
Pour beaucoup hadoop est synonyme de big data. Près d’un tiers des entreprises (de plus de 500 salariés) a entrepris des déploiements de cette technologie et un autre tiers prévoit de le faire dans les 12 mois à venir.
Rappelons qu’hadoop n’est pas une application mais un ensemble de technologies open source regroupant de multiples outils dont l’objectif ultime est d’analyser des volumes de données structurées et non structurées considérables. Comme c’est souvent le cas dans le monde de l’open source, différents fournisseurs proposent un package plus ou moins complet d’applications dont ils ont réalisé l’intégration et testé la compatibilité. Les trois distributions les plus souvent citées par les responsables IT interrogés sont celles de Cloudera, MapR et HortonWorks qui représentent environ 60 % des déploiements mentionnés. Les raisons le plus souvent citées pour choisir une distribution sont le plus souvent des raisons de coûts (administration, stockage, support…) ce qui laisserait à penser que la couverture et la richesse fonctionnelles des différentes distributions sont relativement proches. On peut d’ailleurs noter une très grande variabilité du nombre de nœuds de clusters hadoop implémentés.
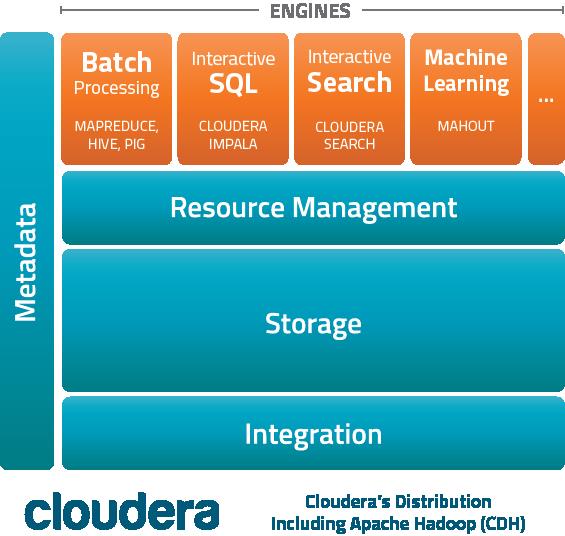
Hadoop pour quoi faire ? Quatre grandes catégories d’applications sont mentionnées par cette enquête réalisée par le cabinet IDC et intitulée Trends in Enterprise Hadoop Deployments. Il y a d’abord l’analyse de données brutes générées automatiquement par des équipements comme des terminaux points de vente pour comprendre les comportements des clients. Depuis longtemps déjà, la distribution a été très consommatrice d’outils de business intelligence et il n’est pas surprenant qu’hadoop fasse partie de cette nouvelle vague d’utilisation.
Près de 4 responsables interrogés sur 10 indiquent utiliser les technologies big data dans le cadre d’innovation de produits et services dans le cadre de la modélisation de données pour tester des scénarios de type If-then else. Des cas moins fréquents d’utilisation d’hadoop incluent des déploiements pour des travaux en conjonction avec des technologies SQL. Une proportion importante utilise hadoop pour remplacer des technologies de data warehouse traditionnelles. Enfin, et cela ne constituera pas une surprise, un pan important d’utilisation concerne l’analyse des volumes de données importants générées par toutes les interactions générées sur le Web. Les données qui alimentent les applications hadoop sont très diversifiées et sont par ordre d’importance décroissante celles issues des SGBD traditionnels, matériels, bases MPP, bases NoSQL, interactions Web, données issues des réseaux sociaux, metadonnées sur les fichiers audio, vidéo…
Une analyse coût / bénéfice montre selon cette enquête que l’investissement dans le déploiement d’une solution hadoop en vaudrait la peine. Dans un cas sur deux, l’investissement serait compris entre 100 000 et 500 000 dollars avec un coût d’administration par cluster hadoop d’environ 2000 dollars par an (une solution cloud de type AWS est bien adaptée à ce type d’application). Côté bénéfices, la grande majorité des personnes interrogées a déjà gagné plus d’un million de dollars sur trois ans ou prévoient de le faire.
