IBM, Amazon et MapR se sont engagés massivement sur Spark, le module du Framework hadoop qui fait passer ce dernier du mode batch à celui du temps réel et d’une utilisation en transactionnel. C’est IBM qui a tiré le premier en annonçant qu’il allait placer Spark au cœur de ses plates-formes analytics et de commerce électronique à l’offre Paas Bluemix et spécialiser 3500 chercheurs et développeurs dans une douzaine d’IBM Labs sur ce moteur in-memory de calcul sur un cluster de mémoires (Avec Spark, IBM continue à investir massivement dans le big data).

A l’occasion du Spark Summit qui s’est tenu cette semaine à San Francisco, MapR creusait le même sillon en présentant 3 solutions de démarrage rapide MapR Quick Start basées sur Apache Spark pour la distribution MapR avec Apache Hadoop (MapR propose trois solutions Spark).
Amazon Web Services ne pouvait pas rester immobile. AWS a mis à niveau son service EMR ((Elastic MapReduce) qui supporte désormais la version 1.3.1 de Spark et support Yarn. La précédente version supportait déjà Spark mais l’intégration rend l’utilisation du moteur In-memory plus simple. Utiliser Spark sur EMR sur une instance de base c3.xlarge en coûtera 0,263 dollar/heure. Des services plus étoffés sont également proposés avec des solutions optimisées côté mémoire ou stockage. Le prix est proportionnel au nombre de nœuds utilisés.
Spark a été conçu pour accélérer le traitement des données autant que faire se peut. Les applications qui nécessitent de charger les données sollicitent lourdement les entrées/sorties ce qi est très pénalisant. Contrairement à Hadoop, Spark n’a pas de système de fichiers en propre mais possède sa structure de donnes baptisée RDD (Resilient Distributed Data). RDD est une structure de données conçu pour être tolérante aux pannes et qui peut être distribuée sur la mémoire des différents serveurs du cluster entraînant une amélioration des performances importantes. RDD peut être rempli à partir de données issues du système de fichiers HDFS, de fichiers stockées sur des systèmes NAS ou de bases de données.

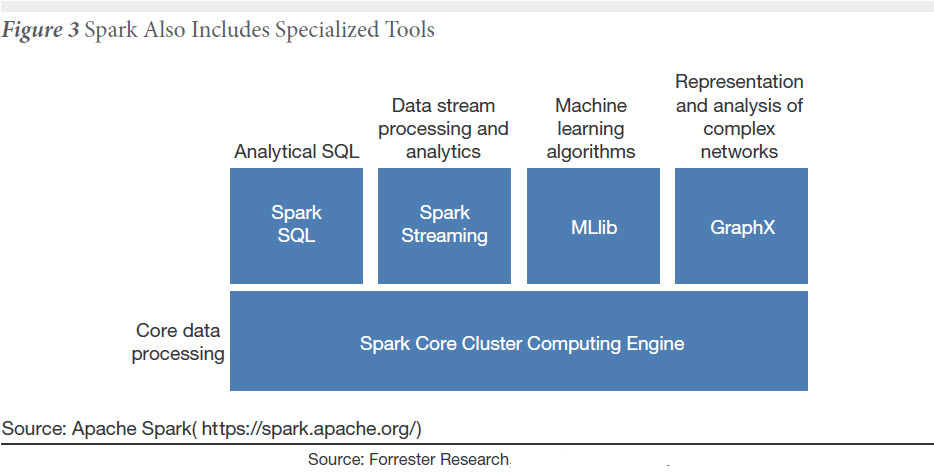
Spark inclut des outils spécialisés tels que Spark SQL, Spark Streaming, une API permettant aux développeurs de prendre en compte des données en temps réel (IoT, twitter, systèmes SCADA…), Mlib pour les machines learning et Graph X.

 puis
puis