
En matière d’APM, l’approche corrélative est encore trop souvent privilégiée à l’approche causale. Cette différence, bien que subtile, s’avère fondamentale.
La notion de corrélation consiste à affirmer l’existence d’une connexion entre deux ensembles de données dès lors que l’on parvient à relier des évènements issus de chacun de ces ensembles. Encore très souvent privilégié, ce type d’approche peut toutefois conduire à des conclusions erronées, entraînant non seulement une perte de temps pour les équipes techniques, mais aussi des coûts élevés pour les équipes métiers.
Causalité et corrélation : une distinction réellement utile ?
Observons à titre d’exemple le graphique ci-dessous :
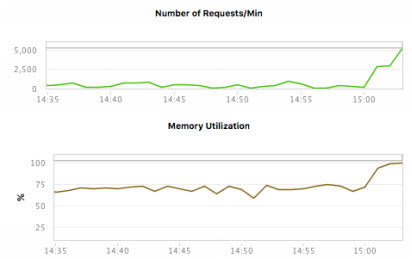
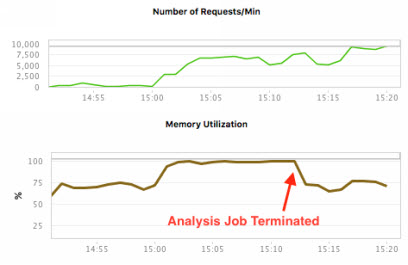
On y voit une corrélation évidente entre le nombre de requêtes par minute et l’utilisation de la mémoire. Dans le cadre d’une analyse corrélative, on peut donc a priori en déduire que l’augmentation de l’un a entraîné celle de l’autre. En réalité, ce n’est pas le cas. Car en poussant plus loin les investigations, on se serait aperçu qu’une importante analyse en cours d’exécution impactait la mémoire de manière intensive. La preuve, une fois cette analyse terminée, les choses ont pris une toute autre tournure :
En statistiques, le coefficient de corrélation mesure la force de la relation entre deux évènements, c’est-à-dire le degré selon lequel un changement de valeur sur l’un impacte un changement de valeur sur l’autre. Plus les deux changements sont synchronisés et systématiques, plus le coefficient de corrélation est élevé. Mais ce dernier ne renseigne toutefois pas sur le lien de causalité entre ces changements.
La corrélation n’implique pas la causalité
Constater que deux valeurs distinctes augmentent simultanément ne signifie pas forcément qu’il existe un quelconque lien entre elles.
Tyler Vigen [1] a ainsi réalisé une étude intéressante sur la notion de corrélation, en se basant sur les données de recensement américain. On y découvre, par exemple, que la consommation de margarine favoriserait les divorces … Absurde ? Bien sûr, puisqu’il n’existe évidemment aucune connexion entre les deux… C’est pourtant exactement le type de conclusions auquel il est possible d’arriver en matière d’APM lorsque l’on utilise la corrélation pour déterminer la cause d’un problème dans un data center.
La phrase selon laquelle « la corrélation n’implique pas la causalité » est bien connue. Pourtant, les approches APM corrélatives pullulent, tout en prétendant qu’il s’agit de causalité. Il n’est ainsi pas rare en la matière de conclure à une connexion entre deux évènements, simplement parce qu’ils se produisent au même moment. Les exemples Requêtes/Mémoire et Margarine/Divorce en sont de bons exemples …
La corrélation est un pari ; la causalité est une assurance
La causalité permet, quant à elle, de déterminer avec davantage de certitude si une donnée observée a un impact sur une autre donnée observée. Il s’agit de pouvoir directement connecter un événement A à un événement B, non pas parce qu’ils sont synchronisés, mais parce que lorsque A se produit, il crée un identifiant uniquement observable sur un événement B et non sur un événement C. Ce qui donne la certitude que A entraîne B. L’événement A déclenche l’événement B, mais par l’événement C, et ce, même s’ils sont tous synchronisés. C’est ce que l’on appelle la causalité.
Dans les systèmes informatiques complexes actuels, de nombreux événements se produisent en même temps. Et pour pouvoir identifier la cause d’un problème dans le système et répondre rapidement aux réclamations des utilisateurs, il faut être capable de savoir avec certitude quels évènements entraînent quels autres, parmi les nombreux traitements, machines et data centers. Ce n’est qu’à cette condition que l’on peut déterminer et résoudre rapidement la cause d’un incident dans un système d’une telle complexité.
Tout ceci est rendu possible par l’utilisation d’une solution d’APM, dotée d’une capacité à capturer toutes les transactions, en temps réel et en continu, d’une fonctionnalité de marquage de chaque appel à distance, et de l’implémentation de couches de big data et d’Intelligence Artificielle afin de fournir des données de causalité permettant de déterminer de manière infaillible l’origine d’un problème dans le système. Les gains pour une organisation sont considérables : temps, argent, image de marque… À ce titre, la corrélation apparaît comme un pari, là où la causalité fait figure d’assurance.
___________
Gilles Portier est Senior consultant APM Dynatrace

 puis
puis