
À l’heure du data mesh, la licorne qui a mis le feu à la bourse New-Yorkaise cet été continue de miser sur son datawarehouse « cloud native » pour fournir un environnement complet de gestion des données.
L’incroyable succès de Snowflake lors de son introduction en bourse fait jaser et nombre d’analystes financiers et techniques s’inquiètent déjà du modèle de la pépite créée à l’origine par deux Français. De fait, Snowflake a réellement créé la rupture, introduisant le concept d’un datawarehouse en mode SaaS, spécialement pensé pour les architectures hybrides. Performante, son offre repose un datawarehouse tout puissant, pivot de la chaine de traitement des données. Une approche que l’éditeur vient renforcer avec une série d’annonces effectuées à l’occasion du Data Cloud Summit 2020.
Un datawarehouse, pivot de la chaine DataOps
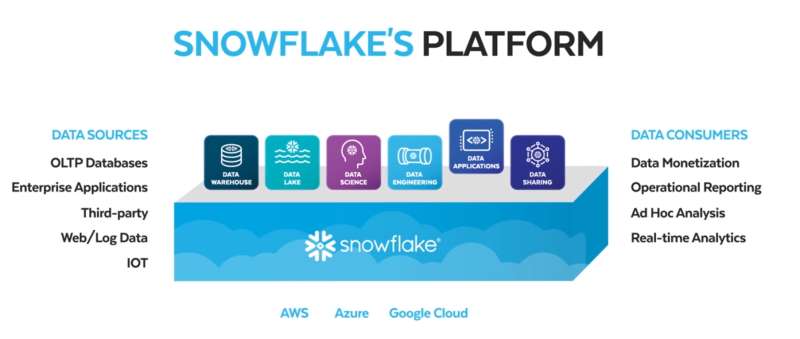 Centré sur son approche « data cloud », Snowflake n’a pas l’intention d’attendre que les acteurs du marché de la data intègrent sa technologie innovante à leur chaine de traitement de la donnée. De fait, l’éditeur multiplie les partenariats et les fonctionnalités pour devenir un acteur incontournable du DataOps avec un centre de gravité autour de l’entrepôt de données.
Centré sur son approche « data cloud », Snowflake n’a pas l’intention d’attendre que les acteurs du marché de la data intègrent sa technologie innovante à leur chaine de traitement de la donnée. De fait, l’éditeur multiplie les partenariats et les fonctionnalités pour devenir un acteur incontournable du DataOps avec un centre de gravité autour de l’entrepôt de données.
En octobre dernier, Snowflake donnait déjà le ton en annonçant un partenariat avec Boomi, leader sur le marché de l’iPaaS qui possède également une solution de Data Catalogue. Intégrés à Snowflake, ces outils permettent de découvrir et explorer les informations éparpillées dans le système d’information et de gérer des flux de données en temps réel issus, par exemple, de l’IOT.
Aujourd’hui, l’éditeur annonce qu’il vient d’intégrer Apache Kafka et qu’il propose désormais un environnement serverless, simplifiant ainsi la création et la gestion de pipeline de données.
