
À Cloud Next 2026, Google a levé le voile sur la 8ème génération de ses Tensor Processing Units (TPU). Particularité : elle se décline désormais en deux puces spécialisées, l’une pour entraîner les modèles, l’autre pour les faire tourner. Une stratégie qui en dit long sur la maturité de l’hyperscaler dans le développement d’accélérateurs IA maison.
Cela fait désormais 10 ans que Google forge son propre processeur accélérateur d’IA. En 2016, lors de Google I/O, Sundar Pichai révélait l’existence des TPU, des puces conçues en interne pour accélérer TensorFlow. Elles tournaient déjà depuis 2015 dans les datacenters du géant pour booster Search, Translate, Photos ou encore Street View.
Depuis, sept générations se sont succédées, chacune plus ambitieuse que la précédent. C’est sur ces TPU que Google a entraîné et déploie aujourd’hui Gemini, son arsenal de modèles maison. La 7ème génération, Ironwood, n’a qu’un an. Mais la 8ème arrive déjà, preuve que Google considère désormais la course au silicium IA comme stratégique au même titre que ses modèles.
Les hyperscalers, tous fabricants de puces
Certes, Google n’est plus seul sur ce terrain. AWS a industrialisé Trainium (entraînement) et Inferentia (inférence), et y a ajouté ses CPU ARM Graviton. Microsoft pousse ses Maia (IA) et Cobalt (CPU). Meta développe ses MTIA. Alibaba assume ses Hanguang. Tous ces acteurs partagent un ennemi commun, ou plutôt un fournisseur incontournable, Nvidia, dont la capitalisation flirte désormais avec les 5 000 milliards de dollars.
Alors pourquoi investir des milliards dans une R&D silicium maison quand on peut acheter du Nvidia ? Parce que l’équation économique change radicalement à l’échelle hyperscale. D’abord, les volumes internes gigantesques amortissent largement les coûts de développement. Ensuite, co-designer la puce avec le réseau, le refroidissement et même le modèle permet des gains d’efficacité énergétique spectaculaires. Or dans des datacenters désormais limités non plus par l’approvisionnement en puces mais par le courant disponible, chaque watt compte. Enfin, se libérer partiellement de la taxe Nvidia améliore les marges. Attention toutefois : aucun hyperscaler ne substitue intégralement les GPU Nvidia. Google lui-même proposera les futurs Vera Rubin dans son cloud et collabore même avec Nvidia autour de la technologie réseau Falcon. Les puces maison viennent compléter l’offre, pas la remplacer.
Une 8ème génération… en deux puces
Jusqu’à présent, chaque génération de TPU jouait le rôle du couteau suisse : entraîner les modèles géants la nuit, les servir aux utilisateurs le jour. Mais les besoins ont divergé. D’un côté, entraîner un modèle frontière demande une puissance de calcul brute monumentale. De l’autre, servir des agents IA qui dialoguent, raisonnent et s’appellent entre eux en continu exige avant tout une latence minimale et beaucoup de mémoire rapide. Google a donc décidé de couper la poire en deux.
Amin Vahdat, SVP et Chief Technologist IA & Infrastructure de Google, explique que ces puces sont en développement depuis deux ans, à une époque où les agents n’étaient même pas au cœur des conversations.
On rappellera qu’AWS semble un peu avoir pris le chemin inverse. Lors du dernier AWS Re:Invent 2025, l’hyperscaler a plutôt choisi de mettre sa puce Trainium3 à toutes les sauces et a largement évoqué son successeur le Trainium4 sans jamais évoqué d’éventuel successeur à sa puce Inferentia2.
Petite pause lexicale : qu’est-ce qu’un « pod » chez Google ?
Avant d’entrer dans le dur, clarifions ce mot qui va revenir souvent. Chez Google Cloud, un pod désigne un supercalculateur unifié composé de milliers de TPU interconnectés par un réseau maison ultra-rapide (souvent basé sur des commutateurs à circuits optiques). L’astuce : de l’extérieur, ce pod se comporte comme une seule et même machine, avec une gigantesque piscine de mémoire partagée dans laquelle un modèle géant peut nager à son aise. Plus le pod est grand, plus on peut y entraîner des modèles démesurés sans avoir à découper artificiellement leurs paramètres entre plusieurs serveurs indépendants. C’est la signature architecturale de Google.
