
Le big data est bien un axe stratégique d’IBM : Parallèlement à son projet Watson, Big Blue vient d’annoncer un investissement massif sur Spark que l’on peut placer dans la galaxie hadoop.
Plus d’une douzaine d’IBM Labs dans le monde, plus de 3 500 chercheurs et développeurs : C’est ce qu’IBM va investir dans Spark, qualifié de « potentiellement le plus important nouveau projet open source de la décennie dans le big data ». Parmi les investissements qui sont consentis à cette occasion, IBM fait état des éléments suivants :
– IBM va placer Spark au cœur de ses plates-formes analytics et de commerce électronique à l’offre Paas Bluemix ;
– IBM Watson Health Cloud utilisera Spark comme élément majeur pour accélérer la fourniture des données aux médecins et aux chercheurs qui travaillent dans les domaines de la santé ;
– IBM va offrir sa technologie d’apprentissage automatique SystemML à l’écosystème Spark ;
– IBM entend participer à la formation plus d’un million de datascientists et ingénieurs au framework en partenariat avec les MOOC AMPLab, DataCamp, MetiStream, Galvanize et Big Data University.
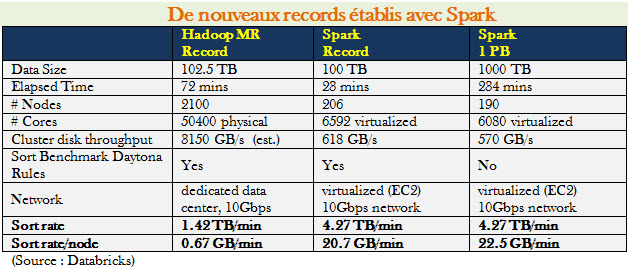
 Spark a été initialement développé en 2009 par le laboratoire AMPLab – dont IBM était des créateurs – de l’université UC Berkeley et placé sous le régime Open Source l’année suivante sous une licence BSD. En 2013, le projet a été confié à l’Apache Software Foundation sous licence Apache 2.0. En février 2014, Spark est devenu un projet de niveau Top-Level. En novembre dernier, la société Databricks a établi un nouveau record dans une opération de tri en utilisant Spark (voir tableau ci-dessous). Databricks a utilisé Spark sur 206 machines EC2 et réalisé le tri de 100 To de données en 23 minutes. A titre de comparaison, le précédent record était de 72 minutes et réalisé avec Hadoop MapReduce en utilisant 2100 machines. Spark a donc permis de réduire le temps de traitement d’un facteur 3 en utilisant 10 fois moins de machines.
Spark a été initialement développé en 2009 par le laboratoire AMPLab – dont IBM était des créateurs – de l’université UC Berkeley et placé sous le régime Open Source l’année suivante sous une licence BSD. En 2013, le projet a été confié à l’Apache Software Foundation sous licence Apache 2.0. En février 2014, Spark est devenu un projet de niveau Top-Level. En novembre dernier, la société Databricks a établi un nouveau record dans une opération de tri en utilisant Spark (voir tableau ci-dessous). Databricks a utilisé Spark sur 206 machines EC2 et réalisé le tri de 100 To de données en 23 minutes. A titre de comparaison, le précédent record était de 72 minutes et réalisé avec Hadoop MapReduce en utilisant 2100 machines. Spark a donc permis de réduire le temps de traitement d’un facteur 3 en utilisant 10 fois moins de machines.
 La NASA et le SETI Institute (un organisme qui s’intéresse à la vie dans l’Univers) utilisent Spark sur Bluemix (en mode as a service) pour analyser d’énormes quantités de signaux radio provenant de l’espace afin de déterminer si la vie existe ailleurs que sur la terre. eBay, Opentable et Yahoo utilisent également Spark dans des projets de big data. Dans une enquête réalisée en décembre 2014 par l’éditeur TypeSafe révélait que sur les 3000 développeurs Java interrogés, 17 % utilisant la technologie Spark.
La NASA et le SETI Institute (un organisme qui s’intéresse à la vie dans l’Univers) utilisent Spark sur Bluemix (en mode as a service) pour analyser d’énormes quantités de signaux radio provenant de l’espace afin de déterminer si la vie existe ailleurs que sur la terre. eBay, Opentable et Yahoo utilisent également Spark dans des projets de big data. Dans une enquête réalisée en décembre 2014 par l’éditeur TypeSafe révélait que sur les 3000 développeurs Java interrogés, 17 % utilisant la technologie Spark.
