
« Si nous n’avions pas mis votre ordinateur à genoux, pourquoi iriez-vous en acheter un autre ? » Cette expression connue sous le nom « d’aveu de Myrvol » n’a pas été le principal sujet de l’Hadoop Summit qui se déroule cette semaine à Bruxelles mais l’on ne pouvait s’empêcher d’y penser en écoutant les premiers utilisateurs, comme le responsable du projetde British gas, Dee Mitra, et d’autres intervenants.  Ils expliquaient comment désormais, grâce à Hadoop, ils manipulaient des téraoctets de données issus de milliers de sources comme de simples contenus de clé USB. Pour ceux qui auraient, par hasard, peu suivi la montée d’Hadoop, cette infrastructure logicielle est selon sa définition la plus connue, un framework Java open source destiné à faciliter la création d’applications distribuées. Celles-ci permettront de travailler avec des milliers de nœuds et des pétaoctets de données. C’est Google qui avait lancé sa définition et le principe avait été repris par Doug Cutting, en 2004, un ingénieur de Yahoo, passé chez Cloudera qui a développé l’essentiel d’Hadoop.
Ils expliquaient comment désormais, grâce à Hadoop, ils manipulaient des téraoctets de données issus de milliers de sources comme de simples contenus de clé USB. Pour ceux qui auraient, par hasard, peu suivi la montée d’Hadoop, cette infrastructure logicielle est selon sa définition la plus connue, un framework Java open source destiné à faciliter la création d’applications distribuées. Celles-ci permettront de travailler avec des milliers de nœuds et des pétaoctets de données. C’est Google qui avait lancé sa définition et le principe avait été repris par Doug Cutting, en 2004, un ingénieur de Yahoo, passé chez Cloudera qui a développé l’essentiel d’Hadoop.
La recherche de paternité va déboucher sur une bataille de normalisation
Depuis que les trois purs players d’Hadoop, Cloudera, Hortonworks et MapR font rêver les investisseurs, on se demandait comment les trois concurrents finiraient par tirer la couverture à eux, avant peut être de se « tirer » dessus, tout simplement. Si jusque-là chacun critiquait en sourdine le manque de respect des principes de l’open source par les autres, cette semaine, Hortonworks, a priori le plus fidèle à 100% aux développements Open Source du projet, à défini un périmètre du « vrai Hadoop ».
A l’occasion de ce sommet, Hortonworks, IBM et Pivotal ont annoncé que leurs plates-formes respectives Hadoop seraient toutes standardisées autour de la plate-forme Open Data (ODP) (voir notre annonce d’hier).
On se serait cru revenu à la fin des années 80 à la grande époque de la multiplication des interfaces sur Unix. On se gaussait à l’époque de ces chamailleries. « Ce qu’il y a de bien avec les standards, c’est qu’il y en a beaucoup entre lesquels on peut choisir. » L’objectif est cependant louable, un même noyau Apache devrait éviter les incompatibilités de versions. Mais force est de constater que les » accessoires » sont en train de s’éloigner les uns des autres.
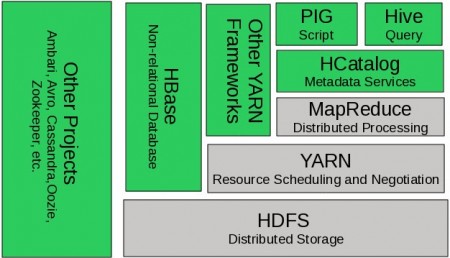
la base d’Hadoop 2.6
Pré-annoncée lors d’une première réunion en février dernier, l’ODP possède un noyau constitué de Hadoop 2.6 (celui de novembre 2014), y compris HDFS (stockage), Yarn le centre de la gestion interactive des données et MapReduce (gestion des processus), ainsi que du logiciel Apache Ambari on puisse gérer les extensions physiques des environnements Hadoop. Si parmi les membres de l’initiative ODP ne figurent pas (encore ?) les deux grandes figures d’hadoop, Cloudera et MapR, on retrouve donc au delà d’Hortonworks et IBM : Infosys, Pivotal, SAS, et Altiscale, Capgemini, CenturyLink, EMC, General Electric, PLDT, Splunk, Teradata, Verizon, VMware et WANdisco.
