
Les entreprises aux États-Unis pourraient perdre 15 milliards de dollars si un grand fournisseur de services de cloud connaissait une période d’indisponibilité d’au moins trois jours.
C’est ce qu’indique le rapport Cloud Down Impacts on the US economy que vient de publier la société britannique Lloyd’s, le spécialiste de l’assurance et de la réassurance, en partenariat avec Air Mondial. Ce rapport donne une évaluation des impacts sur l’économie américaine, qui analyse l’impact financier de la défaillance d’un important fournisseur de cloud aux États-Unis. Ce rapport est centré sur les Etats-Unis mais peut être facilement transposé sur l’ensemble des pays dans lesquels les services cloud sont largement développés et deviennent désormais critique dans le fonctionnement des économies.
On le sait, nos économies sont de plus interconnectées et interdépendantes et donc fragiles. Une panne ou un dysfonctionnement sur un secteur peut se propager assez facilement sur l’ensemble de l’économie. Conséquence logique, le cyber-risque est donc de plus en plus. Non seulement il y a plus d’entreprises s’appuyant sur les services cloud pour gérer et développer leur activité, mais les économies d’échelle ont entraîné une sélection de quelques fournisseurs de services de cloud qui dominent le marché. Le « gang des quatre » – AWS, Microsoft, Google et IBM – possède plus de 50 % du marché.
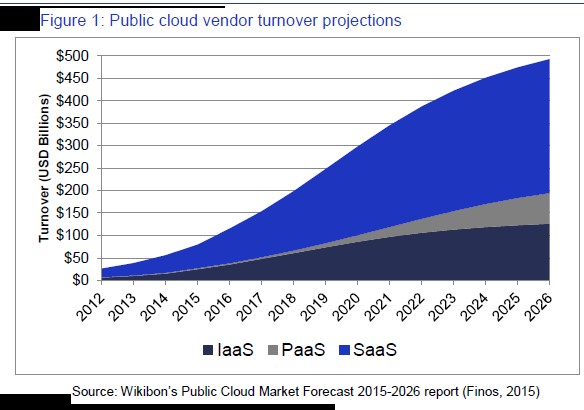
Cette dépendance à l’égard d’un nombre relativement restreint de fournisseurs a entraîné un risque systémique pour les entreprises utilisant leurs prestations de service. En cas de panne prolongée d’un fournisseur majeur de services de cloud, dommage simultané pour tous ses clients pourraient conduire à des catastrophes et des pertes financières. Selon le cabinet McKinsey, à partir de 2015, 77% des entreprises mondiales utilisent des systèmes informatiques traditionnels infrastructure (c’est-à-dire avec des serveurs on-premise) comme environnement primaire pour au moins une charge de travail (c’est-à-dire une tâche informatique) ; cela devrait tomber 43% en 2018. Alors que seulement environ 25% des entreprises 2015 ont utilisé des infrastructures de cloud public comme environnement principal pour au moins une charge de travail, ce pourcentage devrait atteindre 37% en 2018.
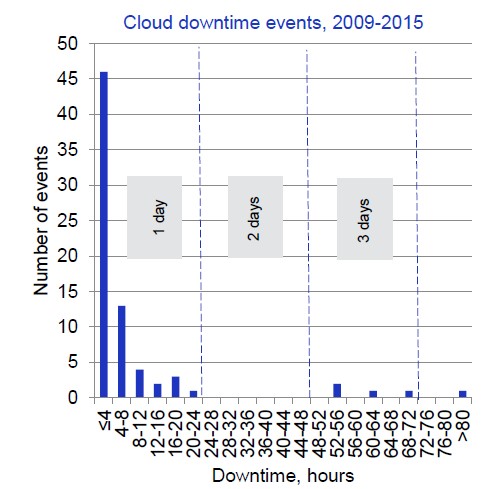 Le rapport analyse les pertes pour 12,4 millions d’organisations américaines et propose une approche alternative pour aider les assureurs à modéliser ces risques, qui sont généralement plus difficiles à évaluer que d’autres catastrophes comme les catastrophes naturelles dues à la nature complexe et hautement interconnectée du monde numérique. Les statistiques entre 2009 et 2015 montrent que les pannes sont le plus souvent inférieures à 24 heures.
Le rapport analyse les pertes pour 12,4 millions d’organisations américaines et propose une approche alternative pour aider les assureurs à modéliser ces risques, qui sont généralement plus difficiles à évaluer que d’autres catastrophes comme les catastrophes naturelles dues à la nature complexe et hautement interconnectée du monde numérique. Les statistiques entre 2009 et 2015 montrent que les pannes sont le plus souvent inférieures à 24 heures.
