
Face à la concurrence d’OpenAI, mais plus encore de modèles ouverts, comme ceux de DeepSeek et Mistral AI, Meta lance trois nouveaux modèles « Llama 4 », ouverts, multimodaux, et basés sur une architecture MoE. Mais attention, les usages de Llama 4 dans l’Union européenne souffrent de fortes restrictions.
Si les LLM frontières semblent plus ou moins stagner, les modèles moyens et plus petits continuent de progresser de façon fulgurante grâce à des jeux de données d’entraînement de plus en plus qualitatifs, une plus grande maîtrise des techniques de distillation et des améliorations stratégiques dans leur conception. Preuve en est une nouvelle fois avec l’arrivée de la nouvelle génération des modèles « LLama » de Meta. Pour rappel, cette famille de modèles – qui a été téléchargée plus d’un milliard de fois – est la plus populaire et la plus utilisée des familles de modèles « ouverts » (comprenez « open weight »).
Reste que LLama est de plus en plus concurrencé par d’autres modèles ouverts tels que DeepSeek R1, Mistral Small 3, Google Gemma 3, IBM Granite 3 ou encore Microsoft Phi-4. Le tremblement de terre engendré aux USA par la sortie de DeepSeek R1 a semble-t-il redonner des ailes à Meta qui a voulu frapper plus fort avec sa nouvelle génération LLama 4.
Une nouvelle ère pour l’écosystème Llama
Cette famille comprend trois modèles distincts : Scout, Maverick et Behemoth. Innovation majeure pour l’éditeur et la gamme Llama, ces modèles sont les premiers à être nativement multimodaux (capables de traiter texte, images et vidéos) et à utiliser une architecture de type « mixture of experts » (MoE, une technique déjà largement employée par Mistral AI et DeepSeek notamment).
« Notre objectif est de construire l’IA la plus performante au monde, de la rendre open source et universellement accessible » rappelle ainsi Mark Zuckerberg, le CEO du groupe.
Ces modèles dérivent des éditions précédentes mais s’en démarquent sur plusieurs points. Ils ont tous été entraînés à l’aide de nouvelles méthodes, comme MetaP pour optimiser les hyperparamètres et sur un large corpus de données de 30 milliards de tokens (le double de Llama 3) combinant textes, images et vidéos. Meta exploite une technique de « Fusion multimodale précoce » permettant le traitement unifié des textes, images et vidéos dès le début du pipeline. En outre l’approche MoE permet à la fois d’améliorer les performances et de réduire les coûts de calcul (et donc d’inférence) puisque seule une fraction des paramètres est activée pour chaque token.
En outre, Meta affirme avoir considérablement amélioré l’équilibre de Llama 4 face aux sujets controversés. Le modèle refuserait désormais moins de répondre aux questions politiques et sociales sensibles (moins de 2% contre 7% pour Llama 3.3).
Trois modèles complémentaires
La famille « Llama 4 » comportera très probablement à terme de nombreux modèles complémentaires. Meta en a, pour le moment, officialisé trois : Scout, Maverick, Behemot.
Llama 4 Scout
Le plus petit modèle actuel de la nouvelle famille, Llama 4 Scout est un modèle multimodal qui concurrence Gemma 3 et Gemini 2.0 Flash-lite. C’est un modèle basé sur 16 experts limitant à 17 milliards les paramètres actifs. Sa vraie particularité est d’autoriser – et c’est unique à ce jour, surtout sur un tel petit modèle – des fenêtres contextuelles de 10 millions de tokens ce qui lui permet de traiter des séquences textuelles exceptionnellement étendues (livres, rapports volumineux, vastes codes informatiques). Optimisé pour tenir sur un seul GPU NVIDIA H100 grâce à une quantification en Int4, ce modèle assure un excellent équilibre entre performance, coût et déploiement, tout en proposant des capacités avancées en compréhension d’images, en codage et en traitement de texte.
– 17 milliards de paramètres actifs pour 109 milliards au total (16 experts)
– Optimal sur des contextes de 4K ou 16K. Peut supporter des contextes exceptionnels de 10 millions de tokens si utilisé en INT4 en sachant qu’au-delà de 128.000 tokens, le KV Cache devient prédominant ce qui impose une forte consommation mémoire et de mettre en œuvre des techniques avancées de streaming et sharding. Pour 10 millions de Tokens, il faut environ 18,8 To de VRAM.
