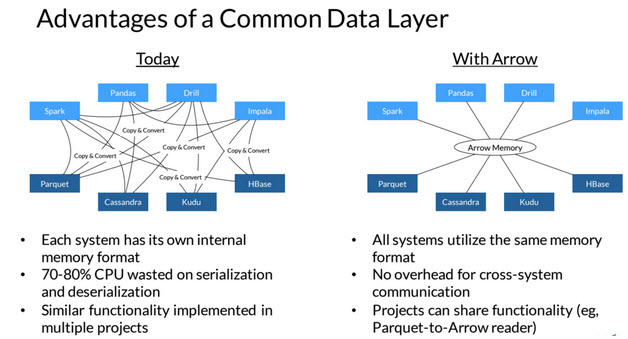
L’initiative Arrow vient d’être élevée au niveau de projet complet au sein de la fondation Apache. Cette technologie a pour objectif d’améliorer les performances des différents composants d’un projet big data qui fonctionnent ensemble. Une amélioration qui n’est pas à la marge mais de l’ordre d’un facteur 10, voire 100. Arrow jouera le rôle de plaque-tournante des échanges facilitant la communication entre les différents modules. Il créera une sorte de représentation interne et commune de telle sorte qu’il ne sera pas nécessaire de faire une copie et une conversion en passant d’un composant Spark par exemple à un composant Cassandra.
Arrow s’appuie aussi sur une base de données orientée colonnes qui peut être traitée directement en mémoire[1] dans des systèmes comme HANA de SAP ou Spark de la Fondation Apache. Arrow utilise aussi le format de données JSON (JavaScript Object Notation) qui permet de représenter de l’information structurée comme le permet XML par exemple. Ce projet est soutenu par la société Demio qui était également derrière le projet Drill. Le code est disponible pour une implémentation en C, C++, Python et Java et devrait l’être rapidement dans les langages R, Javascript et Julia.
Ce projet montre la maturité de l’univers big data autour de la planète hadoop qui concentre une partie de ses efforts sur la notion de performance. Bénéficiant à l’ensemble des différents composants, Arrow a réuni les représentants de 13 projets open source : Calcite, Cassandra, Drill, Hadoop, HBase, Ibis, Impala, Kudu, Pandas, Parquet, Phoenix, Spark and Storm. Ce soutien de poids lui permettra d’avancer plus rapidement, en particulier en sautant la phase imposée habituellement d’incubation et d’avoir le statut de projet de haut niveau dans la fondation Apache.
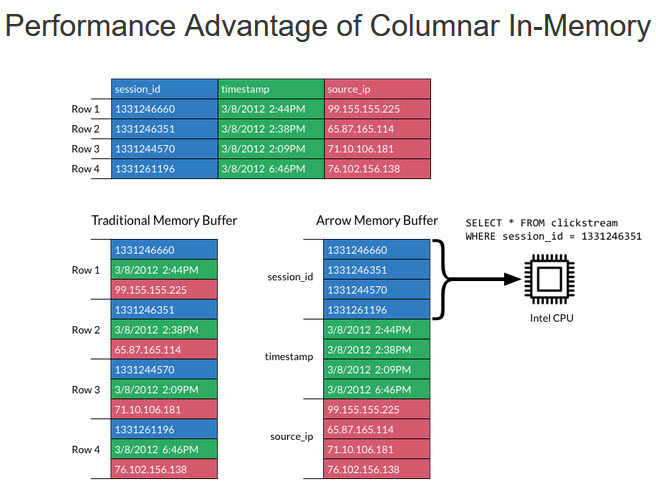
[1] Une base de données qui stocke les données par colonne et non par ligne. L’orientation colonne permet d’ajouter des colonnes plus facilement aux tables (les lignes n’ont pas besoin d’être redimensionnées). Elle permet de plus une compression par colonne, efficace lorsque les données de la colonne se ressemblent (source Wikipedia).

 puis
puis