
Lorsque le numéro 1 mondial du cloud dysfonctionne, c’est toute la sphère Internet qui s’en trouve perturbée… Une occasion de faire une liste des tableaux de bord de surveillance des clouds…
Tous les grands clouds connaissent des interruptions de service plus ou moins graves et remarquées.
Cette année, Microsoft et Google ont eu leur lot de gros déboires.
Mais AWS avait plutôt été épargné par les incidents majeurs impactant un vaste ensemble de services depuis le début de l’année… Ce qui rend l’incident prolongé de la nuit forcément plus notable.
La panne est survenue sur le service « Kinesis Data Streams » de la région US-EAST-1 affectant donc principalement les sites et services en Amérique du Nord.
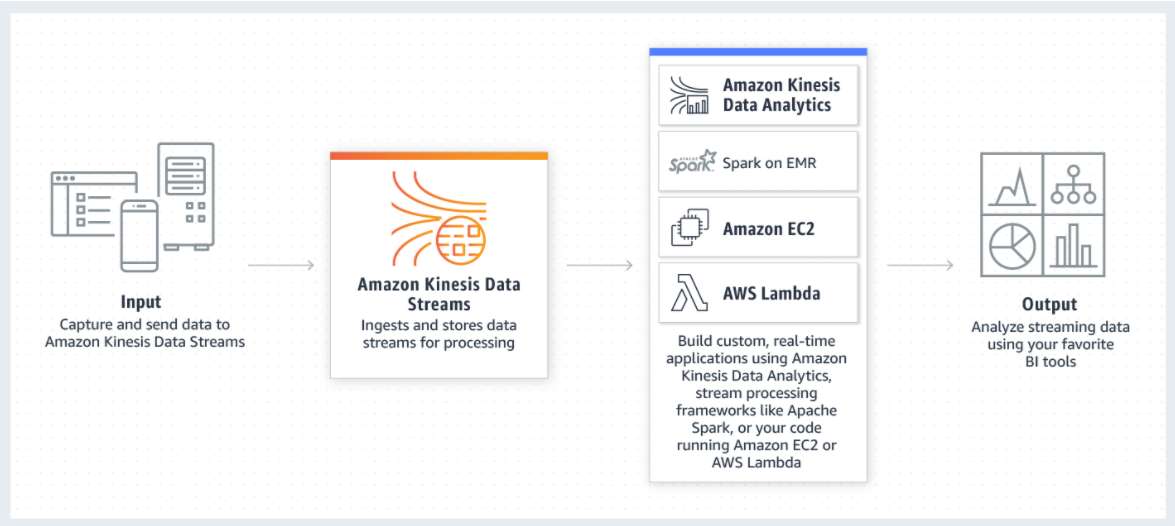 KDS est un service de diffusion de données en temps réel. Il peut capturer en continu des gigaoctets de données par seconde à partir de centaines de milliers de sources telles que les clics de sites Web, les flux d’événements de bases de données, les transactions financières, les flux de médias sociaux, les journaux informatiques et les événements de localisation. Il permet ainsi des analyses en temps réel pour détecter des anomalies, afficher des tableaux de bord, gérer des tarifications dynamiquement. De nombreux sites y font appel à ces fins. Et même si le service n’est pas toujours fondamental, son dysfonctionnement peut perturber le bon fonctionnement des applications, sites et services qui y font appel ne serait-ce que pour surveiller leur bon fonctionnement.
KDS est un service de diffusion de données en temps réel. Il peut capturer en continu des gigaoctets de données par seconde à partir de centaines de milliers de sources telles que les clics de sites Web, les flux d’événements de bases de données, les transactions financières, les flux de médias sociaux, les journaux informatiques et les événements de localisation. Il permet ainsi des analyses en temps réel pour détecter des anomalies, afficher des tableaux de bord, gérer des tarifications dynamiquement. De nombreux sites y font appel à ces fins. Et même si le service n’est pas toujours fondamental, son dysfonctionnement peut perturber le bon fonctionnement des applications, sites et services qui y font appel ne serait-ce que pour surveiller leur bon fonctionnement.
En théorie, un problème sur KDS n’affectant qu’une seule région sur les 23 du cloud AWS aurait presque dû passer inaperçu. Mais ça n’a pas été le cas car le problème a affecté le bon fonctionnement d’autres services AWS et surtout de nombreux sites clés aux USA ont été durablement affectés. C’est notamment le cas de Adobe Cloud et Adobe Spark, 1Password, Autodesk, Coinbase, Glassdoor, Flickr, Pocket, Roku et les sites de plusieurs agences de presse américaines.