– Fonctionne sur un seul GPU Nvidia H100
[arve url= »https://video-cdg4-1.xx.fbcdn.net/o1/v/t2/f2/m69/AQPlkOIpAB5OKfR7fCH-8kZ3McRJeI3qjXL6TfFl7EzlCGRjukjcEmBSSusLakkZcPamoBjOZCLX6hK6rWNdwzIc.mp4?strext=1&_nc_cat=104&_nc_sid=5e9851&_nc_ht=video-cdg4-1.xx.fbcdn.net&_nc_ohc=qX75EgGzT7QQ7kNvwGchbdY&efg=eyJ2ZW5jb2RlX3RhZyI6Inhwdl9wcm9ncmVzc2l2ZS5GQUNFQk9PSy4uQzMuMTkyMC5kYXNoX2gyNjQtYmFzaWMtZ2VuMl8xMDgwcCIsInhwdl9hc3NldF9pZCI6MTE4NjQ5MDk3MzAwNjkxNSwidmlfdXNlY2FzZV9pZCI6MTA2MjcsImR1cmF0aW9uX3MiOjE4LCJ1cmxnZW5fc291cmNlIjoid3d3In0%3D&ccb=17-1&vs=e5744c482b247e6c&_nc_vs=HBksFQIYOnBhc3N0aHJvdWdoX2V2ZXJzdG9yZS9HR1p2QWgxelAtdzJ4QjhMQUltelo5bFcyVk1EYnY0R0FBQUYVAALIAQAVAhg6cGFzc3Rocm91Z2hfZXZlcnN0b3JlL0dCc0hIeDNTV1J6UlFQQUZBRDlXUTJZOXVCUnNidjRHQUFBRhUCAsgBACgAGAAbAogHdXNlX29pbAExEnByb2dyZXNzaXZlX3JlY2lwZQExFQAAJoaxzc_uxpsEFQIoAkMzLBdAMgAAAAAAABgaZGFzaF9oMjY0LWJhc2ljLWdlbjJfMTA4MHARAHUCAA&_nc_zt=28&oh=00_AfHCTJdmx2VEBnk3tHqkpzmBVhgGrJhy8U9x70-zpGltsw&oe=67F99092″ /]
Llama 4 Maverick
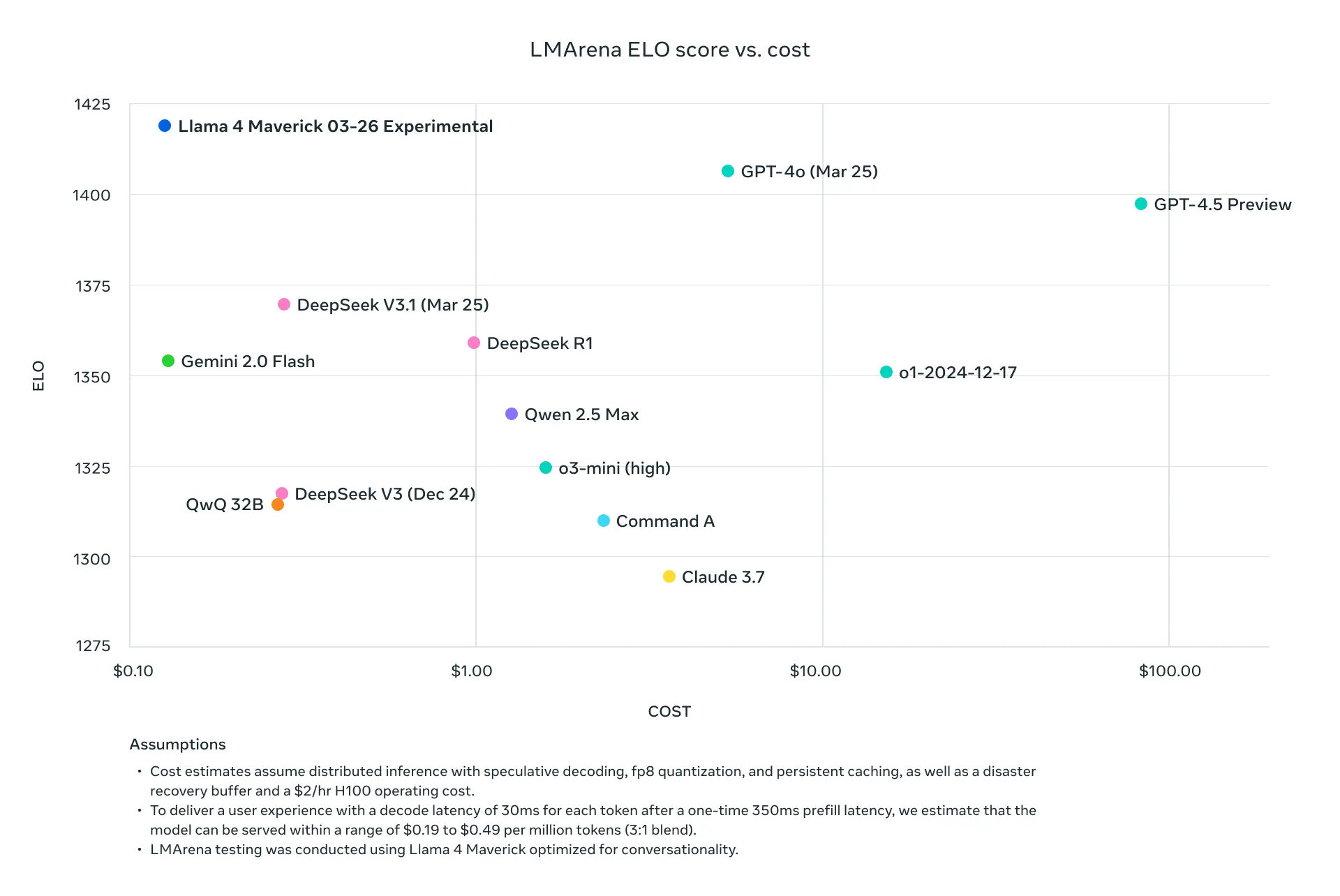
Maverick se veut plus précis, plus généraliste et plus efficace tout en restant hautement performant. Doté de 17 milliards de paramètres actifs et 128 experts, il se distingue par un rapport performance/coût exceptionnel. Conçu pour exceller en compréhension d’images, raisonnement et codage, il surpasse des concurrents comme GPT-4o et Gemini 2.0 Flash sur de nombreux benchmarks. Idéal pour les applications de chat, d’assistance virtuelle et de création de contenus, Llama 4 Maverick offre une solution polyvalente pour répondre aux besoins exigeants des développeurs et des environnements professionnels. Optimisé pour une fenêtre contextuelle de 128.000 tokens, le modèle peut être paramétré pour atteindre une fenêtre contextuelle de 1 million de tokens.
