
Le salon Big Data qui se tenait au CNIT de la Défense les 10 et 11 mars a été l’occasion de mieux connaître les premiers distributeurs d’Hadoop, le fer de lance du Big data.
Cloudera mais aussi Hortonworks et MapR sont les trois premiers distributeurs du logiciel Open Source Hadoop qui stimule, de l’avis général, le renouveau de ce secteur qui, depuis plus de 20 ans reposait sur l’analyse de bases de données, le datamining, l’ETL ou l’analyse de données, selon l’angle que l’on veut lui donner. Pour ceux qui n’ont pas eu le temps de regarder cette évolution rappelons qu’Hadoop a été conçu, selon la définition la plus répandue « pour stocker de très gros volumes de données sur un grand nombre de machines équipées de disques durs banalisés ». Il permet l’abstraction de l’architecture physique de stockage, et permet de manipuler un système de fichiers distribués comme s’il s’agissait d’un seul disque dur. Il reprend les principes présentés en 2004 par Google pour expliquer les principes de son système de fichier en cluster, le « Google FS » mais aussi son algorithme basé sur des opérations analytiques à grande échelle sur un grand nombre de serveurs.
Une bonne approche d’Hadoop est détaillée dans l’interview du patron de MapR ((https://www.informatiquenews.fr/m-c-srivas-mapr-hadoop-va-devenir-standard-donnees-20704)
Romain Picard, le directeur Europe de Cloudera, (photo), présent à l’expo nous précisait que sa firme était la première distribution historique d’Hadoop et qu’elle avait l’intention d’entrer en bourse en 2016. Elle avait été aussi la première à compléter la distribution avec différents outils. « On a deux logiciels complémentaires Cloudera manager et Cloudera Navigator qui facilitent l’adoption d’Hadoop .»  Interrogé sur la raison qui avait permis à Cloudera de devenir, en terme de chiffre d’affaires, la première distribution, celui ci répondait : «On est très soutenu par la communauté Apache qui est à la base d’Hadoop. Le support d’Intel qui a investi près de 750 millions de dollars dans notre dernière levée de fond tout en nous confiant une partie des développements a pesé aussi très lourd. Cela a favorisé l’utilisation de nos produits dans des appliances comme ceux de HP, Dell, Fujitsu, Netapp, Teradata. Il existe des milliers d’applications qui ont été poussées par près de 1200 partenaires et SSI comme Cap Gemini, Accenture, CGI, Octo Technology. Des sociétés de BI comme Qlik, tableau software Cognos ou SAS nous recommandent. On a fait plus de 100 millions de dollars en 2014 et l’on travaille avec plus de 500 clients et je ne parle que des versions payantes car s’il l’on ajoutait tous les téléchargements qui servent à étudier des projets en amont, on pourrait parler de milliers. On est devenu ainsi le socle commun de la plus grande base Hadoop. »
Interrogé sur la raison qui avait permis à Cloudera de devenir, en terme de chiffre d’affaires, la première distribution, celui ci répondait : «On est très soutenu par la communauté Apache qui est à la base d’Hadoop. Le support d’Intel qui a investi près de 750 millions de dollars dans notre dernière levée de fond tout en nous confiant une partie des développements a pesé aussi très lourd. Cela a favorisé l’utilisation de nos produits dans des appliances comme ceux de HP, Dell, Fujitsu, Netapp, Teradata. Il existe des milliers d’applications qui ont été poussées par près de 1200 partenaires et SSI comme Cap Gemini, Accenture, CGI, Octo Technology. Des sociétés de BI comme Qlik, tableau software Cognos ou SAS nous recommandent. On a fait plus de 100 millions de dollars en 2014 et l’on travaille avec plus de 500 clients et je ne parle que des versions payantes car s’il l’on ajoutait tous les téléchargements qui servent à étudier des projets en amont, on pourrait parler de milliers. On est devenu ainsi le socle commun de la plus grande base Hadoop. »