TPU 8t : la brute pour l’entraînement
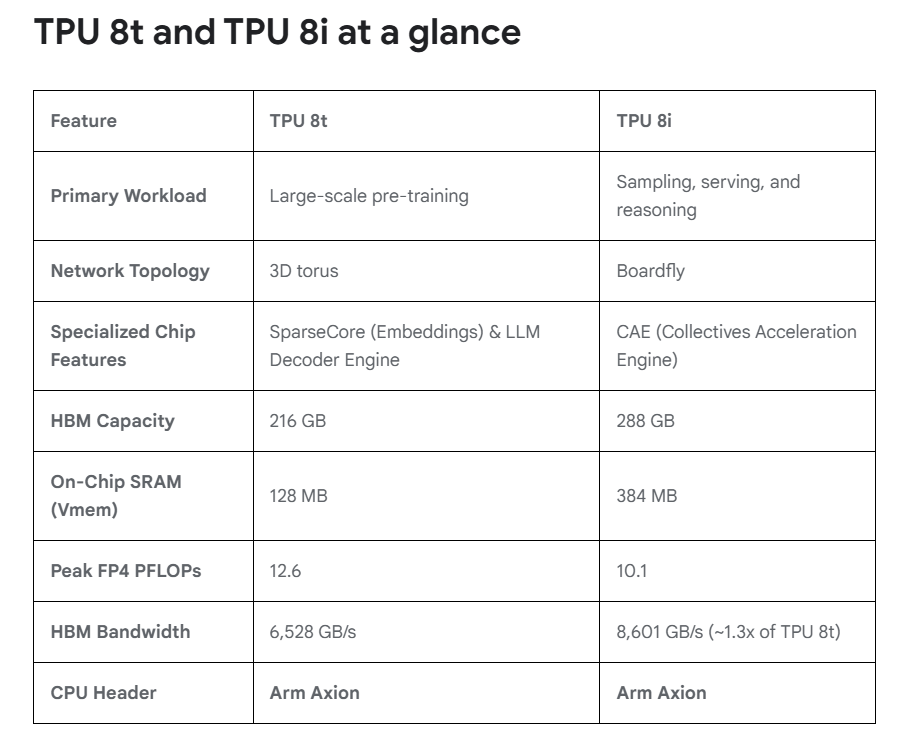
La première des deux puces, la TPU 8t (le « t » pour training); est taillée pour dérouler des cycles d’entraînement colossaux. Chaque puce embarque 216 Go de HBM à 6,5 To/s, 128 Mo de SRAM et délivre jusqu’à 12,6 petaFLOPS en FP4. Jusque-là, les GPU
Les puces Nvidia Rubin font mieux en individuel. Mais Google joue sur un autre terrain : celui de l’assemblage. Un pod TPU 8t regroupe 9 600 puces pour 2 Po de mémoire partagée et 121 ExaFLOPS de compute. Et grâce au nouveau tissu réseau Virgo (annoncé à Google Cloud Next), combiné aux frameworks maison JAX et Pathways, Google affirme pouvoir connecter jusqu’à un million de TPU 8t dans un seul cluster logique réparti sur plusieurs datacenters.
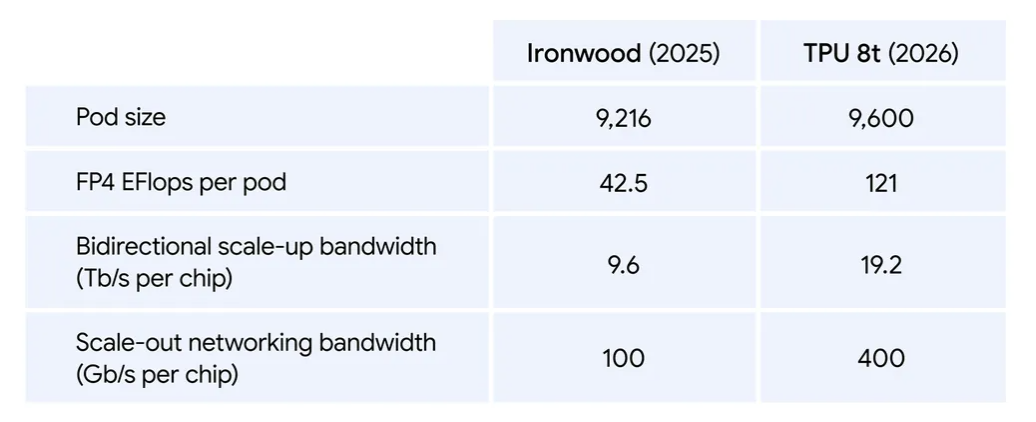
Autre chiffre à retenir : Google vise un « goodput » de 97 %, soit le pourcentage de temps réellement consacré à de l’entraînement utile une fois retirés les pannes, les reprises sur checkpoint et les ralentissements réseau. À l’échelle frontière, chaque point compte : cela représente littéralement des jours de calcul récupérés. Au total, un pod TPU 8t offrirait près de 2,8× les performances d’un pod Ironwood.
TPU 8i : le sprinter pour l’inférence
La seconde puce, la TPU 8i (pour inference) répond à une autre logique. L’inférence, surtout lorsqu’elle sert des essaims d’agents qui s’appellent en boucle, dépend moins de la puissance brute que de la bande passante mémoire et de la latence inter-puces. Google a donc troqué un peu de compute (10,1 petaFLOPS FP4) contre 288 Go de HBM à 8,6 To/s et 384 Mo de SRAM embarquée, soit trois fois plus que la génération précédente. Objectif : garder le KV cache (la mémoire de travail du modèle) directement sur la puce pour éviter que les cœurs tournent dans le vide en attendant les données.
