
Fondée en 2011, MapR est l’une des trois startups les plus en vue du mouvement hadoop et big data. Créée en 2011, MapR a bénéficié à ce jour d’un financement de 160 M$ et fait état de plus de 1000 entreprises clientes. M.C. Srivas, CTO et co-fondateur présente sa vision et explique pourquoi hadoop va devenir le standard de la gestion des données.
InformatiqueNews : MapR et hadoop ne sont pas encore familiers des DSI. Pouvez-vous nous raconter la genèse de votre entreprise qui est un des principaux acteurs sur ce marché ?
M.C. Srivas : L’histoire d’hadoop remonte aux premiers temps de la recherche sur Internet. Au milieu des années 90, de nombreuses entreprises comme Inktomi, Ask Jeeves, Altavista et bien d’autres travaillaient à développer une technologie de recherche sur Internet donnant des résultats probants. Mais aucun moteur ne produisait quelque chose de satisfaisant. Pour sa part, Yahoo était parti sur une idée étrange de classification manuelle. Puis, Google est arrivé et a réussi le tour de force à développer un moteur de recherche sur Internet de très bonne qualité. Pour cela, ses ingénieurs ont développé une technologie capable de traiter des volumes de données considérables car les solutions conventionnelles n’étaient pas du tout adaptées.
A cette époque, j’avais participé à la création de la société Spinnaker Networks, rachetée ensuite par NetApp et spécialisée dans le développement d’appliances NFS. J’ai ensuite rejoint Google pour travailler les techniques de recherche sur Internet et nous utilisions notamment MapReduce, GFS et BigTable, des technologies développées en interne. Pendant ce temps, Yahoo avait compris qu’il était dans une impasse et a racheté Inktomi pour essayer de rattraper son retard dans les moteurs de recherche. Ses développeurs n’étaient pas satisfaits du produit open source Nutch qu’ils utilisaient et se sont mis à développer sous la houlette de Doug Cutting ce qui deviendra par la suite hadoop avec l’aide de Google. Google possédait tous les brevets mais a choisi de poursuivre les développements en mode open source et en confiant le projet à la fondation Apache et en continuant à le sponsoriser.
IN : hadoop est donc intimement lié à Internet ?
M.C. Srivas : A ce moment-là, d’autres entreprises sur Internet ont été créées dont Facebook ou Twitter avec les mêmes contraintes de traiter des volumes considérables de données. D’autres éditeurs de réseaux sociaux, disparus depuis, se sont lancés comme MySpace et Orkut avec les mêmes problématiques. Puis, les agences publicitaires sur Internet ont eu besoin de cibler beaucoup plus précisément leurs messages, toujours à partir d’importants volumes de données. Les smartphones se développèrent avec des besoins similaires. Puis le commerce électronique explosa. C’est ensuite que les entreprises traditionnelles commencèrent à s’intéresser au big data, la finance, la distribution, les éditeurs de logiciels, les sociétés de transports et d’énergie. Aujourd’hui, MapR a environ un millier de clients dont la moitié hors du secteur Internet.
 IN : Quand avez-vous eu l’idée de fonder MapR ?
IN : Quand avez-vous eu l’idée de fonder MapR ?
M.C. Srivas : En 2008, la crise financière est arrivée et c’est toujours un bon moment pour créer une startup car les budgets R&D dans les entreprises sont plus ou moins gelés et donc il est possible de se démarquer et de prendre un peu d’avance. J’ai alors utilisé l’expertise que j’avais acquise avec Spinnaker Networks, notamment dans la qualité du stockage des données. En 2011, nous avons annoncé notre gamme de produits. Aujourd’hui, MapR est proposé en trois versions : M3, M5 et M7[1].
IN : Quand avez-vous eu l’idée d’aller à l’international ?
M.C. Srivas : Cela fait environ deux ans. Nous nous sommes d’abord implantés au Japon, puis en Inde et en Corée du Sud. Nous sommes venus ensuite en Europe – Royaume-Uni, France, Allemagne et aussi les pays nordiques. Nous sommes aujourd’hui dans de très nombreux pays.
IN : Pensez-vous qu’hadoop va remplacer les bases de données traditionnelles ou va-t-il les compléter ?
