
Comme chaque année en décembre, les spécialistes de l’intelligence artificielle se sont réunis, cette fois à Long Beach (Californie), pour partager les derniers résultats de leurs travaux lors de la conférence NIPS (Neural Information Processing Systems).
A l’origine cette conférence était confidentielle, mais au vu de l’intérêt phénoménal pour l’IA à travers le monde, elle est devenue un des événements les plus prisés de l’année. NIPS demeure l’occasion pour la communauté, composée essentiellement d’universitaires mais aussi d’employés des GAFAs, d’échanger sur les derniers progrès dans leurs disciplines et de récompenser les travaux les plus prometteurs.
Au-delà de cette conférence, l’IA a définitivement marqué l’année 2017 : des budgets monstrueux ont été alloués à la recherche ou à la création de startups, les entreprises se sont livrées à une bataille sans merci pour recruter les meilleurs talents (Google offre plus de 3 millions $ par an aux ingénieurs spécialistes Deep Learning d’NVIDIA par exemple), et même si on reste très loin du fantasme de l’IA générale, des avancées marquantes ont eu lieu, et NIPS est un des endroits privilégiés pour les recenser.
Alors ce début d’année 2018 est l’occasion de réaliser un tour d’horizon des derniers progrès en matière d’intelligence artificielle (dont certains étaient présentés à NIPS), et ce dans ses divers sous-domaines : reconnaissance d’image, reconnaissance du langage naturel ou encore l’analyse de données.
Computer Vision
Un des principaux domaines d’application de l’IA est celui qui vise à apprendre aux machines à comprendre les images (computer vision). Comprendre est un terme vague qui regroupe plusieurs notions, la machine devant procéder par étapes, à commencer par la classification : savoir qu’une image est une image de chat, par exemple. Vient ensuite la localisation, le fait de déterminer où exactement se situe le chat sur l’image en question. Mais une image ne contient rarement qu’un seul objet, et les algorithmes doivent être capables de les détecter tous (object detection) et de les isoler un par un (instance segmentation) : ici un chat, là un chien, et là, un canard.
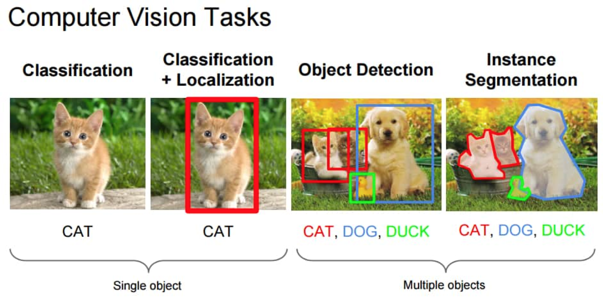
Source: Fei-Fei Li, Andrej Karpathy & Justin Johnson (2016) cs231n, Lecture 8 – Slide 8, Spatial Localization and Detection (01/02/2016). Available: http://cs231n.stanford.edu/slides/2016/winter1516_lecture8.pdf
Les différentes techniques développées pour ces fonctions se mesurent les unes aux autres au travers de benchmarks publics, basés notamment sur ImageNet, la gigantesque base de données d’images taggées coordonnée par l’université de Stanford. Parmi ces benchmarks, un des plus utilisés est le ILSVRC : l’évolution des scores ILSVRC permet de jauger des progrès de l’IA en matière de computer vision. On mesure le taux d’erreur, donc plus le score est faible, plus le modèle est performant.
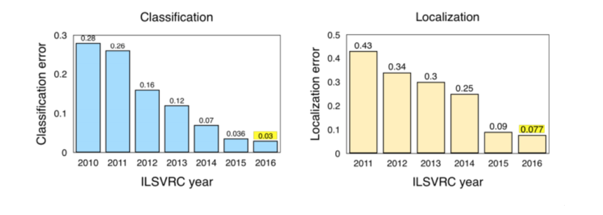 Source: Jia Deng (2016). ILSVRC2016 object localisation: introduction, results. Slide 2. Available: http://image-net.org/challenges/talks/2016/ILSVRC2016_10_09_clsloc.pdf
Source: Jia Deng (2016). ILSVRC2016 object localisation: introduction, results. Slide 2. Available: http://image-net.org/challenges/talks/2016/ILSVRC2016_10_09_clsloc.pdf
Si ces benchmarks sont utiles, pour mieux se représenter les progrès en matière de computer vision, la vidéo ci-dessous est plus parlante :
Le système de détection présenté, astucieusement baptisé YOLO, est capable d’identifier des objets en temps réel dans une vidéo, extrêmement rapidement et avec une fiabilité redoutable. Une des difficultés rencontrées est la capacité à reconnaître des objets très petits. Là encore, les progrès récents sont fulgurants, et l’image ci-dessous montre que les derniers modèles approchent la perfection.
 Hu and Ramanan. 2016. Finding Tiny Faces. [Online] arXiv: 1612.04402. Available: arXiv:1612.04402v1
Hu and Ramanan. 2016. Finding Tiny Faces. [Online] arXiv: 1612.04402. Available: arXiv:1612.04402v1
En matière de segmentation, c’est FusionNet qui a marqué les esprits cette année. Le système, basé sur du Deep Learning, est très prometteur pour des domaines allant de la santé aux véhicules autonomes : la vidéo ci-dessous montre son utilisation dans ce contexte précis.