Pour Tim Hall, le vice-président produit (photo)de Hortonworks a bien voulu répondre à nos questions.
«L’adoption d’un noyau commun pour Hadoop va renforcer l’ interopérabilité d’Hadoop. On reste dans la logique de la fondation Apache en progressant pas à pas. On ne vend rien de propriétaire et l’on ne touche pas de droits de licences. Cloudera a adopté une approche peu conventionnelle pour l’open source tel que nous l’envisageons. Ils fournissent leur propre distribution avec un tas d’améliorations propriétaires ». Si Cloudera était visée pour cette dernière remarque, la porte n’est pas fermée. « On étudie de prés le sujet » expliquait des intervenants à nos confrères allemands mais Cloudera dispose déjà d’une programme concurrent d’Ambari pour intégrer des environnements hétérogènes et celui-ci est plus développé qu’Ambari. Les intervenants de MapR étaient plus discrets. Au-delà de ce rassemblement, la nouvelle la plus intéressante était l’annonce du rachat par Hortonworks du petit éditeur Hongrois Sequence IQ dont l’intérêt est de lui offrir deux projets opensource qui simplifieront l’installation et le provisionnement d’Hadoop dans le cloud. Appellés Cloudbreak et Periscope, ces deux outils ont étés développés au-dessus de Yarn, le gestionnaire de ressources de données, et d’Ambari, la plateforme de provisionning, de gestion et de monitoring des clusters.
Cloud Break permet justement de provisionner sur différents environnements Cloud (Azure,AWS,etc) des espaces et des configurations prépackagées sur différents serveurs. On choisit un support dans le cloud et on lance HPD ( Hortonworks developpment plaftform) et cela marche ( voir image ci-dessous). « La difficulté c’est toujours d’ajouter des nœuds, des processeurs et que le système s’agrandisse (scale out) en fonction des besoins. Avec Ambari on dispose d’un nouveau système d’alertes et de métriques pour la surveillance des clusters et l’on fournit maintenant des outils plus visuels pour l’analyse et le tunning des applications Tez et Hive. Avec Periscope, on peut ajouter des nœuds de travail selon une politique bien définie » 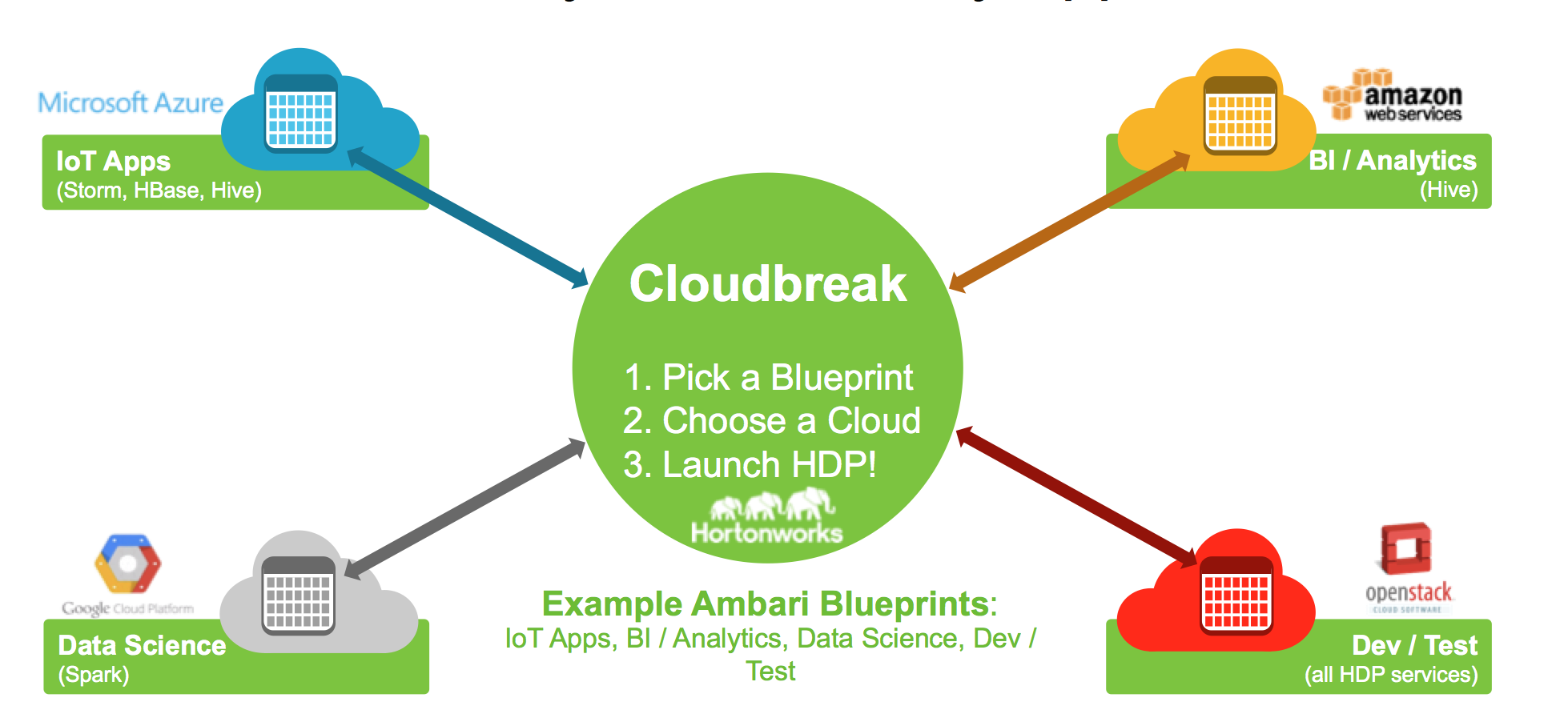 précisait Tim Hall. L’approche Ambari va sûrement progresser avec l’arrivée comme CTO de Scott Gnau, jusque-là président de Teradata Labs. Toujours à Bruxelles, Pivotal annonçait la sortie de Genfire, une nouvelle base de données distribuée (In Memory à base d’open source).
