
OpenAI signe un tournant avec Codex-Max : un modèle qui pense, code, teste et refactore comme un ingénieur logiciel infatigable. Avec GPT-5.1-Codex-Max, l’IA agentique ne se contente pas de taper du code, elle dirige des chantiers logiciels entiers durant des heures si nécessaire. L’ère du « dev sans pause » vient de débuter.
OpenAI Codex est à la fois un outil Web de développement par IA, un agent IA spécialisé dans le développement et l’ingénierie logicielle (capable d’écrire, de corriger, et de tester du code de manière autonome dans des sandbox isolées) et une famille de modèles orientés vers le codage.
Il est loin d’être le seul. GitHub Copilot Agent Mode en fait de même en proposant le choix entre différents modèles IA de développement, Claude Code est le concurrent direct proposé par Anthropic, Google dispose de Jules (et d’Antigravity), etc.
La guerre se joue au niveau des capacités agentiques mais également au niveau des modèles IA qui animent ces agents. Et jusqu’ici Claude Code était souvent considéré comme le plus pertinent.
Histoire de reprendre la main, OpenAI a lancé ces derniers jours son nouveau modèle GPT-5.1-Codex-Max, nouvel avatar de sa famille Codex. Il se démarque notamment par une étonnante faculté à animer un véritable agent logiciel capable de tenir la distance sur des tâches longues, complexes, multi-fichiers, au point de travailler de manière autonome plus de 24 heures sur un même chantier de code.
Ce n’est pas un simple changement de version, c’est carément un glissement de paradigme : avec des agents aussi autonomes, on passe d’outil de complétion de code qui aide le développeur au fil de l’eau à un « chef de chantier » numérique, capable d’orchestrer des refactorings de grande ampleur, de suivre des boucles CI/CD et de refermer des tickets à la chaîne.
De l’autocomplétion à l’« agentic coding »
Techniquement, GPT-5.1-Codex-Max est présenté comme un « frontier agentic coding model », construit sur une mise à jour du modèle de raisonnement GPT-5.1 et entraîné sur des tâches réelles d’ingénierie logicielle : création de pull requests, revue de code, développement frontend, réponses techniques, etc.
La clé de ce changement de catégorie tient dans un mot : « compaction ». Là où les modèles classiques se heurtent à la limite de contexte, Codex-Max est nativement entraîné pour travailler sur plusieurs fenêtres de contexte successives et pour résumer lui-même l’historique en conservant l’essentiel. En pratique, le modèle est capable d’opérer sur des millions de tokens pour un même chantier, en compactant régulièrement la session pour repartir sur une fenêtre « fraîche » mais contenant l’essentiel des éléments utiles des fenêtres précédentes afin de ne jamais perdre le fil du projet.
Résultat : des scénarios qui, hier, faisaient exploser les limites deviennent possibles. OpenAI met en avant des refactorings de dépôt complet, des sessions de débugging profond et des boucles d’agents multi-heures, voire multi-journées. En interne, l’éditeur dit avoir observé des runs de plus de 24 heures, au cours desquels le modèle itère sur ses propres implémentations, corrige les tests et finit par livrer une solution jugée exploitable.