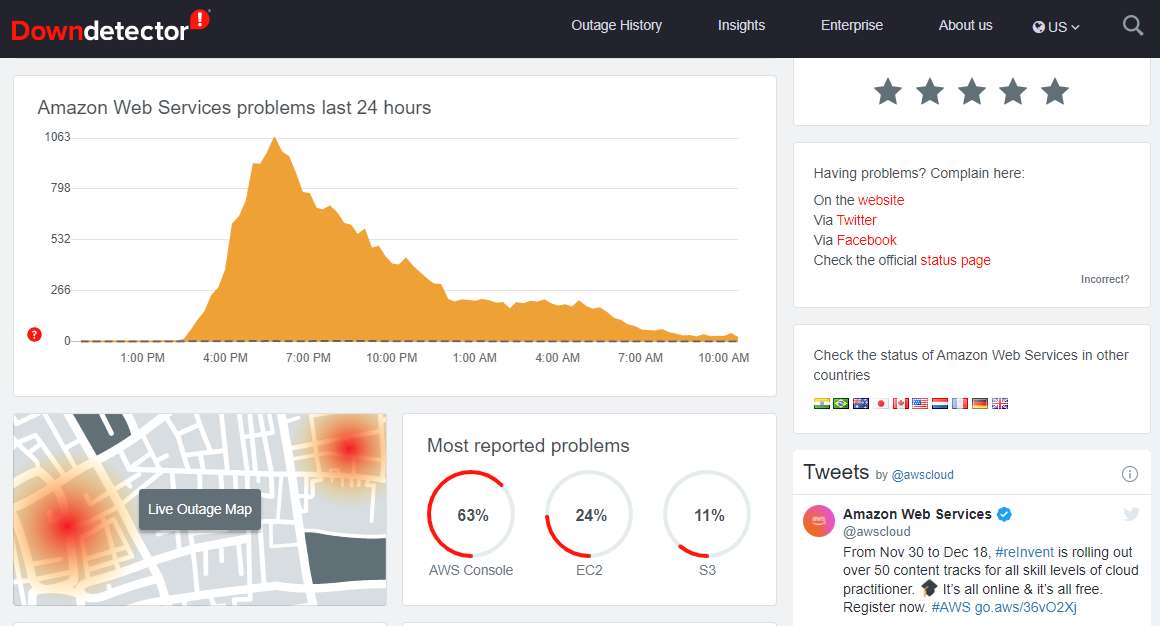 Les problèmes ont commencé hier après-midi vers 15H00 et n’ont cessé de s’aggraver jusqu’à 18H00. Ils ont alors progressivement commencé à se résorber mais la situation est encore imparfaite ce matin si on en croit le site DownDetector.
Les problèmes ont commencé hier après-midi vers 15H00 et n’ont cessé de s’aggraver jusqu’à 18H00. Ils ont alors progressivement commencé à se résorber mais la situation est encore imparfaite ce matin si on en croit le site DownDetector.
Des incidents, les clouds des hyperscalers en connaissent tous les mois. La plupart du temps, ils passent presque inaperçus. D’ailleurs le dernier incident majeur d’AWS remonte à 2017 où un problème sur une région S3 avait affecté des sites comme Trello, GroupMe, IFTTT et même Alexa.
Rappelons également que le confinement brutal du monde avait perturbé Office 365 et Azure à plusieurs reprises entre mars et juin 2020. Google a connu au début du mois de Novembre une panne d’envergure affectant notamment son Play Store et YouTube.
Pour rappel, les différents clouds proposent des sites Web assez complets pour surveiller l’état de leurs services. En voici les principaux :
* Microsoft Azure : État Azure
(il existe aussi un tableau de bord pour Office 365 : Microsoft 365 – Service health)
 * Google Cloud : Google Cloud Status Dashboard
* Google Cloud : Google Cloud Status Dashboard
* Amazon AWS : AWS Service Health Dashboard
* IBM Cloud : IBM Cloud Status
* Oracle Cloud : OCI Status (oraclecloud.com)
* OVHcloud : OVH Tasks
* Scaleway : Scaleway Incidents Status
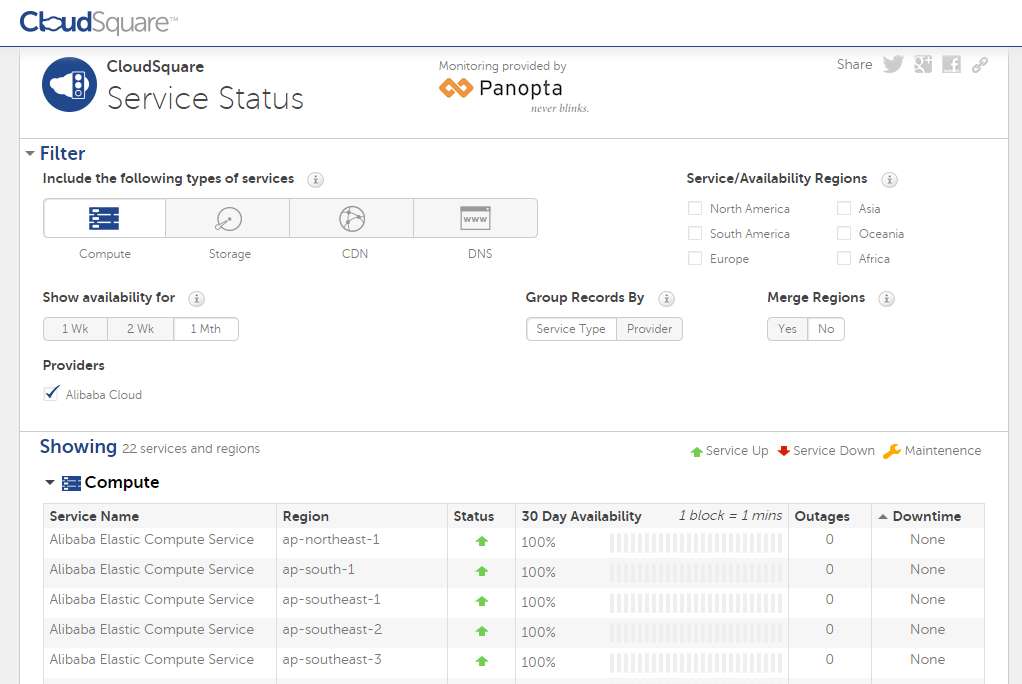
Enfin, ajoutons que CloudSquare, le service de CloudHarmony, permet de surveiller en un seul tableau de bord l’état de services de la plupart des grands services clouds à commencer par Akamai, AlibabaCloud, AWS, Azure, Bitglass, EasyDNS, ExoScale, GCP, Salesforce, Qlik, Tencent Cloud, etc…

 puis
puis