
La maison mère de Facebook, WhatsApp et Instagram veut muscler ses capacités d’apprentissage machine et de recherche sur le potentiel du Metaverse. Elle se construit un HPC d’un genre particulier, spécialement calibré pour l’apprentissage des IA.
Nouvellement rebaptisée Meta, la maison mère de Facebook veut s’offrir son propre supercalculateur massivement animé par des GPU afin d’accélérer les processus d’apprentissage des IA et concrétiser des modèles formés de milliers de milliards de paramètres. Objectif avoué, produire de nouvelles IA capables d’animer les métavers, nouvelle lubie de Mark Zuckerberg.
Un HPC à base de GPU truffé de Tensor Cores…
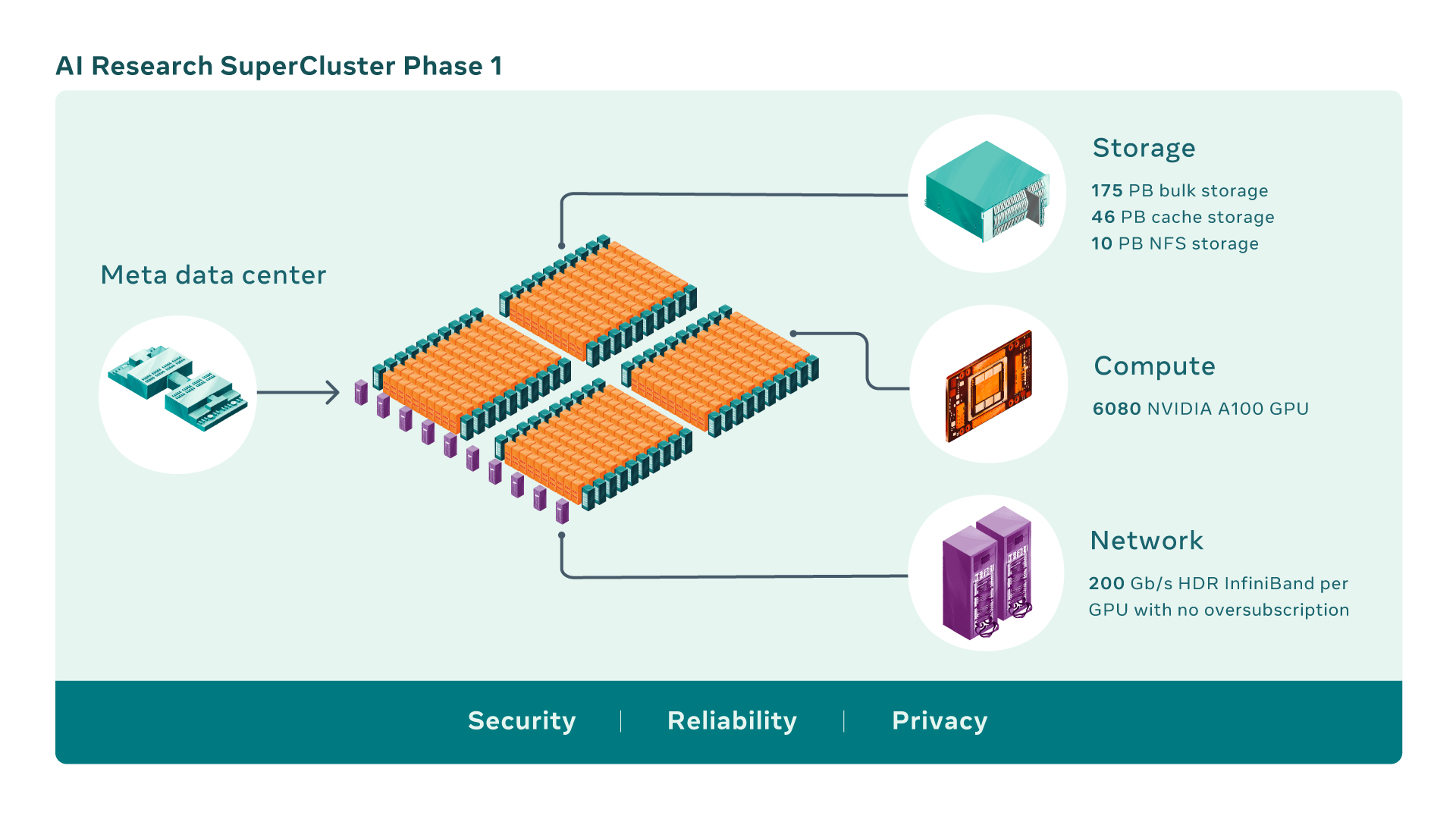
Dénommé RSC pour AI Research Super Cluster, ce nouveau HPC privé est – comme tout HPC – construit en phases successives.