M.C. Srivas : hadoop va remplacer les SGBD traditionnels qui sont nés avec les données structurées et raisonnent en lignes et colonnes. D’ici à 5 à 10 ans, de nombreuses bases Oracle, Microsoft ou IBM seront remplacées. Hadoop n’était pas conçu pour traiter des données structurées mais il peut le faire, il est vrai avec des performances encore nettement moins bonnes que les SGBDR. Mais ces derniers bénéficient de 25 ans d’optimisation. Dans 5 ans, hadoop devrait être aussi performant. D’autant que le nombre de spécialistes qui travaillent sur hadoop est peut-être dix fois plus élevé que celui des bases conventionnelles. Les SGBD constituent une industrie de renouvellement, hadoop est une activité nouvelle qui va drainer tous les financements. Par ailleurs, hadoop peut s’inspirer de l’expérience dans le développement des SGBD, ce qui a marché et ce qui n’a pas marché et ainsi les erreurs. Pour l’anecdote, Oracle utilise hadoop pour traiter toutes ses données qui proviennent d’Internet.
Autre point important, les SGBDR ont été conçus pour des données dont le ratio lecture/écriture est sans doute 80/20 et n’est plus du tout adapté à la réalité d’aujourd’hui où ce ratio s’est plus qu’inversé. Tout le monde publie un blog que personne ne lit, 80 % des mails sont des spams et ne sont pas lus, 80 % des vidéos sur Internet ne sont regardées que par celui qui l’a publié… Sans parler des données qui vont être produites par des machines dans le cadre de l’Internet des objets.
Quant aux fournisseurs IT traditionnels, ils devront maîtriser les technologies hadoop. Cela passera donc par des développements internes ou, plus probablement, par des rachats ou une combinaison des deux.
IN : hadoop évolue dans le monde open source. Une étude du cabinet Forrester plaçait les trois pure players hadoop – Cloudera, HortonWorks et MapR – avec la meilleure offre. Comment vous positionnez-vous par rapport aux deux autres ?
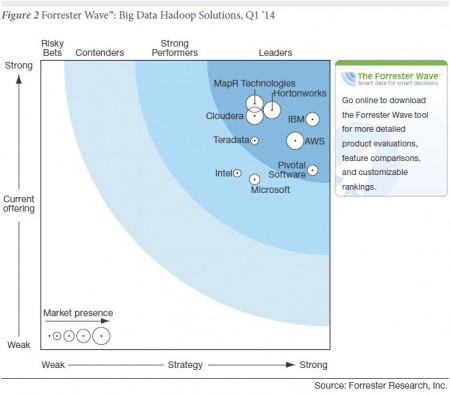
 M.C. Srivas : Les trois entreprises ont levé beaucoup d’argent[2] car les enjeux sont très élevés : il s’agit de bâtir le prochain standard de bases de données. Pour comparer les trois concurrents que vous mentionnez, on peut utiliser une analogie dans le domaine des systèmes d’exploitation. Dans le monde Linux, vous avez trois principaux fournisseurs de distribution : Debian, Ubuntu et Red Hat. Debian est le produit de choix si vous travailler sur le développement Linux. Si vous voulez utiliser Linux sur un portable en tant qu’utilisateur peu familier des technologies, Ubuntu est le produit de choix. Grâce à de nombreux ajouts en matière d’administration, d’outils pour faciliter l’installation, la configuration, l’utilisation, cloudera est le produit hadoop le plus simple d’utilisation. Au niveau du data center, Red Hat Linux est le système le mieux adapté. Pour des besoins comparables en matière de gestion des données, MapR est le mieux placé en termes de coûts, de fiabilité, de performances… Par ailleurs, il apporte la qualité de NetApp ou d’EMC au niveau la gestion des données à hadoop. Les trois produits sont de très bonne qualité mais répondent à des problématiques différentes.