« Nous croyons fermement à la puissance de l’open source pour créer de la valeur. Nous nous sommes investis dans Spark pour en faire une plateforme technologique fondamentale afin d’accélérer l’innovation et de faire de l’analytique un mouvement fondamental touchant toutes les activités », commentait Beth Smith, responsable de la plate-forme analytique d’IBM dans un communiqué. Cette annonce s’inscrit la stratégie d’IBM élaboré depuis plusieurs années et qui se traduira par l’injection de 4 milliards de dollars sur l’année 2015 pour développer des activités appartenant à ce que Ginny Rometty, Pdg d’IBM avait appelé un « impératif stratégique » et qui est représenté par l’acronyme SMACS (Social, Mobility, Analitycs, Cloud and Security). Ces activités devraient générer 40 % du chiffre d’affaires en 2018 contre 27 % en 2014 et 13 % en 2010. Il est à noter que le logiciel joue un rôle majeur dans ces activités d’avenir, supérieur au service. C’est la composante analytics qui est de loin la plus importante. Dans ce renouveau, IBM n’a pas ménagé sa peine ou plutôt sa tire-lire : 8 milliards de dollars pour le rachat de 18 entreprises dans le cloud, 26 milliards dans le big data pour 30 acquisitions.
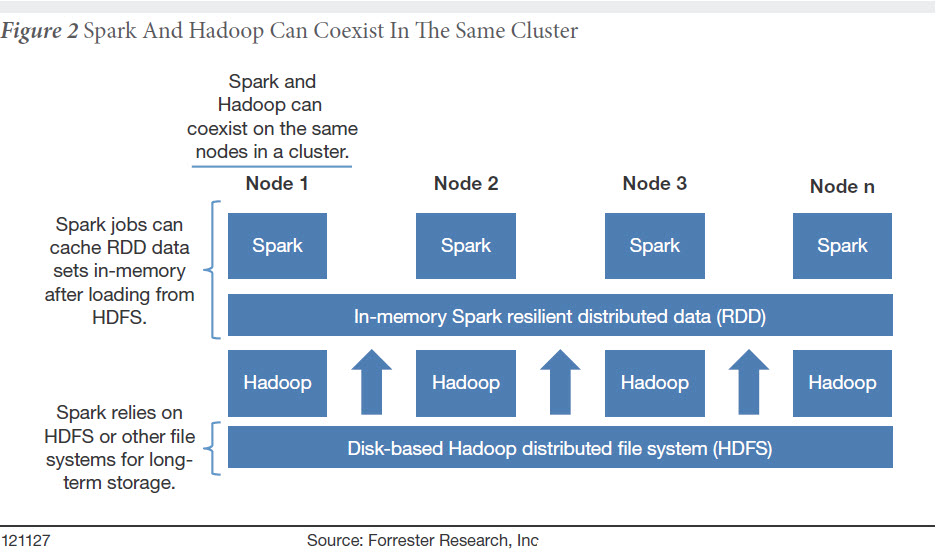
Spark est un des éléments qui permet de faire évoluer hadoop et le big data d’une logique batch vers le temps réel. « Spark a été conçu pour traiter les données le plus rapidement possible, explique Mike Gualtieri, consultant du cabinet Forrester dans une note intitulée Apache Spark Is Powerful and Promising. Spark est un moteur de calcul in-memory sur un cluster de mémoires. Spark peut s’interfacer à plusieurs systèmes de fichiers parmi lesquels on peut citer HDFS, Cassandra, Swift, Amason S3…). Spark fonctionne également avec de nombreux outils incluant Spark SQL, MLlib for machine learning, GraphX, et Spark Streaming. Spark est présenté comme l’un des projets les plus dynamiques de la planète hadoop
« Spark représente une façon totalement nouvelle de traiter les données, explique Joel Horowitz, directeur du marketing pour IBM analytics. C’est un moteur in-memory très puissant doté d’une interface simple et facilement accessible aux data scientists et aux développeurs ».

 puis
puis