





Proposer un système de gestion de base de données open source adapté aux volumes des données produites par l’Internet des objets, tel est l’objectif apparemment simple que s’est fixé la société Crate.io.
Créé en 2014 à Berlin avant de s’installer à San Francisco à la fin 2016 pour bénéficier de l’écosystème, notamment financier, Crate.io développe une base de données qui associe les technologies SQL et une architecture NoSQL qui soit adaptées aux données structurées et non structurées temps réel produites par le nouveau monde de l’Internet des objets. Et pour répondre aux fluctuations du volume des données, cette base doit être largement scalable. Jusqu’ici les configurations maximales en production comportent une centaine de nœuds mais Crate.io a monté des configurations de 1000 nœuds sur le cloud d’Azure de Microsoft fonctionnant sans problème.
Le défi que s’est lancé Carte.io n’est pas mince et vise à remplacer des technologies qui ont fait leur preuve : MySQL, Postgres et Oracle pour des raisons de performance et de coûts et des bases NoSQL comme Cassandra, Elastic Splunk, ou Mongo DB pour des raisons de facilité d’utilisation et d’intégration et la capacité d’écrire des requêtes ad hoc.
Crate.io a choisi le modèle open source et affiche un million de téléchargements avec un millier de clusters utilisant la base de données et une cinquantaine de clients payants.
Les bases de données analytiques ont connu trois grandes périodes selon Christian Lutz, fondateur et CEO de Carte.io. Dans les années 2003-2006, avec les premiers développements des acteurs du Web, sont apparus les bases distribuées à colonnes telles que Vertica, Splunk, Greenplum ou Big Table développé par Google. Les bases de données analytiques se sont alors imposées pour traiter des volumes de données jusqu’ici inconnues. Ce fut ensuite l’arrivée des bases de données dites NoSQL dans le sillage du développement des technologies cloud et mobiles et des containers.
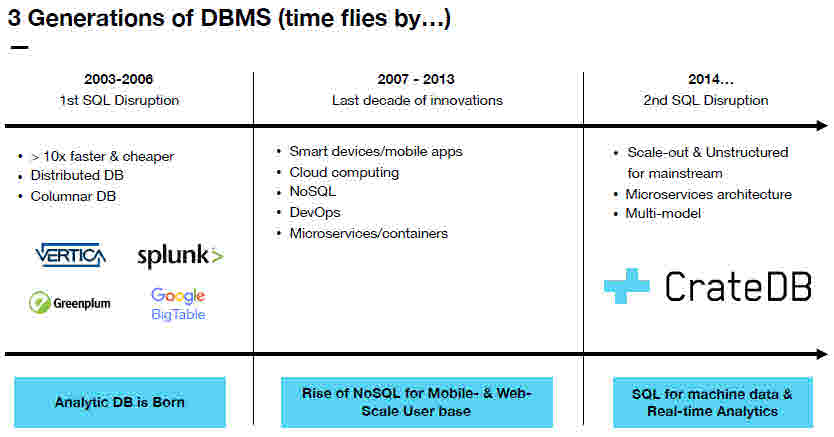
La troisième étape est caractérisée par l’explosion des données non structurées, des architectures scale-out. Et c’est dans ce contexte qu’a été développé CrateDB par la société Crate.io. Avec CrateDB, Crate.io fait la synthèse entre une base de données distribuée fondée sur une architecture NoSQL tout en pouvant exploiter les recherchées en langage SQL. La scalabilité de CrateDB s’appuie notamment sur sa capacité à utiliser les microservices et les containers tels que Docker, Kubernetes ou Mesos et ainsi d’évoluer en fonction du volume des données et du nombre de nœuds, sachant que tous les nœuds participant à la configuration sont égaux. Les données sont alors distribuées en fonction de l’évolution de la configuration.
CrateDB a été spécialement conçues pour les données produites par toutes sortes d’objets connectés : capteurs, wearables, équipements industriels, véhicules connectés, supervision de réseaux et d’infrastructure, machine learning… Parmi les applications, la maintenance prédictive des équipements industriels figure au premier plan grâce à la capacité de superviser toutes les activités en temps réel. C’est actuellement la majorité des applications utilisant cette base de données. Selon Christian Lutz, CrateDB est utilisée pour remplacer des solutions existantes car MySQL et Elasticsearch chez Skyhigh Network ou dans une première installation pour prendre en charge des problèmes nouveaux. Outre le volume, les données produits peuvent être de nature très différente : structurées, non structurées, géolocalisées, séries temporelles, JSON…
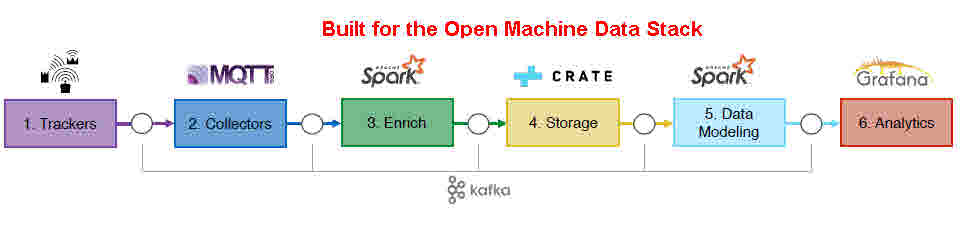
Une des caractéristiques de CrateDB est de tenir la charge. Un véhicule connecté par exemple génère 2000 enregistrements par seconde soit plus de 100 milliards par jour. En tant que solution Open Source, CraDB s’inscrit dans une solution complète allant du suivi et de la collecte des données jusqu’à leur traitement en temps réel.
A ce jour, CrateDB a levé un peu plus de 6 M$ et reconnait être au début d’une nouvelle histoire. En 2017, elle devra développer sa présence aux Etats-Unis et passer le cap de l’industrialisation.

 puis
puis