Pentaho, désormais dans le giron du groupe Hitachi, annonce cinq innovations, dont SQL on Spark, pour aider les entreprises à surmonter la complexité des Big Data, la pénurie de compétences et les défis que pose l’intégration des données dans des environnements complexes. Ces améliorations doivent permettre aux équipes informatiques d’extraire plus rapidement de la valeur des projets Big Data à partir des ressources existantes, grâce à l’élimination du codage manuel, à une sécurité renforcée et à une prise en charge plus étendue de l’écosystème technologique des Big Data.
1. Une intégration Apache Spark renforcée
Pentaho étend son intégration à Spark au sein de sa plateforme afin :
– D’accéder plus facilement à Spark : les analystes peuvent désormais interroger et traiter des données Spark via Pentaho Data Integration (PDI) en utilisant SQL on Spark
– De coordonner, planifier, réutiliser et gérer des applications Spark dans les pipelines de données avec davantage de facilité et de flexibilité : l’orchestration de PDI étendue à Spark Streaming, Spark SQL et Spark Machine Learning (Spark MLlib et Spark ML) permet de prendre en charge le nombre croissant de développeurs qui utilisent plusieurs bibliothèques Spark
– D’intégrer les applications Spark dans des plus larges processus pilotés par les données, afin d’en tirer pleinement profit : les développeurs bénéficient de l’orchestration par PDI des applications Spark écrites en langage Python
2. Fonctionnalités étendues d’injection de métadonnées
Grâce à la fonctionnalité unique d’injection de métadonnées de Pentaho, permettant d’intégrer plus rapidement différents types de données, les ingénieurs peuvent générer des transformations via PDI de façon dynamique au moment de l’exécution sans devoir coder manuellement chaque source de données. ce qui permet de diviser les coûts par 10. Pentaho ajoute plus de 30 étapes de transformation via PDI compatibles, y compris les opérations liées à Hadoop, Hbase, JSON, XML, Vertica, Greenplum et autres sources Big Data.
INJECTION DE MÉTADONNÉES
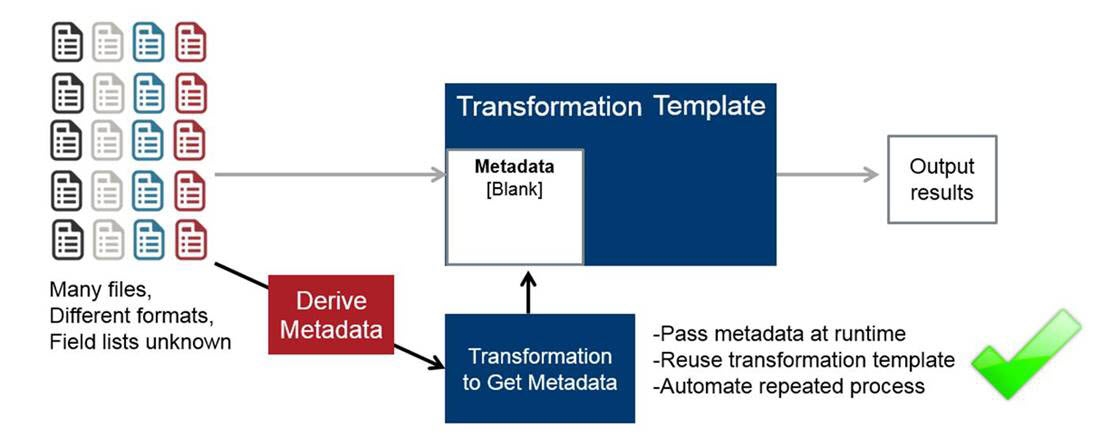
3. Intégration étendue de la sécurité des données Hadoop
La sécurisation des environnements Big Data peut s’avérer particulièrement complexe dans la mesure où les technologies qui définissent l’authentification et l’accès ne cessent d’évoluer. Pentaho étend son intégration de la sécurité des données Hadoop pour favoriser la gouvernance des Big Data et ainsi protéger les clusters contre les intrusions. Il s’agit notamment de l’intégration renforcée de Kerberos, pour la sécurisation de l’authentification multi-utilisateur, et de l’intégration de Apache Sentry, pour renforcer les règles qui régissent l’accès à certaines données Hadoop spécifiques.
4. Prise en charge d’Apache Kafka
Apache Kafka, système de messagerie de type publication/abonnement de plus en plus populaire, permet de gérer les grands volumes de données caractéristiques des solutions Big Data et IoT actuelles. Pentaho fournit un support client Entreprise pour envoyer et recevoir des données de Kafka, afin de faciliter le traitement continu des données dans PDI.
5. Prise en charge accrue des formats de fichiers Hadoop
Pentaho prend désormais en charge dans PDI la génération de fichiers Avro et Parquet, deux formats largement utilisés pour le stockage des données dans Hadoop lors de projets d’intégration des Big Data.

 puis
puis