
Transformer le business model du data center en facilitant la mobilité des données sur le média le plus approprié, tel est l’objectif que s’est fixé Primary Data qui démarre la commercialisation en volume limité de sa solution DataSphere.
« La bonne donnée au bon endroit au bon moment ». La formule donne un air de déjà-vu. Elle décrit assez bien ce que souhaite faire Primary Data. Certes le stockage a connu une formidable évolution avec une baisse contenue du ratio prix/performance. Mais l’apparition continue de nouveaux systèmes de stockage, de nouveaux protocoles, de nouveaux standards a créé de véritables silos de données qui deviennent « prisonnières » des médias qui les hébergent. Cette situation de silos a aussi l’effet pervers d’entraîner une surconsommation d’espace de stockage que Primary Data estime entre 4 et 8 milliards de données chaque trimestre. Alors qu’il serait préférable de pouvoir migrer facilement les données au fur et à mesure de leur utilisation et de leur cycle de vie.
 « C’est pour pallier cette difficulté qu’est apparu le concept de virtualisation du stockage, explique David Flynn, CTO de Primary Data. Mais cette solution n’a fait que repousser le problème en élargissant les conteneurs de données sans pour autant les supprimer. L’arrivée des mémoires flash a joué alors comme un catalyseur et un facilitateur pour évoluer vers des solutions de virtualisation des données ». L’étape la plus importante à franchir est de séparer les données des métadonnées. C’est ce que propose Primary Data avec sa solution DataSphere qui gère les métadonnées et permet de stocker les données à l’endroit le plus appropriée.
« C’est pour pallier cette difficulté qu’est apparu le concept de virtualisation du stockage, explique David Flynn, CTO de Primary Data. Mais cette solution n’a fait que repousser le problème en élargissant les conteneurs de données sans pour autant les supprimer. L’arrivée des mémoires flash a joué alors comme un catalyseur et un facilitateur pour évoluer vers des solutions de virtualisation des données ». L’étape la plus importante à franchir est de séparer les données des métadonnées. C’est ce que propose Primary Data avec sa solution DataSphere qui gère les métadonnées et permet de stocker les données à l’endroit le plus appropriée.
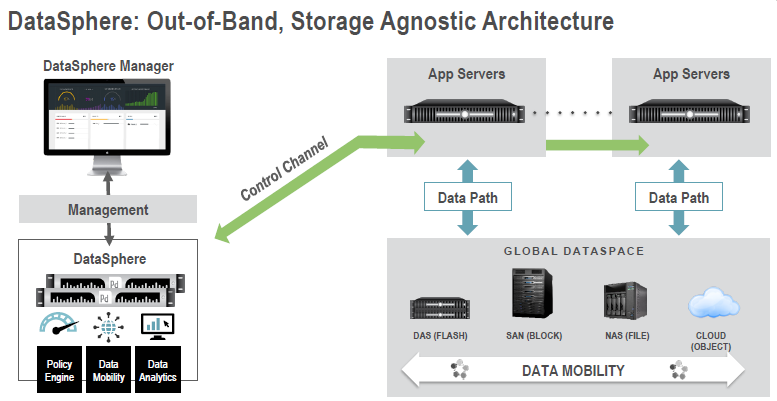
DataSphere est une solution de virtualisation des données indépendantes des plateformes matérielles qui apporte la continuité de l’identité des données et la continuité de l’accès. Les données deviennent alors indépendantes des supports qui les hébergent. DataSphere crée un espace virtuel de données qui permet d’ajouter des capacités de stockage sans se préoccuper de l’aspect matériel et indépendamment de l’architecture sous-jacente (Direct Attached Storage, NAS, SAN, cloud, Flash…). Il supporte un moteur de règles qui positionnent automatiquement les données qu’elles soient stockent sous forme de fichiers, de blocs ou d’objets.
L’allocation des données s’effectue de manière optimale en fonction de différents critères. Cette allocation est réalisé par deux modules supplémentaires : Objectives et smart Objectives. Objectives peuvent considérés comme une extension des métadonnées et permettent de donner des attributs aux données en fonction des performances souhaitées, du niveau de sécurité, de la date d’expiration… Une fois explicités, les données peuvent alors être stockées dans le média le plus appropriés. Avec DataSphere, l’administrateur peut décider un SLA de haut niveau (Par exemple Platinum, Gold, Silver, Bronze) mais aussi aller beaucoup en détail au niveau de données.
Les Smart Objectives poursuivent le même but mais à la différence qu’ils sont basés sur l’analytics de l’utilisation des données en découvrant comment les données sont utilisées pour ensuite décider de leur allocation. Il est aussi possible de définir des règles simples avec les Smart Objectives comme par exemple migrer des données à une date donnée en fonction d’un calendrier.
David Flynn propose une métaphore simple pour faire comprendre le mécanisme : les données correspondent aux locataires à la recherche d’un appartement et les systèmes de stockage aux propriétaires. Primary Data crée une relation entre ces deux parties prenantes pour optimiser l’ensemble du stockage des données selon trois critères principaux : Protection (Durability, availability, priority, recoverability, and security), Performance (IOPS, bande passante, temps de latence) et Prix.
DataSphere est donc le cœur du système qui orchestre ces trois niveaux : virtualisation des données, Objectives et Smart Objectives. La version 1 a été annoncé au dernier VMWorld en août dernier où le fournisseur a présenté une démonstration de sa solution en mettant dans un même espace de données stockées dans des systèmes EMC Isilon, NetApp ONTAP, Intel NVMe et S3 sur le cloud d’Amazon. Cette version est actuellement disponible en version limitée et en test chez quelques dizaines de clients.
Primary Data commercialisera DataSphere sous la forme d’un logiciel ou d’une appliance avec une tarification basée sur le nombre de fichiers gérés. Chaque appliance est proposée en un double système pour offrir une haute disponibilité.
D’autres solutions seront également supportées parmi lesquelles on peut citer Glacier d’Amazon, Azure de Microsoft, Swift d’OpenStack. Primary Data travaille également au développement d’une solution qui permettrait de fédérer des données stockées dans différents data centers.
Premiers cas d’utilisation de sa solution Datasphere

Primary Data en faits et chiffres
Créée à Los Altos (Californie) l’année dernière, Primary Data est assez largement financée puisqu’elle a reçu à ce jour un financement de 60 M$ en plusieurs de table. Parmi les personnalités qui constitue son état-major on peut citer Steve Wozniak au poste de Chief Scientist.

 puis
puis