
Simplivity, après les fabricants Xcale et Nutanix, parie sur l’apparente simplicité d’une solution associant la virtualisation à la fois pour le stockage et le traitement des applications.
Simplicité, c’est aussi le nom que l’on aimerait leur donner, à ces solutions « miracles ». Celles qui nous promettent qu’au lieu d’acheter séparément les serveurs, le stockage, les logiciels de réplication, la déduplication des données, les sauvegardes, la technologie d’accélération WAN, on fera tout d’un seul coup. Le data center « in a box », tout prêt à utiliser, est séduisant. Il a, pour nous, au moins l’avantage de rappeler que la sécurité des données, les backups et la déduplication ne sont pas des accessoires.
L’exemple du rayon surgelés
Pour l’utilisateur, à l’instar des pâtes à tartes « toutes prêtes » de votre épicerie, l’informatique de l’entreprise pourra ainsi se concentrer ensuite sur l’essentiel, l’applicatif. C’est un peu l’argument des vendeurs de Cloud, en général. On ne s’occupe plus de l’infrastructure, on se focalise sur les « apps » des utilisateurs et les processus métiers. Les intégrateurs d’ailleurs ne s’y trompent pas. Ils n’ont plus à perdre des heures de paramétrages et d’installation, avec ces petites boîtes, ils n’ont plus qu’à chercher les prises disponibles de 220 volts. Il faut toujours aussi, bien sûr, identifier les connecteurs optiques du réseau pour brancher leurs derniers boîtiers « à la mode », paramétrer l’adressage du système et entrer les mots de passe adéquats, mais l’essentiel est fait. Vendre dans la foulée quelques heures de paramétrages leur sera plus facile. Le temps perdu dans la découverte de nouvelles fonctions obscures de virtualisation ne sera plus un sujet de discussion
Pour l’hébergeur, lorsqu’il faut augmenter la capacité ou les performances des serveurs, il suffira selon les trois vendeurs, d’ajouter d’autres boîtiers. Le groupe de ressources partagées ainsi constitué serait homogène. Chacun d’entre eux ne sera plus en gros qu’un empilement de serveurs x 86 standard, virtualisé avec Vmware ou KVM, et enrichi des composants logiciels maison. Pour Joël Molo, l’ancien directeur de Palo Alto networks, devenu le représentant de Simplivity en France, la firme pourra à terme ne vendre que ses logiciels et sa carte accélératrice : « Ce sera possible à partir d’un très grand marché de plusieurs centaines de machines mais l’intérêt de notre solution Omnicube est justement d’éviter les paramétrages. » Les OmniCubes sont utilisés pour les entreprises qui utilisent VMware pour leurs serveurs et la virtualisation de bureau, en particulier parce qu’ils regroupent plusieurs technologies dans une seule boîte.
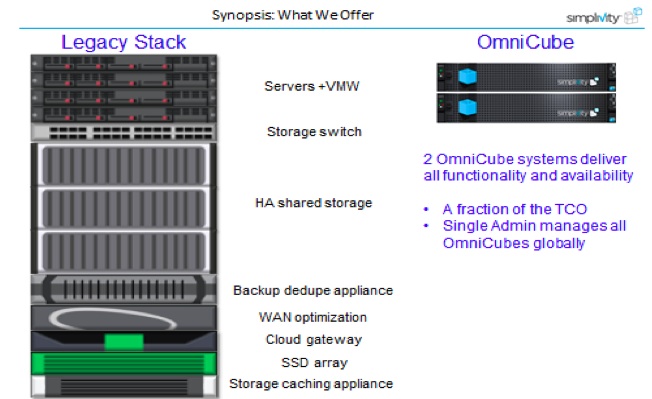
Moins de données à traiter pour un même univers
Interrogé sur la concurrence avec Nutanix qui utilise aussi la virtualisation de Vmware, Joël Mollo précisait : « On n’est pas tout à fait sur le même créneau ; on pourrait même être complémentaires. Eux sont intéressants pour la sauvegarde et le réseau et nous sur la déduplication. » Les redondances entre fichiers sont identifiées au moment de la sauvegarde par les agents installés sur les serveurs, au niveau de blocs de données. Pour Joël Molo, « la « dédup » est l’argument phare de Simplivity, elle permet d’économiser l’espace de stockage mais aussi de soulager le réseau et d’accélérer les sauvegardes ou les restaurations ; du coup la puissance globale du Datacenter est plus grande car ils consomme mois de ressources.
Néanmoins, certains logiciels comme Oracle ont fait aussi du contrôle des « doublons » une obsession. Il ne sera pas facile d’obtenir beaucoup d’améliorations pour celles-ci.
Enfin les fabricants de baies de stockage comme EMC ou Netapp disposent dans les contrôleurs disques eux-mêmes des fonctions de déduplications « depuis la maternelle ». Interrogé sur les perspectives de machines gérant la déduplication, un expert en gestion des achat de matières premières, grand utilisateur d’oracle Financial (qui préfère ne pas être cité) nous rappelait : « l’avantage présumé de la déduplication, cela me rappelle qu’il y a quelques années, les grandes bases de données étaient déjà surnommées systèmes GIGO (garbage in-garbage out, ce qui peut être traduit par « foutaises en entrée, foutaises en sortie »), et le problème n’a fait que s’aggraver à mesure qu’on reliait « toutes» les bases de données ; une situation que l’on retrouve encore avec le Big data. Mais sur le fond, sans sourire, ces nouvelles boîtes dites converged servers ne font que reproduire le modèle de Google qui a crée un moyen « d’agglomérer » de la puissance de traitement en fonction de ses besoins. Cela va dans le sens des datacenters qui prospèrent sur les effets de standardisations. C’est une évolution qui va dans le sens de la simplification et c’est un argument puissant. »

 puis
puis