Un IDE data intégré
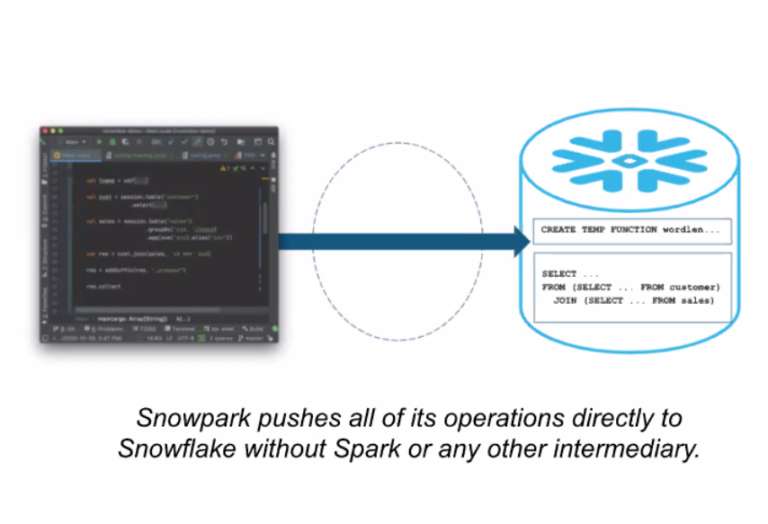 Parallèlement, et afin d’offrir un environnement complet de gestion des données associé à son datawarehouse, l’éditeur propose désormais un IDE baptisé SnowPark. Destiné aux analystes, datascientists et autres développeurs, il permet notamment de créer des « job » au sens ETL pour extraire et transformer des données avant de les injecter dans le datawarehouse ou encore d’affiner les paramétrages d’un modèle ML. Exécuté dans l’environnement Snowflake, cet IDE est multilangage et autorise l’utilisation de bibliothèques externes. Le développeur peut ainsi programmer avec le langage de son choix (SQL, Java, Python, Scala, …) et debugger son code sans sortir de l’environnement Snowflake. Au-delà de l’aspect IDE intégré, Snowpark favorise l’exécution de tâches de préparation de données, de data engineering ou de data science directement dans Snowflake sans passer par des plateformes de traitement externes comme Apache Spark. Des tâches de transformation qui s’exécutent en mode serverless, les développeurs n’ayant pas à se préoccuper d’allocations de ressources et d’infrastructure d’exécution.
Parallèlement, et afin d’offrir un environnement complet de gestion des données associé à son datawarehouse, l’éditeur propose désormais un IDE baptisé SnowPark. Destiné aux analystes, datascientists et autres développeurs, il permet notamment de créer des « job » au sens ETL pour extraire et transformer des données avant de les injecter dans le datawarehouse ou encore d’affiner les paramétrages d’un modèle ML. Exécuté dans l’environnement Snowflake, cet IDE est multilangage et autorise l’utilisation de bibliothèques externes. Le développeur peut ainsi programmer avec le langage de son choix (SQL, Java, Python, Scala, …) et debugger son code sans sortir de l’environnement Snowflake. Au-delà de l’aspect IDE intégré, Snowpark favorise l’exécution de tâches de préparation de données, de data engineering ou de data science directement dans Snowflake sans passer par des plateformes de traitement externes comme Apache Spark. Des tâches de transformation qui s’exécutent en mode serverless, les développeurs n’ayant pas à se préoccuper d’allocations de ressources et d’infrastructure d’exécution.
Enfin, à l’occasion de ce Data Cloud Summit, Snowflake a aussi déroulé une série d’améliorations apportées à son datawarehouwe, tant du point de vue des performances que des fonctionnalités avec notamment la prise en charge des données non structurées ou encore un niveau de granularité plus fin sur les politiques de gestion d’accès aux données (Row-Access Policies). Ces nouvelles politiques viennent compléter les fonctionnalités de « Data Masking » introduites cette année.
Du déjà vu ?
À l’heure de la virtualisation, des data catalogues boostés à l’IA et surtout du data mesh, qu’on peut aussi traduire par l’urbanisation des données, force est de constater que le modèle Snowflake n’apparaît plus aussi innovant. Certes, son datawarehouse est puissant et il répond à des besoins réels. Mais associer des outils à son datawarehouse pour proposer un environnement intégré et complet de gestion de la donnée est un modèle que Terradata pratique depuis plus de 20 ans. Gérer la donnée non structurée, est, à notre époque, une nécessité, pas un plus. Et concevoir et administrer des flux de données – batch ou temps réel – est un domaine mature sur lequel l’ETL et l’iPaaS gouvernent allègrement depuis déjà quelques années.