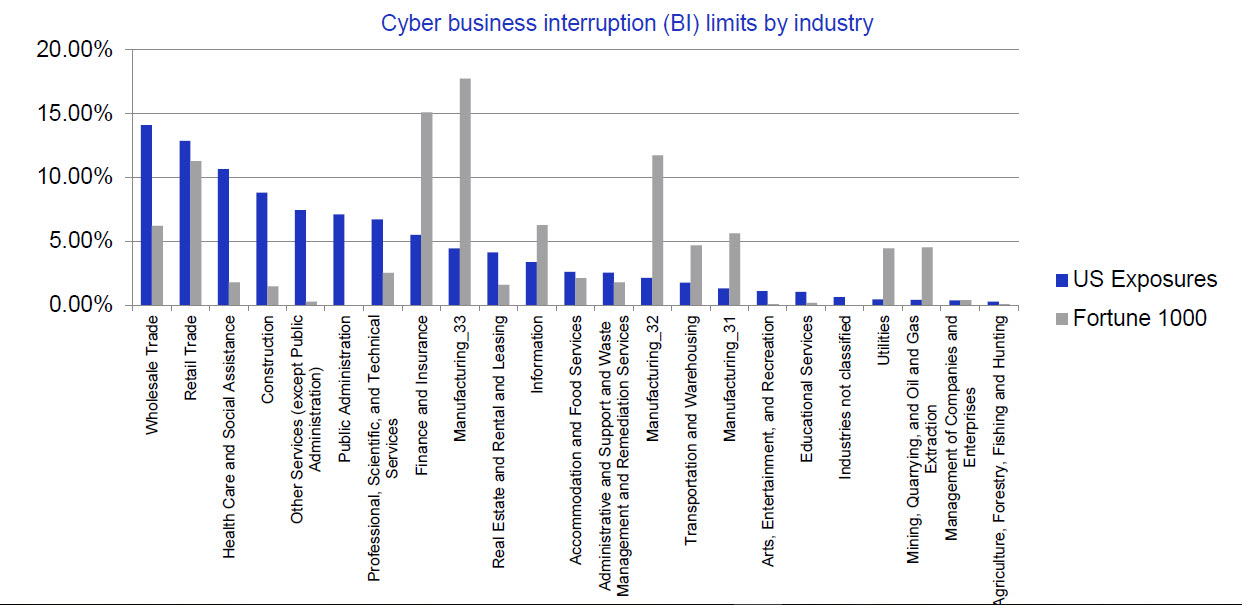
Dans ce rapport, il a été constaté que les entreprises de taille moyenne qui n’appartiennent pas au classement Fortune 1000 – celles qui sont plus susceptibles d’utiliser des services de fournisseur de cloud – porteraient une plus grande part des pertes économiques et d’assurance que les grandes entreprises du Fortune 1000. Cependant, les 1000 plus grandes entreprises des États-Unis subiraient 38% des pertes économiques en cas de pannes du cloud.
Parmi les principales conclusions du rapport :
Un incident informatique extrême qui mettrait un fournisseur de cloud hors ligne aux États-Unis pendant 3 à 6 jours entraînerait des pertes économiques de 15 milliards de dollars et des pertes assurées de 3 milliards de dollars.
Les entreprises hors du Fortune 1000 porteraient 63% des pertes économiques et 57% des pertes assurées, ce qui indique qu’elles sont les plus à risque.
Comme tout résultat de modèle, ces chiffres comportent des incertitudes et AIR estime avec un intervalle de confiance à 95% des pertes comprises entre 11 à 19 milliards de dollars avec une moyenne de 15 milliards de dollars. Avec un impact très différencié selon les secteurs économiques :
– L’industrie manufacturière serait la plus touchée avec des pertes économiques directes évaluées à 8,6 milliards de dollars ;
– Les secteurs du commerce de gros et de détail subiraient des pertes économiques de 3,6 milliards de dollars ;
– Les pertes des secteurs de l’information, de la finance et de l’assurance, et du transport sont évaluées respectivement à 850, 450 et 440 milliards de dollars.
10 interruptions majeures du cloud en 2017 (source CRN)
IBM, le 26 janvier
La crédibilité d’IBM en matière de cloud a pris un coup d’arrêt en début d’année, lorsqu’un portail de gestion utilisé par les clients pour accéder à son infrastructure cloud Bluemix (rebaptisé IBM Cloud et anciennement SoftLayer) s’est effondré pendant plusieurs heures.