Des gains mesurables sur les benchmarks… et sur les pipelines
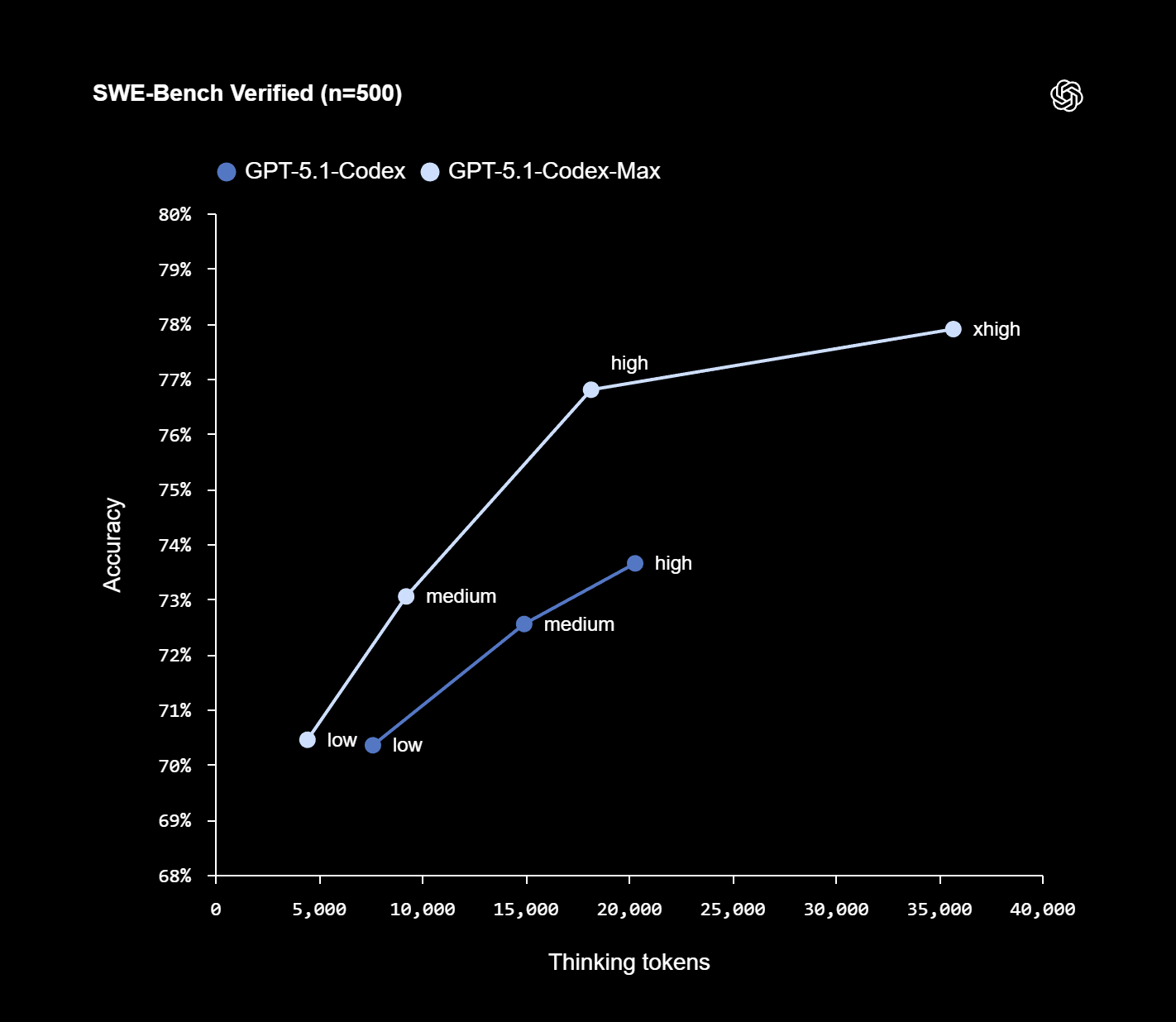
Sur le papier, GPT-5.1-Codex-Max coche évidemment les cases des benchmarks. Sur SWE-Lancer, un test conçu pour simuler de vrais tickets d’ingénierie logicielle, le modèle atteint 79,9 % de réussite, contre 66,3 % pour la génération précédente en mode « high ». Sur SWE-bench Verified, il obtient de meilleurs scores que GPT-5.1-Codex à niveau de raisonnement équivalent, tout en consommant environ 30 % de tokens de « réflexion » en moins.
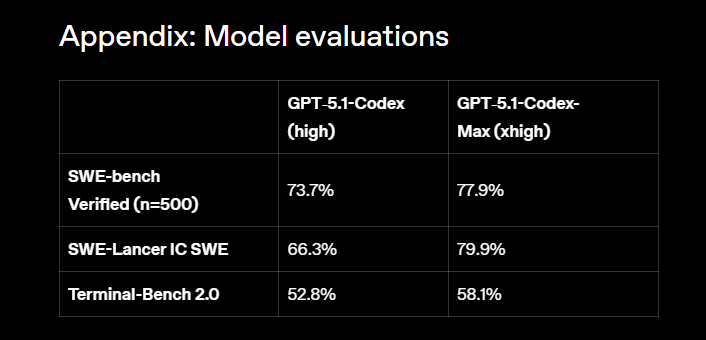
Derrière ces chiffres, OpenAI insiste sur un point qui parlera aux DSI : la productivité globale de ses propres équipes. Selon l’éditeur, 95 % de ses ingénieurs utilisent désormais Codex chaque semaine, et depuis l’adoption de l’écosystème, ces équipes livreraient environ 70 % de pull requests en plus.