Hortonworks, la premiere à être entrée en bourse
Hortonworks, pour sa part, ne propose aucune extension logicielle différente et base l’essentiel de ses revenus sur la vente et le service autour de sa plate-forme HDP et sur la formation. La firme a mis récemment en avant le fait que l’essentiel du temps des utilisateurs était utilisé pour le nettoyage des données, plutôt que pour leur exploitation. Un discours repris par la jeune firme française Dataiku qui proposait des T-shirt aux Geeks du salon avec l’inscription en Anglais : « je ne suis pas un laveur de données » pour mettre en avant les fonctions de simplification qu’elle propose.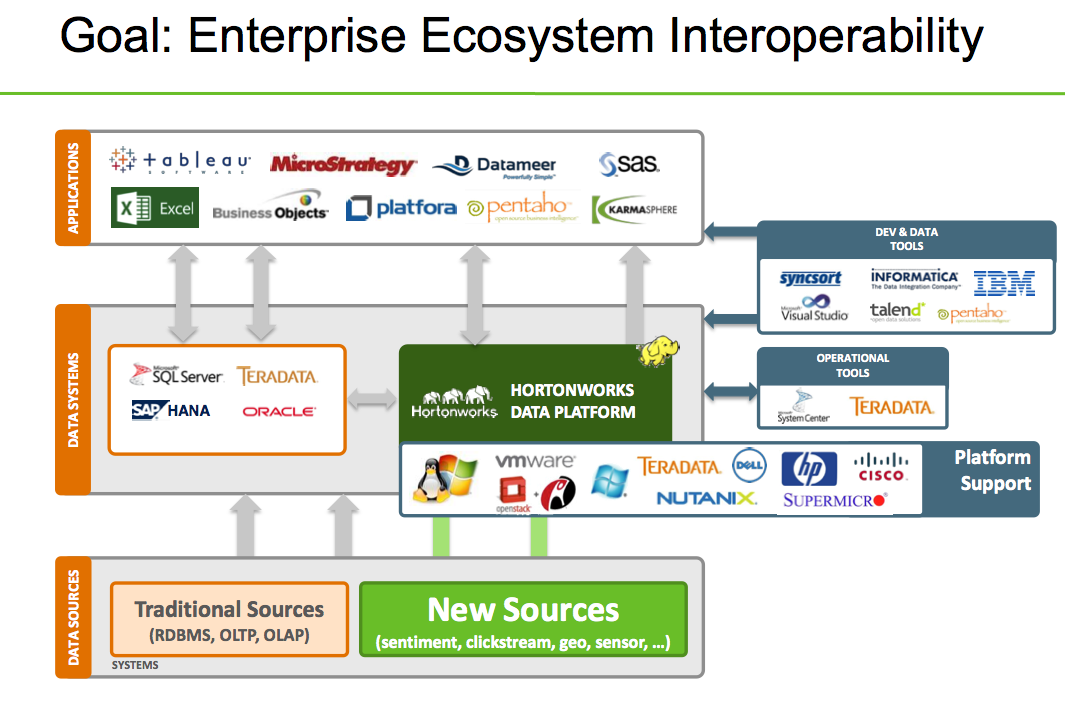
Hortonworks faisait d’ailleurs sur son stand l’apologie de la version 2.1 et de l’importance de Yarns, le système « d’exploitation » des données, lié à l’arrivée d’Hadoop 2.0 (schéma ci dessous) qui permet de couper la cordon entre HDFS (Hadoop Distributed File System) et les différentes sources de données pour mieux les exploiter. 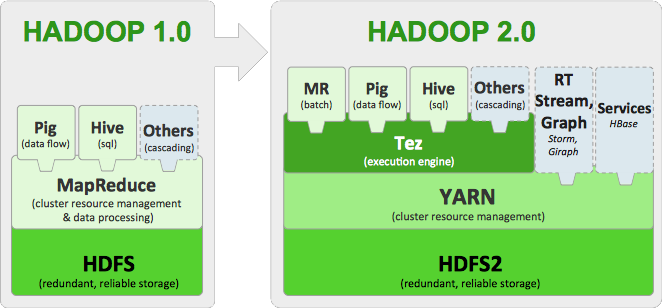 Entrée en bourse en décembre dernier, la firme annonce 40 millions de dollars de chiffre d’affaires pour 2014 et revendique 300 clients dont une trentaine en France parmi lesquels Edf et Canal+. Elle aussi met en avant son intéropérabilitée aisée avec les logiciels d’autres firmes, du fait du respect de l’Hadoop « initial ».
Entrée en bourse en décembre dernier, la firme annonce 40 millions de dollars de chiffre d’affaires pour 2014 et revendique 300 clients dont une trentaine en France parmi lesquels Edf et Canal+. Elle aussi met en avant son intéropérabilitée aisée avec les logiciels d’autres firmes, du fait du respect de l’Hadoop « initial ».
MapR en accord avec ATOS
La firme dispose d’un bureau Français depuis mars 2013.
MapR a, rappelons-le, développé un système de fichier MapR high availability (HA) pour Hadoop palliant les limites du HDFS. 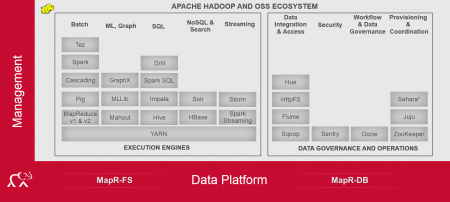 Lors du salon Big Data elle a mis de ce fait en avant ses fonctions de sauvegarde sur différents environnements. Autre sujet « chaud », à la suite d’un accord avec Atos pour la plateforme Hadoop dite en Self-Service, les échanges entre les deux stands étaient nombreux. Xavier Guerin, VP EMEA Alliances et Partenaires de MapR, expliquait lors du lancement de ce service l’intérêt de ces développements communs : « Le modèle libre-service proposé par ATOS est extensible, il permet de partager les données et d’intégrer les demandes des équipes études et développement, celle des architectes, et équipes d’exploitation.»
Lors du salon Big Data elle a mis de ce fait en avant ses fonctions de sauvegarde sur différents environnements. Autre sujet « chaud », à la suite d’un accord avec Atos pour la plateforme Hadoop dite en Self-Service, les échanges entre les deux stands étaient nombreux. Xavier Guerin, VP EMEA Alliances et Partenaires de MapR, expliquait lors du lancement de ce service l’intérêt de ces développements communs : « Le modèle libre-service proposé par ATOS est extensible, il permet de partager les données et d’intégrer les demandes des équipes études et développement, celle des architectes, et équipes d’exploitation.»
Bref, hormis Hortonworks qui défend une forme d’intégrisme de la version Open source, tous les acteurs renforcent l’offre actuelle avec d’intéressants compléments et modules accessoires. L ‘imagination est parfois dans la profusion.

 puis
puis