
Les lois d’échelle traditionnelles en IA semblent remises en question. Des acteurs comme Alibaba réinventent leurs approches avec des modèles plus performants et économiquement viables à l’instar des nouveaux « Marco-o1 » et « QwQ-32B-Preview » qui n’ont rien à envier aux nouveaux modèles « o1 » d’OpenAI.
En Europe, on parle peu des modèles IA Chinois. Leur ferait-on moins confiance par défaut qu’en des modèles américains (comme ceux d’OpenAI, Anthropic, Meta ou Google) ou européens (Mistral AI principalement) ? Peut-être, voire probablement.
Pourtant, les chercheurs Chinois ont largement les capacités de produire des modèles IA concurrents crédibles. C’est notamment le cas d’Alibaba qui n’hésite par ailleurs pas à publier ses modèles en open source dans une volonté de transparence comme de simplicité d’accès. En septembre 2024, lors de sa conférence annuelle Apsara, Alibaba Cloud a dévoilé plus de 100 modèles d’IA open source, regroupés sous le nom de Qwen 2.5. Ces modèles, variant de 0,5 à 72 milliards de paramètres, offrent des compétences avancées en mathématiques, en codage et prennent en charge plus de 29 langues. Ils peuvent ainsi répondre à une grande variété d’applications comme les assistants conversationnels, la génération de résumés, la traduction mais aussi d’autres applications plus dédiées dans des secteurs tels que l’automobile, le jeu vidéo et la recherche scientifique. Selon Alibaba, plus de 90.000 entreprises dans le monde exploiteraient déjà ses modèles Qwen 2.5 pour satisfaire leurs besoins d’applications IA et concrétiser leurs cas d’usage IA.
Deux modèles aux capacités de raisonnement accrues
Poursuivant ses efforts et innovations, Alibaba a annoncé cette semaine le lancement de deux nouveaux modèles de raisonnement : Marco-o1 et QwQ-32B-Preview, positionnés comme des alternatives au modèle o1 d’OpenAI.
QwQ-32B-Preview, doté de 32,5 milliards de paramètres, se distingue par sa capacité à traiter des prompts jusqu’à 32 000 mots. Il intègre un mécanisme unique d’auto-vérification des faits, lui permettant de résoudre des problèmes complexes de logique et de mathématiques. Selon les tests d’Alibaba, le modèle surpasse les versions o1-preview et o1-mini d’OpenAI sur certains benchmarks, notamment les tests AIME et MATH.
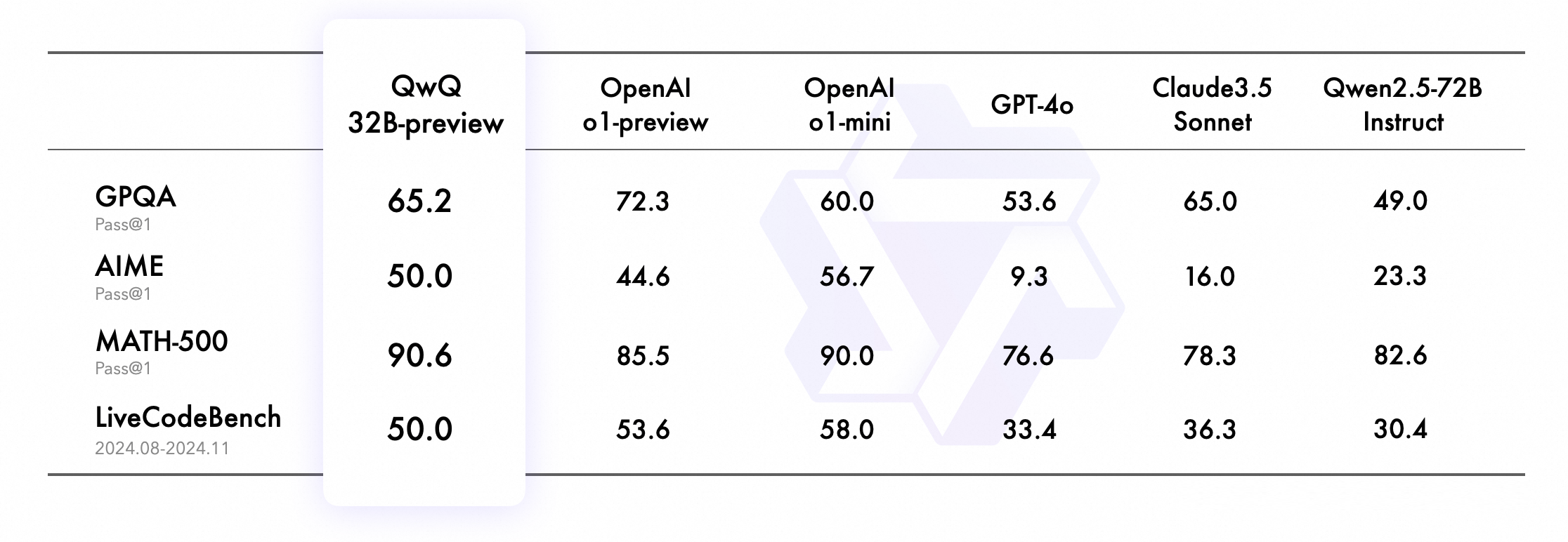
Bien que présentant des limitations, telles que des changements de langue inattendus ou des boucles de raisonnement ainsi que des limitations de traitement de certains sujets sensibles (conformément aux régulations chinoises), QwQ-32B-Preview est disponible sous licence Apache 2.0 sur Hugging Face.
Mais ce n’est pas tout. Le second modèle d’Alibaba, Marco-o1, est une version optimisée du modèle Qwen2-7B-Instruct d’Alibaba, qui introduit des innovations significatives dans le domaine du raisonnement. Le modèle intègre trois avancées techniques majeures :
- L’utilisation de l’algorithme Monte Carlo Tree Search (MCTS) pour explorer différentes voies de raisonnement
- Un mécanisme de réflexion permettant au modèle de réévaluer ses conclusions
- Une stratégie d’action flexible adaptant la granularité des étapes de raisonnement
La particularité de ces modèles réside dans leur approche du « test-time compute », une technique qui accorde plus de temps de traitement lors de l’inférence pour améliorer la qualité des réponses. Cette approche permet notamment à Marco-o1 d’exceller dans des tâches complexes comme la traduction d’expressions familières, où le contexte culturel est crucial.
Ces nouveaux modèles signés Alibaba ne sont pas les premiers « modèles de raisonnement IA » produits par les centres de R&D Chinois. En effet, un autre acteur dénommé DeepSeek a également dévoilé plus tôt son DeepSeek-R1-Lite-Preview lui aussi présenté comme un concurrent direct d’OpenAI « o1 ».
Ces développements s’inscrivent dans un contexte plus large de remise en question des « lois d’échelle » traditionnelles en IA, où l’augmentation des ressources de calcul et des données ne garantit plus systématiquement de meilleures performances. Un phénomène auquel tous les grands de l’IA sont aujourd’hui confrontés avec des modèles frontières « géants » (Google Gemini Ultra 1.5, OpenAI GPT 5, Claude Opus 3.5) qui ne sont pas aussi performants qu’espéré mais surtout qui n’offrent pas d’avancées justifiant leur taille et donc leur coût d’apprentissage et plus encore d’exploitation. Une situation largement évoquée par nos confrères d’IT for Business dans leur article « La dure quête du prochain LLM frontière ».
Cette situation pousse les grands laboratoires, dont Google qui aurait semble-t-il mobilisé une équipe de 200 personnes sur le sujet, à explorer de nouvelles approches comme le « test-time compute ».

 puis
puis