En un sens, Snowflake s’aligne ici sur ce que d’autres font déjà, parfois depuis très longtemps. Et son modèle centralisateur va peut-être à contrecourant. Certes, l’informatique a toujours oscillé entre trop de centralisation et pas assez, les architectures de données n’échappant pas à la règle. Mais la tendance aujourd’hui n’est pourtant plus à la centralisation. Le besoin d’entrepôt de données n’a pas disparu. Il a son utilité. Mais il existe aujourd’hui des approches beaucoup plus innovantes sur fond d’intelligence artificielle pour exploiter les données éparpillées dans le système d’information sans avoir à les déplacer pour les centraliser. Les entreprises veulent pouvoir exploiter toutes les données – structurées ou non – éparpillées dans le système d’information sans présumer à l’avance de ce qu’elles vont en faire. Autrement dit sans les organiser préalablement dans un modèle d’entrepôt qui tend à réduire l’univers du possible à ce qui a été prévu.
Un modèle Business porté par la centralisation
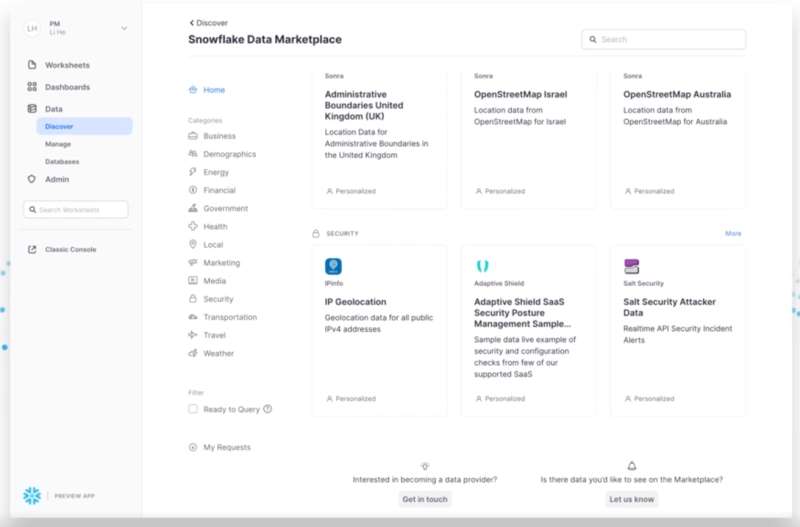 Le problème, c’est que l’aspect très centralisateur de Snowflake est au cœur de sa stratégie. Dans un sens, c’est logique, l’idée du cloud étant celle d’une centralisation. Et l’éditeur parie toute sa stratégie Business là-dessus. Plus le temps passe, plus la solution cherche à s’affirmer comme l’hypermarché de la donnée où partenaires et clients viennent vendre et acheter de la donnée.
Le problème, c’est que l’aspect très centralisateur de Snowflake est au cœur de sa stratégie. Dans un sens, c’est logique, l’idée du cloud étant celle d’une centralisation. Et l’éditeur parie toute sa stratégie Business là-dessus. Plus le temps passe, plus la solution cherche à s’affirmer comme l’hypermarché de la donnée où partenaires et clients viennent vendre et acheter de la donnée.
Snowflake avait déjà introduit un Data Marketplace pour permettre aux entreprises d’échanger et monétiser leurs données. Il étend désormais celui-ci avec un portail « Data Services Marketplace » par lequel les entreprises peuvent acheter ou vendre des services de données sans pour autant communiquer/partager leurs données : typiquement les entreprises pourront y exploiter des fonctions de Risk management, de vérification d’adresses, de scoring comportemental, d’analyses avancées, etc. Par exemple, une entreprise de cybersécurité pourrait vendre juste un service permettant de savoir si un login a été dérobé et se retrouve dans des bases du DarkWeb (qu’elle aurait importées dans Snowflake).
L’idée générale va donc bien au-delà de vendre de la donnée pour s’étendre à l’idée de vendre des services centrés sur les données.
Tel est le pari actuel de Snowflake. Reste à savoir si cette centralisation à marche forcée sera aussi le pari de la plupart des entreprises.

 puis
puis