précisait Tim Hall. L’approche Ambari va sûrement progresser avec l’arrivée comme CTO de Scott Gnau, jusque-là président de Teradata Labs. Toujours à Bruxelles, Pivotal annonçait la sortie de Genfire, une nouvelle base de données distribuée (In Memory à base d’open source).
Tim Hall a aussi souligné l’avantage d’avoir une technologie prête pour Docker, de grandes entreprises ayant déjà démarré des tests, des PoC (proof of concept). Elles ont aussi déployé des clusters Hadoop avec Cloudbreak.
Un peu plus tôt, Herb Cunitz, président d’Hortonworks, avait indiqué que la société réalisait 15 à 20% de ses facturations clients sur le marché européen et que le rachat de séquences IQ renforcait les équipe locales. EMC, Microsoft et SAP ont aussi marqué leurs présences en montrant différentes passerelles vers le monde SQL. Tim Hall à ce propos précisait : « Microsoft a fourni un travail fantastique pour accélerer les requêtes SQL et les rendre compatibles avec l’environnement Haddoop .» Interrogé sur l’avenir d’Hadoop et le remplacement à terme des bases de données, Andy Leaver responsable des opérations internationales nous indiquait : « Les économies espérées et la richesse d’un framework open source comme Hadoop le rend incontournable. IBM, SAP, SAS, tout le monde (the old world) s’y met. Ce matin, un des intervenants avait derriere lui un panneau sur lequel était marqué : « Hadoop n’est pas une option ». C’est ce que tous les participants suggèrent. De notre côté, nous fournissons des services pro 24/24, 7 jours sur 7 dans toutes les langues, notre expertise en développement est reconnue ». Hortonworks introduite en bourse depuis un trimestre paraît surfer sur une vague énorme. Pour l’instant, ce sont les grandes entreprises comme celles des services publics comme les « utilities » ( gaz, oil,distributions) qui y voient leur intérêt immédiat. Mieux vaut brasser des téraoctets de données .

 puis
puis