stripe, Bing Ads et, dans une moindre mesure, Qualtrics.
Parmi les mauvais élèves, Slack combine des données cœur incomplètes, une absence de CDC/haut débit et des coûts d’egress importants. Workday ressort aussi assez mal avec certaines données cœur manquantes et pas de CDC/haut débit, même si le coût est seulement “modest”. Rippling n’est pas plus glorieux avec des données cœur manquantes et des coûts élevés, malgré de bonnes capacités de débit.
Parmi les très grands éditeurs d’entreprise, ceux qui posent le plus de questions aux DSI ne sont pas forcément les plus mauvais techniquement, mais les plus verrouillants économiquement. Salesforce en est le meilleur exemple : très bonne couverture et bonnes capacités de débit, mais coûts de sortie “large/material”. Même logique pour Marketo, QuickBooks, Xero, Shopify et SAP HANA, tous pénalisés surtout par l’egress.
Il ne reste plus à Fivetran qu’à poursuivre son effort et aux DSI et CDO à s’emparer de ce benchmark pour faire leur choix ou mener leurs négociations.
____________________________
Pour accéder au Benchmark : Open Data Infrastructure Scorecard

 puis
puis