Pour se repérer dans l’espace, un véhicule autonome devra impérativement être capable de distinguer les différents objets qui sont dans son champ de vision, et les solutions telles que FusionNet pourraient rendre de grands services. Mais il ne suffira pas de savoir repérer un objet, il faudra également être capable de le suivre (tracking) quand il est en mouvement, parfois très rapidement. Ici les progrès viendront de la recherche en IA (comme par exemple le projet Goturn par des chercheurs de Stanford) mais aussi d’une nouvelle génération de capteurs : les caméras event-based. Ces caméras d’un nouveau genre, encore à l’état de prototype, font déjà merveille dans les laboratoires.
Elles permettent de réaliser le tracking avec de bien meilleures performances (puissance de calcul, rapidité, précision) et pourraient rapidement débarquer dans nos appareils grands publics (drones, voitures, smartphones, …).
Une fois que le système a identifié les différents éléments présents sur une image, la compréhension est loin d’être achevée : faut-il encore pouvoir déterminer ce qui se passe, quelles actions sont en train d’effectuer les objets/personnes dans la scène. S’il est relativement trivial de déterminer qu’un être humain est présent sur une photo, il est moins évident de déduire ce qu’il est précisément en train de faire.
Pour réaliser cette performance, une des approches est de décomposer le corps humain et analyser les positions relatives de chacun des membres. La vidéo ci-dessous montre les travaux d’une équipe de chercheurs de Berkeley (à découvrir en détails ici).
Les progrès sont considérables quant à la capacité à traiter une grande quantité d’information en temps réel. La fin de la vidéo donne quelques indices quant aux applications possibles : les équipes de sport professionnel ont par exemple énormément à gagner à analyser avec précision le positionnement exact des corps de leurs athlètes pendant les matchs et les entrainements, ce qui était jusqu’alors totalement impossible. Les équipes de sport US témoignent régulièrement de leur utilisation de l’IA en 2017, et 2018 devrait voir cette tendance se confirmer. En outre, une fois que l’on est capable de déterminer avec précision les mouvements d’un individu, on peut les recréer en 3D, par exemple pour des applications de téléprésence comme celle de Microsoft Research ci-après :
Compréhension du langage naturel
Outre la compréhension des images via computer vision, un des autres principaux sous-domaines de l’IA est la compréhension du langage naturel (Natural Language Processing, NLP). Il décrit la capacité à comprendre l’écrit (et par extension la parole, puisque le speech to text est désormais pratiquement un problème résolu). Là encore, la technologie a beaucoup progressé, notamment du fait de l’utilisation du Deep Learning. Dans le domaine de la traduction automatique, le passage de Google Translate au Deep Learning a permis un saut quantique dans la qualité des résultats (lire à ce sujet l’excellent papier de Wired).
Pour comprendre le sens d’un texte, il est important d’en comprendre la tonalité : s’il est négatif, positif, ou neutre. En matière de e-commerce ou de modération, cela permet d’apprécier le contenu d’un avis ou d’un commentaire. Un groupe de chercheurs emmenés par Alec Radford d’OpenAI ont découvert, un peu malgré eux, une technique de Deep Learning donnant des résultats bluffants pour l’analyse de sentiments, qu’ils ont baptisée the sentiment neuron : l’animation ci-dessous montre le fonctionnement du sentiment neuron, qui analyse un texte caractère après caractère et en détermine la tonalité.
https://blog.openai.com/content/images/2017/04/low_res_maybe_faster.gif
Quand une machine a réussi à saisir le sens d’un texte, on peut tenter de lui demander de le résumer. Là encore, alors qu’on pensait encore récemment que seul un être humain avait les capacités d’abstraction nécessaires, l’IA avance à grands pas. Romain Paulus, qui travaille pour Einstein de Salesforce, a publié avec ses collègues des résultats bluffants sur un modèle Deep Learning capable de résumer un texte. On peut le voir à l’oeuvre dans les exemples ci-dessous : si le tout n’est pas parfait pour le moment, cela donne un aperçu de l’état de l’art.
https://einstein.ai/static/images/pages/research/your-tldr/summ-weights-800.gif

Tous ces progrès en matière d’IA sont rendus possibles par une tendance de fond : le hardware spécialisé, qui a connu des progrès impressionnants cette année. A NIPS 2017, des startups comme Graphcore montraient leurs dernières machines dédiées à l’IA, supposément capables de performances 3 fois supérieures au NVidia Volta, pourtant considéré comme le meilleur du marché. La bataille ne fait que commencer entre ces nouveaux acteurs, qu’on pourrait qualifier de IA-natifs, et des mastodontes comme NVidia ou Google et ses Tensor Processing Unit v2. Elon Musk, lors d’un talk à NIPS 2017, a annoncé que Tesla travaillait également sur ses propres puces dédiées à l’IA.
Ces innovations vont rapidement être prises en main par les développeurs, le temps écoulé entre la publication d’un papier de recherche et son application concrète dans un produit grand public n’ayant jamais été aussi court, ces nouvelles techniques d’IA devraient faire partie de notre quotidien dès 2018. L’année prochaine devrait donc voir une explosion des applications concrètes de l’intelligence artificielle.
_________
Benjamin Thomas, Consultant Innovation, Le Lab SQLI

 puis
puis