– 17 milliards de paramètres actifs pour 400 milliards au total (128 experts)
– Fenêtre contextuelle maximale : 1 million de tokens
– Optimisé pour les assistants conversationnels
– Supporte 12 langues et excelle dans la compréhension d’images
Llama 4 Behemoth
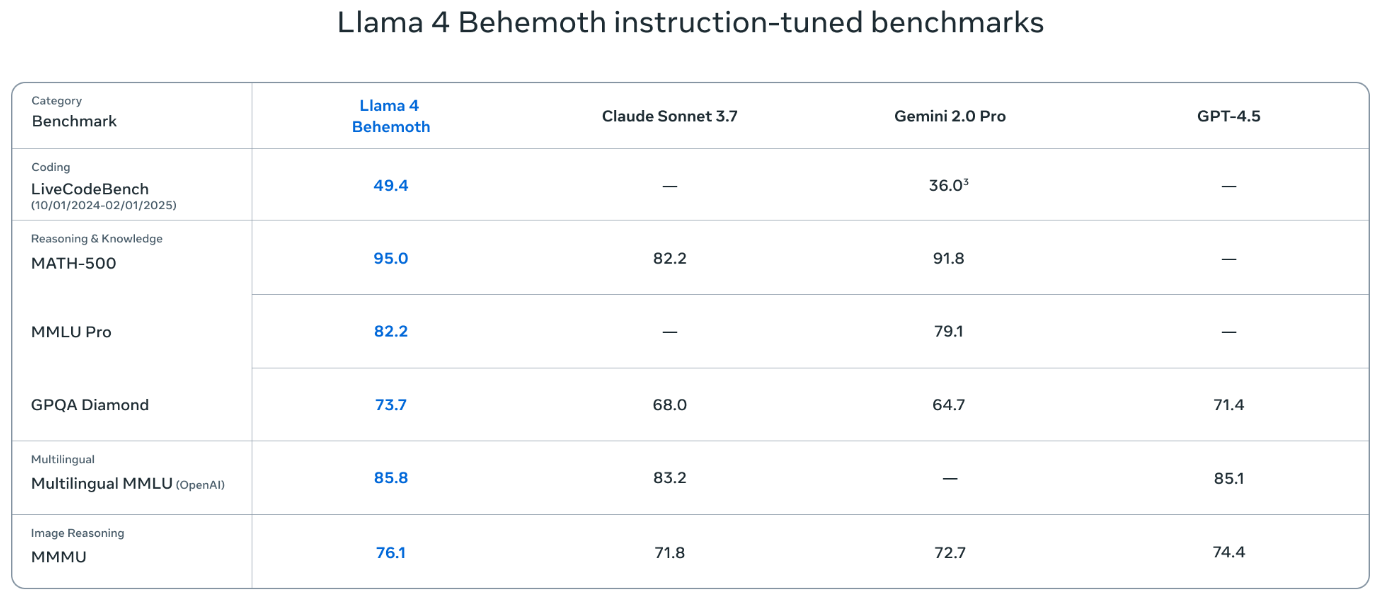
Llama 4 Behemoth est le modèle phare de la série Llama 4. Doté de 288 milliards de paramètres actifs (et près de deux mille milliards au total grâce à son architecture MoE avec 16 experts), il se positionne parmi les LLM les plus puissants et intelligents au monde. Annoncé comme surpassant des concurrents comme GPT-4.5, Claude Sonnet 3.7 et Gemini 2.0 Pro sur plusieurs benchmarks STEM, il sert de référence pour la distillation vers des modèles plus compacts tels que Llama 4 Maverick, en utilisant une fonction de perte innovante pour optimiser l’apprentissage. Behemot a surtout une vocation expérimentale. Même l’inférence sur de petites fenêtres contextuelles nécessite une infrastructure fortement parallélisée, optimisée et spécialisée pour l’IA.
– 288 milliards de paramètres actifs pour près de 2.000 milliards au total (16 experts)
– Encore en phase d’entraînement, sert de « modèle enseignant »
– Surpasserait GPT-4.5, Claude 3.7 Sonnet et Gemini 2.0 Pro sur certaines évaluations STEM
Des modèles « ouverts » mais pas tant que ça…