Bien qu’aucune infrastructure sous-jacente n’ait réellement échoué, les utilisateurs ont été frustrés de constater qu’ils ne pouvaient pas gérer leurs applications ou ajouter ou supprimer des ressources cloud alimentant les charges de travail. IBM a déclaré que le problème provenait d’une mauvaise mise à jour de l’interface.
2. GitLab, 31 janvier
GibLab.com, le populaire référentiel de codes en ligne de GitLab, a subi une panne de service de 18 heures qui n’a finalement pas pu être entièrement corrigée. Le problème est survenu lorsqu’un employé a supprimé un répertoire de base de données du mauvais serveur de base de données au cours des procédures de maintenance. Certaines données de production client ont finalement été perdues, y compris des modifications aux projets, aux commentaires et aux comptes.
3. Instapaper, 9 février
Une limite de taille de fichier pour une base de données MySQL sur le service RDS d’Amazon a déclenché une panne prolongée sur la propriété Pinterest. Le site de bookmarking en ligne a par la suite rapporté que ses ingénieurs ne connaissaient même pas la limite RDS de 2 To pour les bases de données créées avant avril 2014 et que le service AWS ne leur avait pas averti que la table stockant ses « signets » allait le dépasser. Après avoir été en panne pendant plus d’une journée, le service d’Instapaper a été relancé avec un accès limité aux documents archivés pendant que les ingénieurs travaillaient pour relancer le reste de la base de données. Quatre jours plus tard, Instapaper avait complètement récupéré.
4. Facebook, 24 février
Pendant près de trois heures, certains utilisateurs à travers le monde ont été exclus de Facebook et inquiets que leurs comptes aient été détournés. Le géant des réseaux sociaux a expliqué que les fonctionnalités destinées à se prémunir contre les pirates envoyaient par inadvertance des utilisateurs vers un écran de récupération donnant l’impression que quelqu’un d’autre s’était connecté à leurs comptes. Les utilisateurs concernés ont été empêchés de se reconnecter immédiatement. Facebook a confirmé qu’aucune violation réelle de la sécurité n’avait eu lieu.
5. AWS, 28 février
Un ingénieur d’Amazon Web Services essayant de déboguer un système de stockage S3 dans le data center de Virginie du fournisseur a accidentellement tapé une commande incorrecte, et une grande partie d’Internet – y compris de nombreuses plates-formes d’entreprise comme Slack, Quora et Trello – a été arrêtée pendant quatre heures.
6. Microsoft Azure, le 16 mars
Les problèmes de disponibilité du stockage ont perturbé le cloud public Azure de Microsoft pendant plus de huit heures, affectant principalement les clients des États-Unis de l’Est.
Certains utilisateurs ont eu des difficultés à provisionner un nouveau service de stockage ou à accéder aux ressources existantes dans la région. Une équipe d’ingénierie de Microsoft a ensuite identifié un cluster de stockage comme le responsable de cette panne. En plus de ce problème, Microsoft a également répertorié sur la page d’état Azure une erreur logicielle affectant le provisionnement du stockage sur plusieurs services pendant plus d’une heure.
7. Microsoft Office 365, 21 mars
Plusieurs services cloud Microsoft pour les entreprises et les particuliers, y compris les services de stockage et de messagerie Office 365, sont devenus inaccessibles en raison de problèmes d’authentification des utilisateurs. L’indisponibilité généralisée a empêché les clients d’accéder au stockage OneDrive, à la collaboration Skype, au courrier électronique Outlook et aux produits grand public tels que Xbox Live.
8. Lululemon sur IBM, 22 mai
Le site Internet du détaillant de matériel de yoga populaire est devenu un gros problème lorsque le PDG de l’entreprise a braqué les projecteurs sur les services cloud gérés par IBM.
9. Microsoft Skype, le 19 juin
Les utilisateurs de Microsoft Skype, principalement en Europe, ont subi des problèmes de connectivité en raison d’une attaque par déni de service distribué. Les utilisateurs de Skype ont commencé à se plaindre des heures d’indisponibilité le 19 juin. Les problèmes se sont poursuivis le jour suivant, les utilisateurs perdant leur connectivité et éprouvant des difficultés à échanger des messages sur la plate-forme de communication.
10. Apple iCloud, 28 juin
Plusieurs flux de médias sociaux ont signalé des problèmes de disponibilité avec le service iCloud Backup d’Apple. La page d’état des systèmes d’Apple indique qu’iCloud Backup n’était en panne que pour moins de 1% des utilisateurs. Le problème par lequel les personnes affectées ne pouvaient pas restaurer les appareils iOS à partir des sauvegardes précédentes, a duré au moins 36 heures.

 puis
puis