
La dernière version du connecteur Spark développé par Snowflake et estampillée 2.6.0 apporte deux nouveautés qui se traduisent par des temps de traitement des requêtes considérablement réduits. Jusqu’à 10 fois selon l’éditeur qui a réalisé des tests sur une base de données de 16,3 Go répartie sur un cluster de 4 machines sur AWS.
La popularité croissante d’Apache Spark dans l’univers de la Data Science rend critique les performances des connecteurs et essentielle la prise en compte des dernières fonctionnalités du moteur analytique. La nouvelle version du connecteur Spark de Snowflake était donc très attendue par les entreprises clientes du datawarehouse cloud.
Première nouveauté, les requêtes sont exécutées directement via Java Database Connectivity et les données sont désérialisées en utilisant le nouveau format de restitution en colonne Apache Arrow, coté client. Avec un gain de temps dans la lecture des données ainsi présentées.
Seconde amélioration, les informations les plus fréquemment accédées sont désormais stockées et accessibles dans un cache, et donc disponibles sans nouvelles requêtes.
Les 2 mécanismes peuvent bien entendu êtes exploités conjointement, ce qui explique le très important gain de performance.
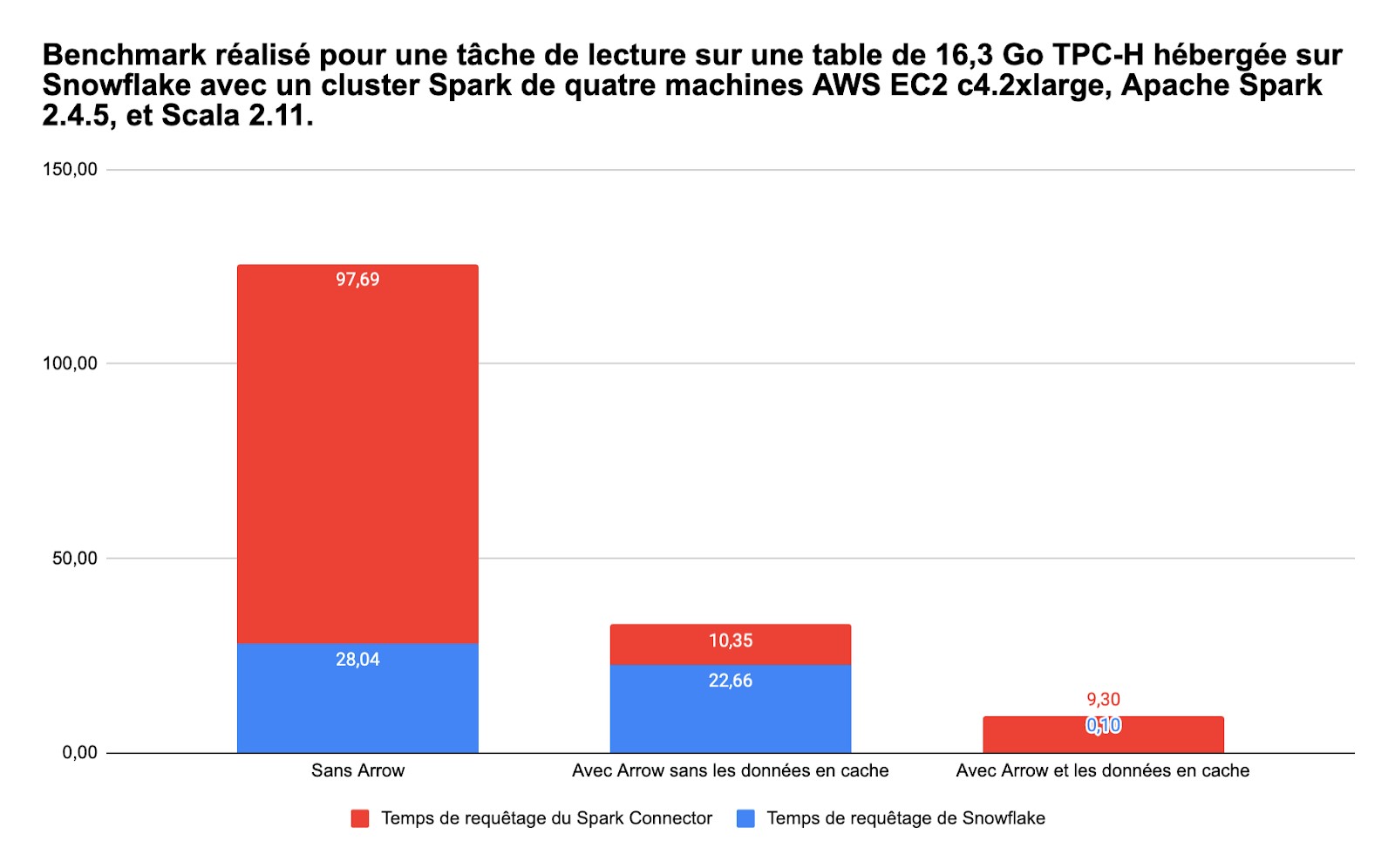
Les entreprises disposent ainsi d’un datawarehouse conçu pour le cloud, multi architectures, et qui accède quasi instantanément à certaines données, quelque soit le type de travaux y compris les développements d’applications modernes. Rappelons que Snowflake, qui a fait son apparition sous AWS dès 2014, est disponible sous Azure depuis 2018 et sur Google Cloud Platform depuis quelques semaines.
Découvrez l’architecture du datawarehouse né pour et dans le cloud en vidéo et en moins de deux minutes.

 puis
puis