Scout et Maverick sont téléchargeables sur llama.com et Hugging Face. Ils sont déjà intégrés à Meta AI dans WhatsApp, Messenger et Instagram Direct dans 40 pays. Ces modèles sont également disponibles via Azure AI Foundry et Azure Databricks, mais aussi sur AWS Sagemaker.
Ces nouveaux modèles sont considérés comme des modèles ‘open weight’ et sont toujours publiés sous licence open source (Llama 4 Community Licence) mais celle-ci comporte toutefois des restrictions importantes :
– La licence permet une utilisation, reproduction, distribution et modification des modèles, ainsi que la création d’œuvres dérivées, MAIS toute distribution (ou intégration dans un produit ou service) doit inclure une copie de cette licence et comporter l’affichage visible de « Built with Llama ».
– Si vous utilisez les Llama Materials pour créer, entraîner ou améliorer un modèle d’IA destiné à être diffusé, le nom de ce modèle devra débuter par « Llama »
– Les entreprises dépassant 700 millions d’utilisateurs mensuels doivent obtenir une licence spéciale auprès de Meta.
Ça, c’est pour la théorie. En pratique, l’utilisation des modèles Llama 4 « multimodaux » (cas de ces 3 modèles) pour développer des produits ou des services est interdite à tout individu domicilié dans l’Union européenne et à toute entreprise ayant son siège social dans l’UE ! En gros, seule la recherche autour des modèles Llama 4 est autorisée dans l’UE. Une sacrée limitation ! En revanche, si une entreprise basée en dehors de l’UE propose un service utilisant ces modèles, les utilisateurs finaux dans l’UE peuvent tout de même utiliser le service.
À lire également :

 puis
puis