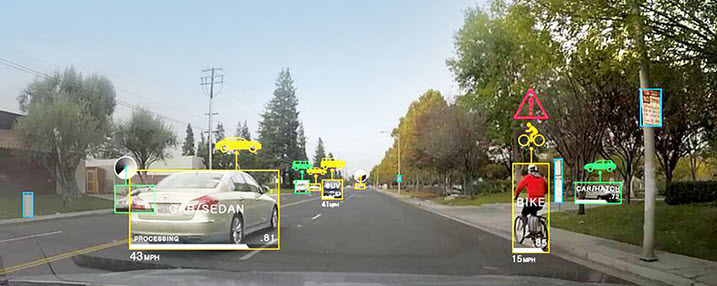
Après quelques années de glaciation dans les années 80/90, l’intelligence artificielle a pris un nouvel essor grâce à une nouvelle approche et l’utilisation de puissance de calcul sans cesse plus importante.
Dans sa leçon inaugurale sur son cours du Collège de France intitulé « L’apprentissage profond : une révolution en intelligence artificielle », Yann LeCun, professeur à l’université de New York et directeur du laboratoire de recherche en intelligence artificielle de Facebook (FAIR) nous rappelle que « l’Intelligence Artificielle (IA) est un ensemble de techniques permettant à des machines d’accomplir des tâches et de résoudre des problèmes normalement réservés aux humains et à certains animaux ».

 Pour faire progresser leur discipline, les chercheurs en intelligence artificielle doivent-ils s’inspirer du fonctionnement du cerveau et de la biologie ? Pour répondre à cette question, Yann LeCun propose l’analogie de l’avion III pour lequel son concepteur Clément Ader s’était attaché à reproduire le vol de la chauve-souris. De fait, son avion a bien réussi à décoller mais fut un échec. Les projets qui ont réussi, notamment celui des Wright Brothers, considérés comme les pères de l’aviation, s’appuyèrent plus sur les lois de la physique. Si l’on veut faire réussir l’intelligence artificielle, il faut selon Yann LeCun, certes s’inspirer du fonctionnement du cerveau mais savoir garder ces distances. D’autant que les systèmes informatiques d’aujourd’hui sont encore très loin des performances du cerveau.
Pour faire progresser leur discipline, les chercheurs en intelligence artificielle doivent-ils s’inspirer du fonctionnement du cerveau et de la biologie ? Pour répondre à cette question, Yann LeCun propose l’analogie de l’avion III pour lequel son concepteur Clément Ader s’était attaché à reproduire le vol de la chauve-souris. De fait, son avion a bien réussi à décoller mais fut un échec. Les projets qui ont réussi, notamment celui des Wright Brothers, considérés comme les pères de l’aviation, s’appuyèrent plus sur les lois de la physique. Si l’on veut faire réussir l’intelligence artificielle, il faut selon Yann LeCun, certes s’inspirer du fonctionnement du cerveau mais savoir garder ces distances. D’autant que les systèmes informatiques d’aujourd’hui sont encore très loin des performances du cerveau.
Car plus nos connaissances avancent et plus on ne peut constater que le cerveau est une machine extraordinaire qui regroupe quelque 85 milliards chacun neurones. Et chaque neurones est en moyenne connectés aux autres neurones via 10 000 synapses en moyenne pour un total de 10^15 représentant 180 000 km de « câblages ». Le tout dans un volume restreint d’environ 2500 cm² et consommant seulement 25 watts (dix fois moins qu’un PC moyen). Dans ces conditions, combien de temps faudra-t-il pour développer un système informatique comparable ? « Nous en sommes à un facteur d’un million ce qui, à la vitesse de la loi de Moore (rien n’est moins sûr que cette loi continue), il faudra donc une trentaine d’années pour être au niveau de puissance de calcul du cerveau, rappelle Yann LeCun, sachant que par ailleurs, l’intelligence n’est pas seulement de la puissance de calcul, il faut également en comprendre les principes de fonctionnement».
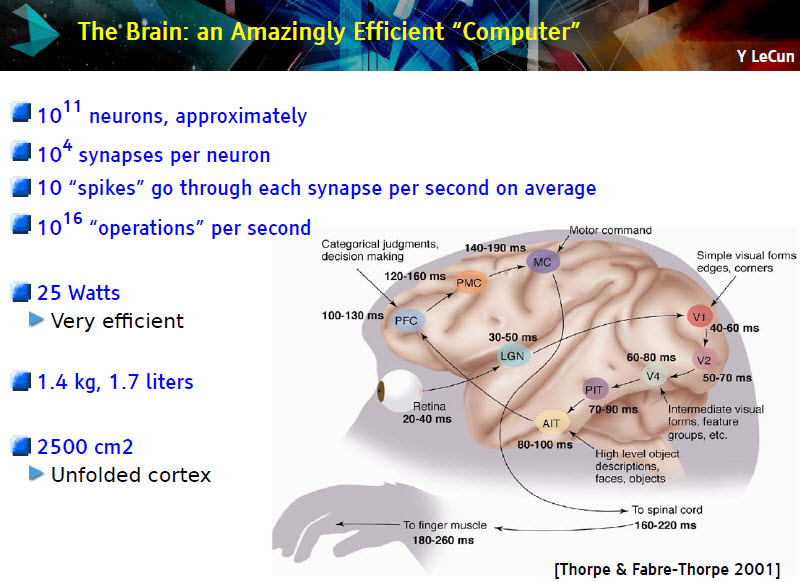
Dans une conférence donnée à Télécom ParisTech en septembre dernier, Jérôme Pesenti, vice-président, Core Technology, chez IBM Watson, qui travaille sur le sujet depuis 20 ans, confirme l’accélération importante de ces cinq dernières dans les capacités des systèmes (L’IA : détruire les emplois pour sauver les entreprises ?) en particulier grâce aux réseaux neuronaux de grande échelle (voir la vidéo ci-dessous). Cela grâce à une nouvelle approche qui s’appuie beaucoup plus sur les méthodes statistiques et non une tentative de copier l’intelligence humaine.