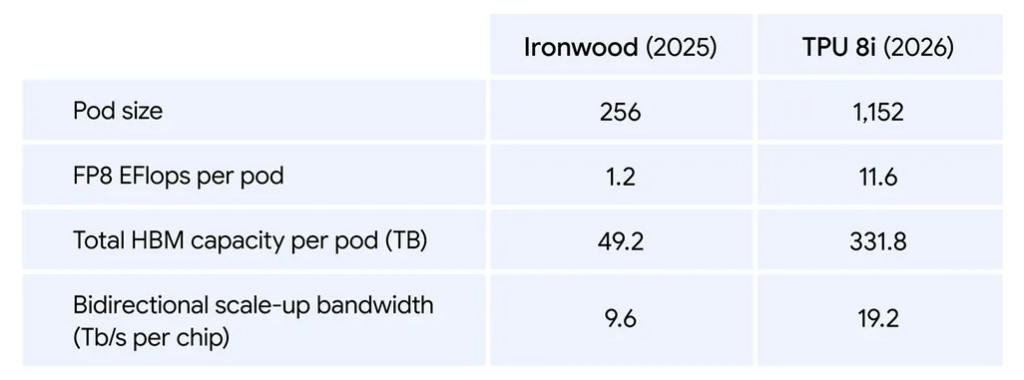
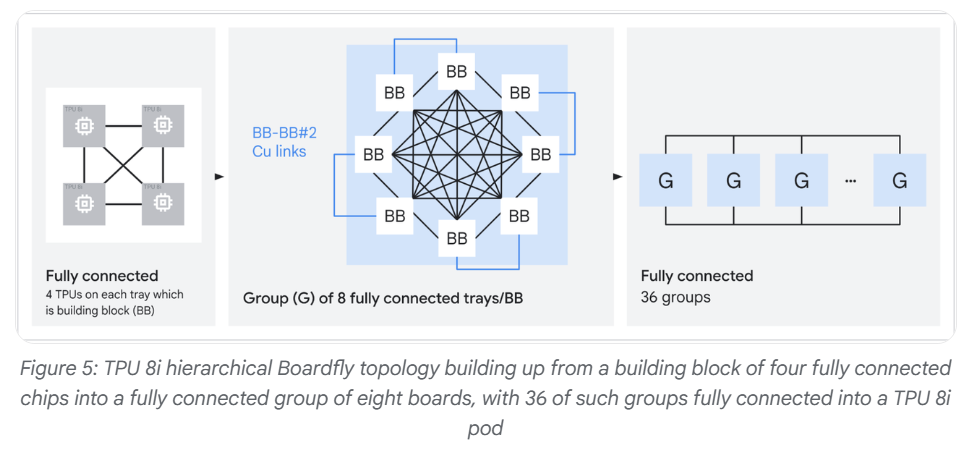
Google a également repensé la façon dont les puces se parlent entre elles. Jusqu’ici, elles étaient organisées en « tore 3D », une sorte de grille où l’information devait parfois faire jusqu’à 16 étapes pour aller d’une puce à une autre. Avec la nouvelle topologie baptisée Boardfly, ce trajet maximal tombe à 7 étapes — presque deux fois moins de chemin à parcourir, donc des réponses plus rapides. Un atout majeur pour les modèles dits « Mixture of Experts » (MoE), qui fonctionnent comme une équipe de spécialistes : chaque question est envoyée à quelques experts répartis sur différentes puces, qui doivent constamment se coordonner. Google ajoute à cela un accélérateur dédié, le Collectives Acceleration Engine (CAE), qui divise par cinq les délais quand les puces doivent synchroniser leurs résultats. Bilan : 80 % de performance par dollar gagnés face à Ironwood, soit presque deux fois plus d’utilisateurs servis à coût égal.
Axion partout, x86 à la porte
Détail intéressant : pour la première fois, les deux TPU sont associées exclusivement aux CPU hôtes Axion de Google, des processeurs ARM maison. Exit les Xeon ou EPYC sur les serveurs TPU. Un choix qui fait écho à la stratégie d’AWS, qui a marié ses Trainium 3 à ses Graviton plus tôt cette année. Là encore, l’intérêt est de co-optimiser l’ensemble du système, de l’accélérateur jusqu’à la gestion mémoire NUMA.
Côté sobriété, Google revendique jusqu’à 2× les performances par watt par rapport à Ironwood, grâce notamment à sa quatrième génération de refroidissement liquide et à une gestion d’énergie dynamique à l’échelle du pod. Un argument qui tombe à propos alors que Microsoft prévoit 1,3 milliard d’agents IA en production d’ici 2028 — soit autant de besoins en inférence continue.
Disponible d’ici la fin de l’année
Les TPU 8t et 8i seront accessibles plus tard cette année, soit sous forme d’instances Google Cloud, soit via AI Hypercomputer, la plateforme intégrée de Google qui bundle compute, réseau, stockage et logiciels. Les frameworks natifs (JAX, MaxText, PyTorch, SGLang, vLLM) sont tous supportés, avec un accès bare metal possible pour les clients les plus exigeants.
En distinguant ainsi entraînement et inférence, Google confirme ce que le marché pressentait : l’ère du processeur IA universel touche à sa fin. Place à la spécialisation avec en filigrane une conviction partagée par tous les hyperscalers : qui contrôle le silicium contrôle l’économie de l’IA.
____________________________

 puis
puis