
Google disposait déjà avec Imagen 3 d’un puissant modèle de génération d’images, très apprécié en entreprise. Tout comme OpenAI et sa génération d’images intégrée à « GPT-4o », Google lance une fonctionnalité « image » dérivant du modèle « Gemini 2.5 » pour non seulement générer des images mais aussi les retoucher.
Google annonce le lancement de « Gemini 2.5 Flash Image », un modèle d’édition et de génération d’images dès aujourd’hui intégré à l’app Gemini (web et mobile) mais également proposé aux développeurs via l’API Gemini, Google AI Studio et Vertex AI.
Alors que son précédent modèle Imagen 3 était focalisé sur la génération d’images, « Gemini 2.5 Flash Image » est plus proche dans ses capacités de l’IA GPT-Image d’OpenAI ou de Flux.1 Kontext. Ce modèle permet en effet de réaliser des retouches fines pilotées en langage naturel, tout en préservant l’identité visuelle des sujets (visages, animaux, objets) et en fusionnant plusieurs photos dans une même scène.
Au-delà du simple « text-to-image », le modèle gère des éditions multi-étapes et des transformations locales : changer un fond, supprimer un élément, modifier une pose ou appliquer le style d’une image sur un objet d’une autre, sans dégrader le reste de la photo. « Nous faisons avancer la qualité visuelle et la capacité du modèle à suivre les instructions », souligne Nicole Brichtova, product lead chez Google DeepMind. Elle ajoute que les sorties sont désormais « plus utilisables » car les retouches sont mieux intégrées.
Côté performances, le modèle – que Google a testé sous le nom de code « nano-banana » sur la plateforme LMArena – s’est hissé directement en tête du classement communautaire dédié à l’édition d’images. Google confirme qu’il s’agit bien du même modèle que celui évalué anonymement. Ce nouveau modèle IA démontre en effet une maturité accrue sur des cas d’usage exigeants : il est capable de maintenir la cohérence d’un personnage sur une série de rendus, de créer des essais de design produit sous de multiples angles, ou de créer des rendus vraiment homogènes pour tous les visuels d’une marque.
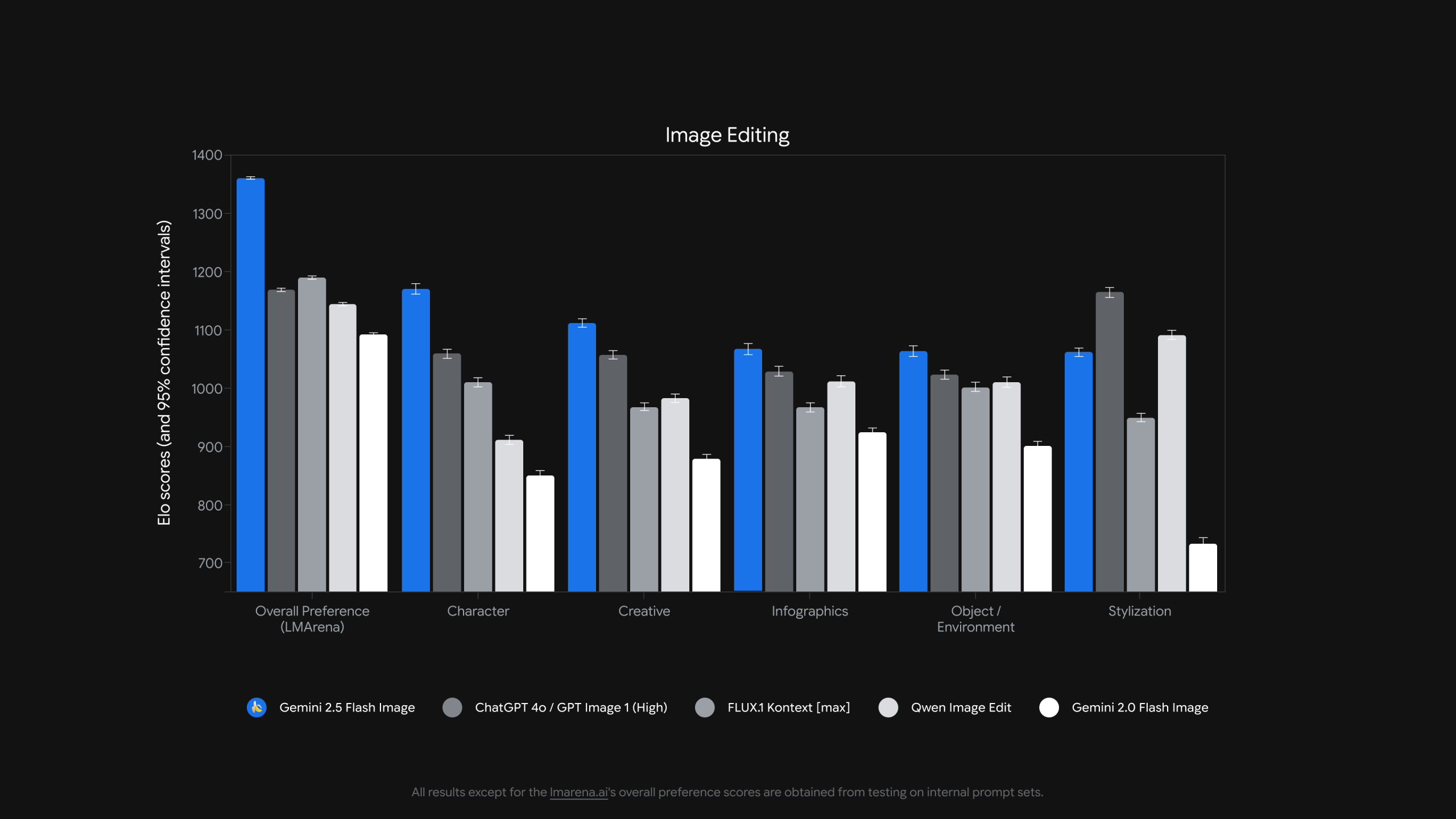
En pratique, Gemini 2.5 Flash Image vise une grande variété de besoins y compris les usages « pro » en entreprise : itérer des maquettes en gardant la même identité visuelle, prévisualiser l’aménagement d’un espace, créer des supports cohérents ou produire des variantes localisées. Pour des DSI, ce lancement marque moins une course aux effets visuels qu’un pas vers des workflows maîtrisables : granularité des retouches, traçabilité par marquage, coûts prévisibles et intégration rapide dans les outils existants.