Relier Intelligence et apprentissage
Depuis quelques années, on associe presque toujours l’intelligence aux capacités d’apprentissage. C’est grâce à l’apprentissage qu’un système intelligent capable d’exécuter une tâche peut améliorer ses performances avec l’expérience. C’est grâce à l’apprentissage qu’il pourra apprendre à exécuter de nouvelles tâches et acquérir de nouvelles compétences.
Les méthodes manuelles se sont avérées très difficiles à appliquer pour des tâches en apparence très simples comme la reconnaissance d’objets dans les images ou la reconnaissance vocale. Il est virtuellement impossible d’écrire un programme qui fonctionnera de manière robuste dans toutes les situations. C’est là qu’intervient l’apprentissage machine (qu’on appelle aussi apprentissage automatique). Dans ce domaine, l’apprentissage profond a profondément modifié l’approche. Et les premiers pas dans cette direction ne datent pas d’aujourd’hui puisque rappelle Yann LeCun, la première machine d’apprentissage profond (Deep Learning), le Perceptron, a été développé à l’université Cornell en 1957. Ce n’était même pas un système informatique.
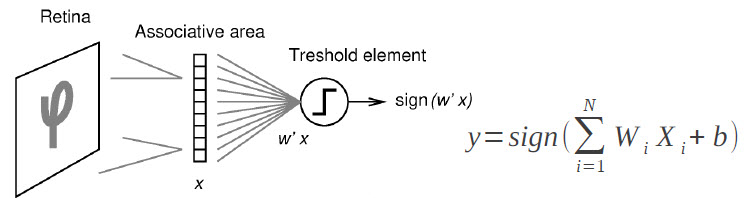
Le principe de fonctionnement expliqué par Yann LeCun est relativement simple : « On montre en entrée de la machine une photo d’un objet, par exemple une voiture, et on lui donne la sortie désirée pour une voiture. Puis on lui montre la photo d’un chien avec la sortie désirée pour un chien. Après chaque exemple, la machine ajuste ses paramètres internes de manière à rapprocher sa sortie de la sortie désirée. Après avoir montré à la machine des milliers ou des millions d’exemples étiquetés avec leur catégorie, la machine devient capable de classifier correctement la plupart d’entre eux. Plus intéressant, elle peut aussi classifier correctement des images de voiture ou de chien qu’elle n’a jamais vues durant la phase d’apprentissage. C’est ce qu’on appelle la capacité de généralisation ».
Partant de ce premier modèle d’apprentissage profond se sont développé de nouvelles approches plus sophistiquées : réseaux multicouches, réseaux convolutifs, réseaux récurrents. Chacune étant particulièrement adaptés à traiter des problèmes particuliers. « Malgré tous ces progrès, nous sommes encore bien loin de produire des machines aussi intelligentes que l’humain ni même aussi intelligentes qu’un rat », conclut-il. Si les machines actuelles sont très performantes mails ultraspécialisées. « Ce qui leur manque c’est la capacité d’apprendre à représenter le monde mais aussi à se remémorer, à raisonner, à prédire et à planifier ».
Programme du cours « L’apprentissage profond : une révolution en intelligence artificielle »
Leçon inaugurale le 4 février 2016, à 18h00 :
L’apprentissage profond : une révolution en intelligence artificielleCours les vendredis à 14h30 (à partir du 12 février), suivis à 15h30 d’un séminaire en relation avec le cours :
- 12 février : Pourquoi l’apprentissage profond ?
- 19 février : Réseaux multicouches et rétropropagation du gradient
- 26 février : L’apprentissage profond en pratique
- 4 mars : Réseaux convolutifs
- 25 mars : Réseaux convolutifs. Applications à la vision
- 1 avril : Réseaux récurrents. Applications au traitement du langage naturel.
- 8 avril : Raisonnement, attention, mémoire.
- 15 avril : L’Apprentissage non-supervisé (cours à 10h00)
Suivi d’un colloque international toute la journée du 15 avril

 puis
puis