La première phase de construction de ce HPC vient de s’achever et d’être mise en route. Elle comporte 760 nœuds de calcul NVidia DGX A100 interconnectés par un réseau InfiniBand de 1600 Gb/s (gigabit par seconde). Chaque nœud embarque 2 CPU AMD Epyc et 8 GPU A100 pour un total de 6.080 GPU A100. Le stockage s’appuie sur une baie FlashArray de Pure Storage d’une capacité de 175 Po associé à un cache de 46 Po. Une baie Pure Storage FlashBlade de 10 Po vient s’ajouter pour accueillir un stockage NFS partagé. L’ensemble a été construit par Meta en collaboration avec Penguin Computing qui a élaboré cette architecture spécialement pour l’IA et construit ce méga-cache de stockage.
De très hautes performances
À l’heure actuelle, donc en Phase 1, la performance du RSC est évaluée par NVIdia à 1.895 Petaflops en performance de calcul TF32 (TensorFloat-32, un format spécial de calcul IA s’appuyant sur 19 bits : 1 de signe, 8 de valeurs entières, 10 de précision après la virgule). Une donnée qui rend difficiles les comparaisons directes puisque les HPC classiques sont évalués par TOP500.ORG à l’aide d’un autre benchmark (Linpack) en virgule flottante sur 64 bits. Selon HPCwire, la machine RSC de Meta se situerait autour des 220 PetaFLOPS en mesure Linpack (ce qui en ferait le second HPC derrière Fugaku).
Déjà avec cette Phase 1, les premiers benchmarks ont – comparés à l’infrastructure de production et de recherche existante de Meta à base de 22.000 GPU NVidia v100 – montré que le RSC exécute les flux de vision par ordinateur jusqu’à 20 fois plus rapidement, qu’il exécute la bibliothèque de communication collective de NVIDIA (NCCL) plus de neuf fois plus rapidement et qu’il entraîne les modèles NLP à grande échelle trois fois plus rapidement. « Cela signifie qu’un modèle comportant des dizaines de milliards de paramètres peut terminer son apprentissage en trois semaines, contre neuf auparavant » illustre les chercheurs de Meta.

La version complète du système devrait être finalisée vers le milieu de l’année 2022. Une fois terminé, le IA-HPC embarquera plus de 16 000 GPU A100 (aux alentours de 2000 nœuds DGX A100) avec un stockage étendu à 1 Exaoctet et une architecture de cache capable d’absorber 16 To/sec de données d’entrainement d’IA. Autrement dit, la machine finale devrait être 2,5 fois plus performante que cette « Phase 1 ». Ce qui amènera sa puissance à 5 exaflops (en mesures TF32 et non Linpack).
Mais pour quoi faire ?
« Nous voulions que cette infrastructure soit capable d’entraîner des modèles comportant plus d’un millier de milliards de paramètres sur des ensembles de données aussi volumineux qu’un exaoctet, ce qui, pour donner une idée de l’échelle, équivaut à 36 000 ans de vidéo de haute qualité », expliquent les chercheurs en IA de Meta.
L’ancienne infrastructure de calculs IA de Meta, à base de GPU V100, exécute déjà environ 35 000 jobs d’entrainements d’IA chaque jour ! Autant dire que les besoins de Meta en la matière sont gigantesques.
Les chercheurs de Meta justifient leurs besoins en expliquant que « pour tirer pleinement parti des avantages de l’apprentissage auto-supervisé et des modèles basés sur les transformateurs – dans divers domaines, qu’il s’agisse de la vision, de la parole, du langage, ou pour des cas d’utilisation critiques comme l’identification de contenus nuisibles – il faudra former des modèles IA de plus en plus grands, complexes et adaptables. La vision par ordinateur doit, par exemple, traiter des flux vidéos toujours plus longs avec des taux d’échantillonnage de données toujours plus élevés. La reconnaissance vocale doit fonctionner correctement même dans des scénarios difficiles avec beaucoup de bruit de fond, comme des fêtes ou des concerts. Le traitement automatique des langues doit comprendre davantage de langues, de dialectes et d’accents. Et les progrès dans d’autres domaines, notamment la robotique , l’intelligence artificielle incarnée et l’IA multimodale aideront les gens à accomplir des tâches utiles dans le monde réel ».
.

 puis
puis