M.C. Srivas : Les trois entreprises ont levé beaucoup d’argent[2] car les enjeux sont très élevés : il s’agit de bâtir le prochain standard de bases de données. Pour comparer les trois concurrents que vous mentionnez, on peut utiliser une analogie dans le domaine des systèmes d’exploitation. Dans le monde Linux, vous avez trois principaux fournisseurs de distribution : Debian, Ubuntu et Red Hat. Debian est le produit de choix si vous travailler sur le développement Linux. Si vous voulez utiliser Linux sur un portable en tant qu’utilisateur peu familier des technologies, Ubuntu est le produit de choix. Grâce à de nombreux ajouts en matière d’administration, d’outils pour faciliter l’installation, la configuration, l’utilisation, cloudera est le produit hadoop le plus simple d’utilisation. Au niveau du data center, Red Hat Linux est le système le mieux adapté. Pour des besoins comparables en matière de gestion des données, MapR est le mieux placé en termes de coûts, de fiabilité, de performances… Par ailleurs, il apporte la qualité de NetApp ou d’EMC au niveau la gestion des données à hadoop. Les trois produits sont de très bonne qualité mais répondent à des problématiques différentes.
IN : Les entreprises ont la technologie à disposition, elles ont les données même si celles-ci sont éparpillées et ne sont pas toujours accessibles, mais elles manquent de compétences et des ressources, les fameux data scientists. Comment régler ce problème ?
M.C. Srivas : Je crois qu’on exagère sur ce point car les statisticiens et les spécialistes de la BI, dotés d’un solide bon sens, peuvent sans trop de difficultés se reconvertir pour maîtriser ces nouvelles technologies. Les entreprises ne doivent pas avoir peur du terme data scientist.
IN : Pouvez-vous citer des utilisations d’hadoop significatives ?
M.C. Srivas : Le gouvernement indien a décidé de développer un système d’identification nationale basé sur la reconnaissance biométrique – iris, empreintes digitales. Il a déjà enregistré 700 millions de citoyens et en ont 1,5 million supplémentaires chaque jour. Une des raisons pour la création d’un tel système est la chasse à la fraude qui permet à un citoyen de toucher des allocations auxquels il n’a pas droit. Hadoop a été au cœur de ce système et a permis de réduire la fraude de 20/25 % à moins de 1 % et d’économiser près de 20 milliards de dollars.
Xavier Guerin, VP Southern Europe & Benelux, MapRIN : Où en sont les entreprises françaises face au big data ? Xavier Guerin : A la première édition de la conférence big data qui s’est tenue en avril 2013, les entreprises nous demandaient ce qu’était hadoop. A la seconde, ce qu’ils pouvaient faire avec et comment on pouvait les aider. MapR est présent en France depuis le début 2013 et a adopté le modèle indirect avec des partenaires comme Ysance, Octo, Bull (Fast Connect), Bluestone, EDIS Consulting. En 2014, nous avons développé des POC (Proofs of Concept) avec des premières applications en production chez cdiscount, l’une des grandes banques françaises et un des principaux acteurs de la distribution. 2015 sera l’année du décollage de MapR en France. Un des problèmes que nous rencontrons est la difficulté qu’ont nos interlocuteurs à « vendre » le projet en interne, aux spécialistes de bases de données, aux IT Pros… Alors que les spécialistes métier auraient plutôt tendance à pousser les projets notamment avec la perspective de réduction des coûts Xavier Guerin : A la première édition de la conférence big data qui s’est tenue en avril 2013, les entreprises nous demandaient ce qu’était hadoop. A la seconde, ce qu’ils pouvaient faire avec et comment on pouvait les aider. MapR est présent en France depuis le début 2013 et a adopté le modèle indirect avec des partenaires comme Ysance, Octo, Bull (Fast Connect), Bluestone, EDIS Consulting. En 2014, nous avons développé des POC (Proofs of Concept) avec des premières applications en production chez cdiscount, l’une des grandes banques françaises et un des principaux acteurs de la distribution. 2015 sera l’année du décollage de MapR en France. Un des problèmes que nous rencontrons est la difficulté qu’ont nos interlocuteurs à « vendre » le projet en interne, aux spécialistes de bases de données, aux IT Pros… Alors que les spécialistes métier auraient plutôt tendance à pousser les projets notamment avec la perspective de réduction des coûts |
[1] Pour en savoir plus sur la gamme de produits MapR
[2] MapR a levé 160 M$, Cloudera 900 M$ dont 740 M$ via Intel Capital et HortonWorks 200 M$.

 puis
puis