
Avec huit variantes et une architecture hybride pensée pour l’optimisation des coûts et du raisonnement, la famille de modèles Qwen 3 d’Alibaba réaffirme l’ambition technologique chinoise face aux géants occidentaux de l’IA.
Depuis 2023, la famille de modèles IA ouverts « Qwen » d’Alibaba s’est imposée comme l’alternative chinoise la plus crédible aux modèles occidentaux : Qwen 1 avait posé les bases d’une approche « open weight » et Qwen 2 avait prouvé qu’il fallait vraiment compter sur l’innovation Chinoise.
Cette semaine, Alibaba a dévoilé Qwen 3. Une évolution majeure de ses modèles qui entendent désormais non seulement faire de l’ombre à DeepSeek R1 (alors que DeepSeek R2 semble devoir arriver dans les prochains jours) mais aussi rivaliser avec les ténors propriétaires issus de Google et d’OpenAI sur le terrain des IA à raisonnement.
La nouvelle génération se décline en huit variantes, de 0,6 à 235 milliards de paramètres. Les six modèles « denses » et deux modèles Mixture-of-Experts (MoE) sont publiés sous licence Apache 2.0 sur Hugging Face et GitHub. Le fer de lance, Qwen3-235B-A22B (235 milliards de paramètres mais 22 milliards activés simultanément grâce à l’approche MoE), n’est pas encore téléchargeable mais sert de vitrine ; la version la plus volumineuse réellement disponible aujourd’hui est le très universel Qwen3-32B.
Alibaba insiste sur la notion de modèle « hybride ». Chaque Qwen3 alterne à la demande entre un mode « thinking », qui déroule une chaîne de raisonnement complète, et un mode « non-thinking » pour les réponses expéditives. « Nous avons intégré de manière fluide les modes de réflexion et de non-réflexion, offrant aux utilisateurs la possibilité de contrôler le budget de réflexion », explique l’équipe dans son billet officiel. La logique MoE, plus économe en ressources, complète ce pilotage fin des coûts d’inférence.
Sous le capot, la phase de pré-entraînement a plus que doublé : 36 000 milliards de tokens, issus de 119 langues, enrichis par du contenu synthétique orienté code et mathématiques. La fenêtre contextuelle est étendue à 32.000 tokens. Résultat : un Qwen3-8B dense rivalise désormais avec l’ancien Qwen2.5-14B, et le MoE Qwen3-30B-A3B obtient des scores comparables à un dense de même génération dix fois plus lourd.
Côté benchmarks, Qwen3-235B-A22B devance facile ses concurrents du monde « open weight » comme DeepSeek V3 et Llama-4 sur tous les benchmarks. Mais il rivalise aussi avec OpenAI o3 et Gemini 2.5 Pro allant même jusqu’à les dépasser sur certains tests comme Codeforces. Et la version « Qwen 32B » surpasse OpenAI o3-mini sur LiveBench. Les tests internes confirment aussi de solides aptitudes au « tool calling », une capacité essentielle pour l’orchestration de workflows, l’automatisation IT et l’ère des agents IA.
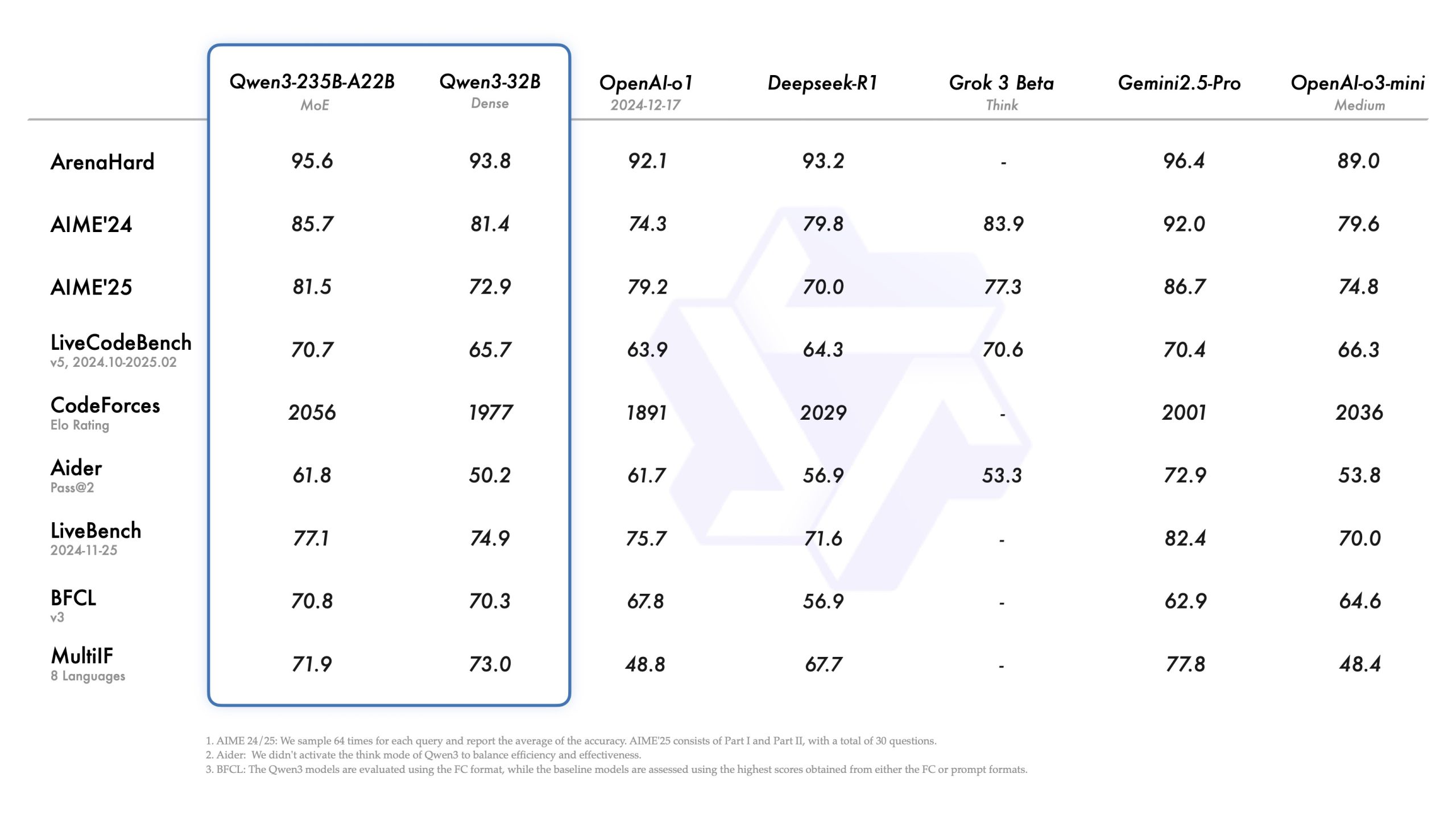
« Qwen3 représente une étape significative dans notre parcours vers l’Intelligence Artificielle Générale (IAG) et l’Intelligence Artificielle Superintelligente (IAS). En développant à la fois le pré-entraînement et l’apprentissage par renforcement (AR), nous avons atteint des niveaux d’intelligence plus élevés » estiment les responsables du projet chez Alibaba avant d’ajouter désormais focaliser leurs efforts sur la frugalité de l’IA, le raisonnement à long terme, l’augmentation de la fenêtre contextuelle, l’élargissement des modalités. « Notre prochaine itération promet d’apporter des avancées significatives au travail et à la vie de chacun » promettent-ils déjà.

 puis
puis