
Alors qu’avec l’arrivée des modèles de raisonnement, les débats sur la proximité ou non des AGI sont relancés, le benchmark ARC-AGI-2 officialisé cette semaine éclaire le chemin qui reste à parcourir et démontre les lacunes de nos actuelles IA que les chercheurs vont désormais chercher à combler.
La Fondation ARC Prize vient enfin de dévoiler ARC-AGI-2, un benchmark en gestation depuis de nombreux mois et spécifiquement conçu pour évaluer les progrès des acteurs de l’IA et leur progression vers l’intelligence artificielle générale (AGI).
ARC-AGI-2 succède ainsi enfin à ARC-AGI-1, un benchmark élaboré en 2019, trois ans avant l’arrivée de ChatGPT et à une époque où l’on parlait bien davantage de Deep Learning que de LLM ou d’IA générative.
ARC-AGI-2 conserve un point commun avec ARC-AGI-1 : être plutôt facile pour les humains mais difficile pour les IA. Sauf que le benchmark ARC-AGI-2 place la barre désormais beaucoup plus haut.
Il se compose de 120 tests ou tâches d’évaluation (contre 100 précédemment). Les anciennes tâches vulnérables aux techniques de recherche par force brute (autrement en multipliant les heures et ressources de calculs) ont été éliminées du benchmark. L’idée est de s’assurer que l’IA est suffisamment « intelligente » pour résoudre – sans y passer des heures de calcul – des tests que l’intelligence humaine résout simplement. Et de nouvelles tâches ont été spécifiquement conçues pour défier les systèmes de raisonnement IA de nouvelle génération.
Si certains tests qui composent ce Benchmark sont triviaux pour n’importe quel humain, d’autres sont déjà plus élaborés au point qu’en moyenne, les humains ne réalisent qu’un score de 60%. Néanmoins chaque test a été calibré de sorte qu’au moins deux humains réussissent à le résoudre en deux tentatives maximum.
Par ailleurs, ARC-AGI-2 fait un focus sur « l’intelligence adaptative » afin d’évaluer trois capacités humaines que les IA génératives actuelles ont encore du mal à maîtriser :
– l’interprétation symbolique (capacité à comprendre et manipuler des symboles ou des concepts abstraits ainsi que les relations cachées entre ces symboles),
– le raisonnement compositionnel (capacité à construire ou déduire des réponses complexes en combinant plusieurs informations simples)
– l’application contextuelle des règles (capacité à adapter des règles générales à une situation spécifique, comme par exemple, comprendre que les règles d’un jeu doivent être appliquées différemment selon le contexte ou l’environnement..)
Mais la plus importante différence avec ARC-AGI-1, c’est que cette version 2 introduit une métrique d’efficience (coût par tâche). Autrement dit, il ne s’agit plus pour l’IA de simplement « passer les tests » du benchmark ARC-AGI-2, mais de les réussir avec un maximum d’efficacité et donc à moindre coût aussi bien pécuniaire qu’écologique.
Un écart impressionnant entre humains et machines
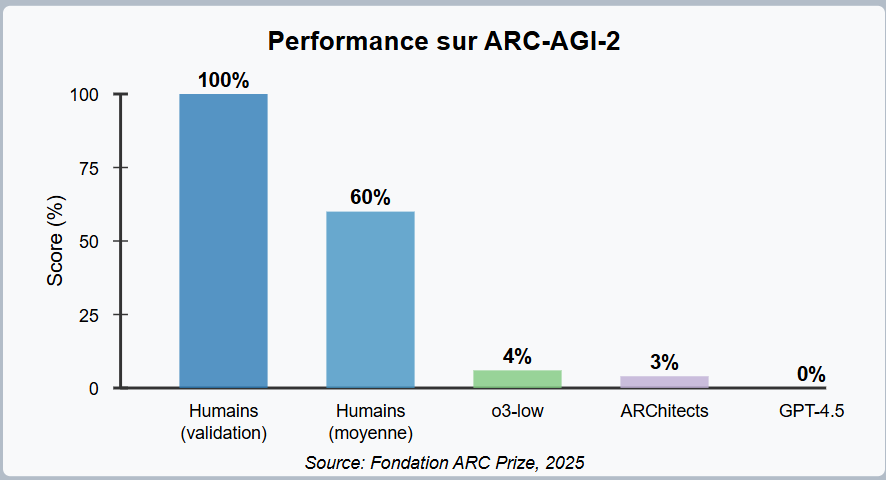
Et les résultats initiaux sont frappants : même les systèmes d’IA les plus avancés peinent sur ce benchmark. OpenAI o3-low (utilisant Chain-of-Thought et synthèse) n’atteint que 4% de réussite, tandis que les grands modèles de langage purs comme GPT-4.5 affichent un score de 0% !
On rappellera que la sortie d’ARC-AGI-2 a été rendue plus urgente et importante quand, pour la première fois, la divulgation du modèle OpenAI o3 a démontré sur ARC-AGI-1 que les IA avaient dépassé le stade de la mémorisation et du mimétisme pour démontrer une réelle intelligence fluide.
Pour autant ce même modèle OpenAI o3, considéré comme le modèle de raisonnement le plus avancé actuellement, n’atteint qu’un piètre score de 4% sur ARC-AGI-2 illustrant l’étendue du chemin qui reste à parcourir.
Et pour motiver la R&D, parallèlement au lancement du benchmark, la Fondation ARC Prize organise le concours « ARC Prize 2025 » avec une dotation totale d’un million de dollars. Le grand prix de 700 000$ sera débloqué dès qu’une équipe atteindra 85% de réussite sur ARC-AGI-2 dans les limites d’efficience fixées par Kaggle. La compétition démarre cette semaine et se poursuivra jusqu’en novembre 2025. Contrairement au tableau de classement public, les règles de Kaggle restreignent l’utilisation d’API internet et limitent les ressources de calcul à environ 50$ par soumission.
Au final, l’ambition des créateurs du benchmark est claire : faire d’ARC-AGI 2 l’étoile Polaire qui guidera la recherche vers l’AGI, en orientant les efforts vers des systèmes capables d’intelligence générale, en accélérant les découvertes algorithmiques et en s’assurant de l’efficience avec laquelle ces capacités sont acquises et déployées.

 puis
puis