Côté usages personnels, le modèle est disponible dans l’application Gemini en sélection « Gemini 2.5 Flash » et en cochant l’option « image ». Il suffit alors de demander en langage naturel de « créer une image de style cartoon humoristique », de « changer le costume d’une personne sur la photo », de « placer cette personne ou cet animal dans tel ou tel lieu », de « fusionner plusieurs photos pour créer une nouvelle scène », de « peindre les murs d’une pièce vide et d’y ajouter des meubles », d’« appliquer le style de telle image à une scène de telle autre image », etc.

Sur le plan de la conformité et de la traçabilité, toutes les images créées ou éditées portent un filigrane visible et un marquage invisible SynthID. Google rappelle par ailleurs l’interdiction des contenus non consentis dans ses conditions d’usage. Après les controverses de l’hiver dernier, l’éditeur assure avoir durci ses garde-fous tout en conservant de la latitude créative. Pour des organisations sensibles à la réputation et à l’intégrité documentaire, ces mécanismes facilitent l’implémentation de contrôles internes (reconnaissance des contenus générés, politiques d’usage).
L’édition/génération d’images est facturée 30 $ par million de tokens en sortie, chaque image (jusqu’à 1024×1024) consomme 1 290 tokens, soit environ 0,039 $ par image. Le modèle est en preview dans l’API et AI Studio, avec stabilisation annoncée « dans les prochaines semaines ». Google met également en avant des intégrations et gabarits prêts à l’emploi dans AI Studio pour accélérer les prototypes.
De quoi permettre aux particuliers de créer des montages photographiques bluffants et aux entreprises d’intégrer dans leurs applications marketing des fonctionnalités de génération d’images plus aisément gouvernables et économiques et ainsi tester des usages « créatifs » plus accessibles sans lâcher la bride sur la conformité et le risque réputationnel.

 puis
puis