Hadoop en remplacement ou en complément ? Pour l’heure, c’est la deuxième option qui est, et de loin, la plus souvent citée. Ce sont les bases de données traditionnelles de type Oracle, Sybase, DB2, MySQL avec lesquelles hadoop est utilisée. Viennent ensuite les bases MPP telles que Vertica ou Greenplum et enfin les bases de données non traditionnelles (NoSQL, Cassandra) telles que HBase ou Cassandra.
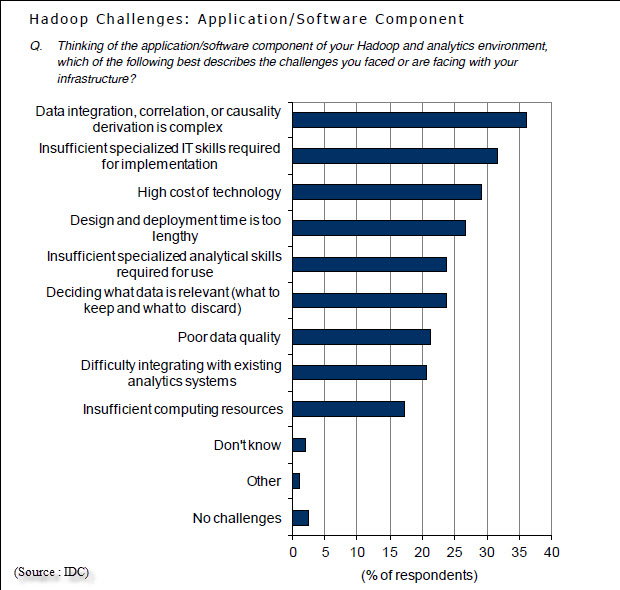
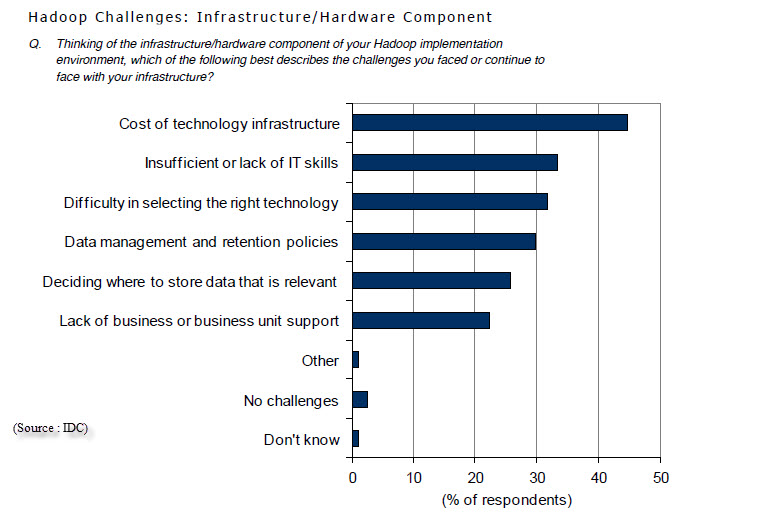
Les trois bénéfices cités en premier par la mise en œuvre des technologies sont – en termes assez généraux il est vrai : améliorer la satisfaction des clients, réduire le temps de développement et de mise sur le marché de produits ou services et la réduction des coûts des opérations. A l’inverse, quelles sont les difficultés rencontrées dans la mise en œuvre d’hadoop ? Côté infrastructure matérielle, ce sont d’abord les coûts, l’insuffisance de compétences disponibles et les difficultés de faire le choix des technologies. Côté applicatif, les difficultés d’intégration des données, de trouver des corrélations ou des causalités (hadoop n’est pas un prestidigitateur qui sort des explications de son chapeau), le manque de compétences disponibles et les coûts. On le voit, les difficultés de trouver des compétences et les coûts trop élevés sont cités au niveau matériel et logiciel.

 puis
puis