Codex-Max n’est pas qu’un modèle « nu ». Il est disponible dans toute la surface Codex : CLI, extension IDE (VS Code), cloud, code review, et doit arriver prochainement en API.
C’est aussi – et c’est très nouveau et remarquable – le premier modèle d’OpenAI entraîné pour opérer nativement dans des environnements Windows, ce qui le rend beaucoup plus pertinent pour des stacks historiques .NET, des scripts PowerShell et des parcs serveurs encore très liés à l’écosystème Microsoft.
Et cela ouvre des cas d’usage très concrets : refonte d’un module de facturation pendant la nuit, nettoyage d’un monolithe vieillissant, migration progressive d’un socle on-prem vers des micro-services, industrialisation de la rédaction de tests unitaires et d’intégration, stabilisation d’un pipeline CI/CD capricieux… Autant de sujets qui, traditionnellement, consomment des sprints entiers et mobilisent des équipes difficiles à recruter. Ici, Codex peut faire en autonomie l’essentiel du travail faisant économiser un temps précieux aux équipes et réduisant significativement le coût de tels projets.
Un agent plus fiable, mais qui reste à encadrer
En parallèle des performances, OpenAI met en avant des progrès sur la robustesse et la réduction des hallucinations. Grâce à une meilleure efficacité de raisonnement, le modèle converge plus rapidement et évite davantage les impasses logiques, un point critique quand on lui confie des modifications massives sur un dépôt de production.
Mais plus l’agent gagne en autonomie, plus la question de la gouvernance devient centrale. GPT-5.1-Codex-Max est présenté comme le modèle le plus avancé d’OpenAI en matière de cybersécurité, tout en restant en-deçà du niveau « High capability » (qui oblige à des mesures de précotions spécifiques) dans le cadre du Preparedness Framework interne de l’éditeur.
Mais OpenAI reste très prudent dans son approche et son déploiement avec un modèle confiné par défaut dans un bac à sable, des écritures disque limitées à son workspace et un accès réseau coupé tant que le développeur ne l’a pas explicitement activé.
OpenAI insiste d’ailleurs sur un principe que les DSI devront graver dans leurs chartes internes : Codex doit être traité comme un relecteur additionnel, pas comme un substitut à la revue humaine. Logs de terminal, citations de tests, traces de tool calls sont fournis pour faciliter l’audit, mais la responsabilité finale de mise en production reste du côté de l’équipe.
Vue du côté des DSI, l’arrivée de GPT-5.1-Codex-Max est à la fois une promesse et un avertissement. Une promesse, parce qu’un agent capable de tenir 24 heures sur un chantier de code change l’économie des refactorings, des migrations et du traitement de la dette technique. À condition d’avoir des dépôts structurés, des tests suffisamment denses et des pipelines maîtrisés, il devient possible d’automatiser des pans entiers de travaux « ingrats » que les équipes repoussaient de sprint en sprint.
Un avertissement, parce que cette nouvelle génération de modèles pousse encore plus loin la tentation du « pilotage automatique ». Un agent qui sait modifier des centaines de fichiers, manipuler des scripts d’infrastructure, toucher à des configurations de sécurité ou de conformité ne peut pas être laissé sans garde-fous. Il faut des règles de jeu claires : périmètres autorisés, environnements de test isolés, stratégies de review et de rollback, journalisation détaillée, voire séparation stricte entre ce que l’agent peut faire en direct et ce qui nécessite une validation explicite. Ce qui oblige à redéfinir des cadres stratégiques au plus vite avant que les développeurs ne se laissent tenter et multiplient les usages d’un tel agent.
GPT-5.1-Codex-Max est disponible dès aujourd’hui et destiné à remplacer l’ancien GPT-5.1-Codex. Il devient le modèle par défaut de Codex, accessible depuis les offres ChatGPT Plus, Pro, Business, Edu et Enterprise.
Avec ce modèle, les agents IA d’ingénierie logicielle font un nouveau pas en avant. Aux DSI, désormais, de décider jusqu’où ils veulent leur confier les clés de leurs usines logicielles… et d’organiser les contrôles pour que ce nouveau « collègue » surhumain reste un allié, pas un facteur de risque supplémentaire.

 puis
puis