
Trois ans après la première conférence OpenPower, les technologies autour des processeurs Power ont fait de grands progrès et marquent des points par rapport à l’architecture x86.
C’est l’idée avancée par le cabinet Robert Francis Group dans une note intitulée The Unherald Power of OpenPOWER. Par rapport à cette concurrence qui prend forme, on doit noter aussi celle des architectures ARM qui sont aussi utilisés dans les serveurs. HPE vient en particulier de dévoiler un supercalculateur utilisant ces processeurs ARM crédité de 2 PFlops qui figurerait dans les Top100 de supercalculateurs.
Des serveurs OpenPOWER en grand nombre sont désormais opérationnels chez Google, Oak Ridge National Labs, et dans d’autres data centers, preuve que ces technologies surpassent de manière significative les solutions x86 sur la courbe de performance / TCO (Total Cost of Ownership). Pour le cabinet RFG, alors qu’Intel se préparer à livrer sa prochaine génération de puces x86, les DSI qui sont très attentifs à cet indicateur prix / performance devront considérer d’autres options telles que les serveurs OpenPOWER.
Les implications de la fin de la loi de Moore
Depuis près de 50 ans, la loi de Moore a guidé les conceptions de chaque génération successive de processeurs x86. L’engagement implicite d’Intel a conduit les DSI à s’attendre à un doublement des performances tous les deux ans et à une budgétisation des coûts des serveurs en fonction de la courbe de prix / performances prévue et qui devait durer indéfiniment.
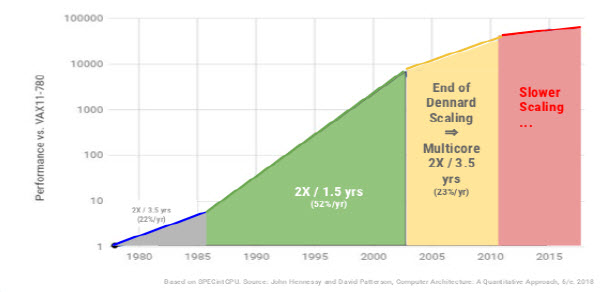
Mais la loi de Moore a commencé à se désintégrer au début du siècle lorsque les puces ne pouvaient pas fournir les gains de performance attendus. Les fournisseurs ont résolu ce problème en améliorant tous les autres composants, les accélérateurs, les micrologiciels, les réseaux, les systèmes d’exploitation, les logiciels et le stockage. (Voir le graphique ci-dessous de Google Cloud.)
Les lois de Dennard
Dans les années 70, Robert Dennard, chercheur chez IBM et inventeur de la DRAM, fut l’un des premiers à montrer les énormes bénéfices que l’on pouvait récolter en réduisant la taille d’un transistor. Plus la finesse de gravure augmente, plus il est possible de fabriquer des transistors d’un seul coup réduisant ainsi leur prix. Il est aussi possible de les faire fonctionner plus rapidement et d’en mettre plus sur une surface donnée, augmentant les performances du circuit intégré. La miniaturisation des composants permet aussi de réduire la tension nécessaire pour leur fonctionnement.
Lors de la présentation de ses résultats du 1er trimestre 2018, Intel a révélé que son processus de 10 nm de prochaine génération connaît de sérieux problèmes de production. Elles devraient être livrés en 2015, puis en 2017 et au second semestre 2018. Maintenant, il apparait de plus en plus probable que la production à grand volume n’interviendra pas avant la seconde moitié de 2019 et que les objectifs de densité soient révisés à la baisse. Entre-temps, Intel a amélioré sa performance de puce de 14 nm de 70% depuis son lancement en 2014. Tout cela est conforme aux projections faites par Google (23% / an) comme indiqué dans le tableau ci-dessus. C’est également une preuve supplémentaire que la loi de Moore est morte et qu’une autre architecture pourrait être nécessaire si les DSI espèrent continuer à acquérir des serveurs selon la même courbe prix / performance.
OpenPOWER à la rescousse
IBM et les membres de la Fondation OpenPOWER ont fait des progrès significatifs avec les puces, le matériel et les logiciels. Lors de la conférence OpenPOWER qui s’est tenue à Las Vegas en mars 2018, des témoignages d’Alibaba, de Google, de Limelight, d’Oak Ridge National Labs, de Tencent et d’Uber confirment cette observation. Les déclarations les plus impressionnantes sont venues de Google qui a confirmé avoir déployé des serveurs OpenPOWER / Open Compute Zaius POWER9 développés en collaboration avec IBM et Rackspace. Les serveurs Zaius sont en cours de production et Google Cloud augmente le nombre de machines installées. Maire Mahoney de Google a déclaré que ces serveurs sont « Google Strong », c’est-à-dire qu’ils répondent aux normes de fiabilité et de robustesse de Google. Elle a également déclaré que ces serveurs leur donnaient la meilleure performance / TCO et obligeait à repenser sa stratégie serveurs.
Parmi les autres raisons avancées par Google, POWER9 offre plus de cœurs et de threads pour l’utilisation de son moteur de recherche, une plus grande bande passante de mémoire pour l’apprentissage automatique (machine learning), et une mémoire flash NAND plus rapide sur un bus d’accélération OpenCAPI.
Autre partisan des technologies POWER, Tencent a déclaré que depuis l’installation de ces serveurs construits sur ce processeur, les performances ont augmenté de 30% alors que les coûts pour les ressources de rack et de serveur ont diminué de 30%. La branche cloud d’Alibaba, Ali Cloud, et PayPal ont également annoncé leur utilisation des solutions OpenPOWER. PayPal utilise les serveurs pour traiter de grands ensembles de données et accélérer les applications de deep learning pour prévenir la fraude.
Le laboratoire Oak Ridge a utilisé les composants OpenPOWER pour construire le nouveau supercalculateur Summit (Top500 : Summit, l’arbre qui cache la forêt), qui a remplacé le superordinateur Titan. Le nombre de nœuds de calcul passe de 18 688 à 4 608 mais la performance passe de 1,4 teraflops à 42 teraflops. En outre, Summit va relier plus de 27 000 GPU Nvidia optimisés pour l’apprentissage en profondeur, grâce à la technologie haut débit NVLink intégrée à tous les processeurs. Ces systèmes font monter la barre et représentent un défi à long terme pour Intel. Mais là, c’est un peu l’arbre qui cache la forêt car le nombre de supercalculateurs contruits sur le processeur POWER est tombé à 13 dans la liste qui vient d’être publié alors qu’il était à une cinquantaine il y a 5 ans.
Quelques articles sur OpenPower
Annonces d’IBM au OpenPOWER Summit
OpenPower peut-elle inquiéter x86 d’Intel ?
Premières annonces pour la Fondation OpenPower

 puis
puis