
Jusqu’ici les data scientists et autres utilisateurs BI devaient souvent jongler entre deux environnements différents et des jeux d’outils différents pour analyser les données structurées (exposées au travers des data warehouses) et données non structurées (accumulées dans les data lakes). Et les équipes IT se retrouvaient ainsi à maintenir deux systèmes analytiques complémentaires, le premier fournissant les données critiques au suivi du Business, le second fournissant toutes sortes de signaux sur les clients, les produits, les processus, les employés, etc.
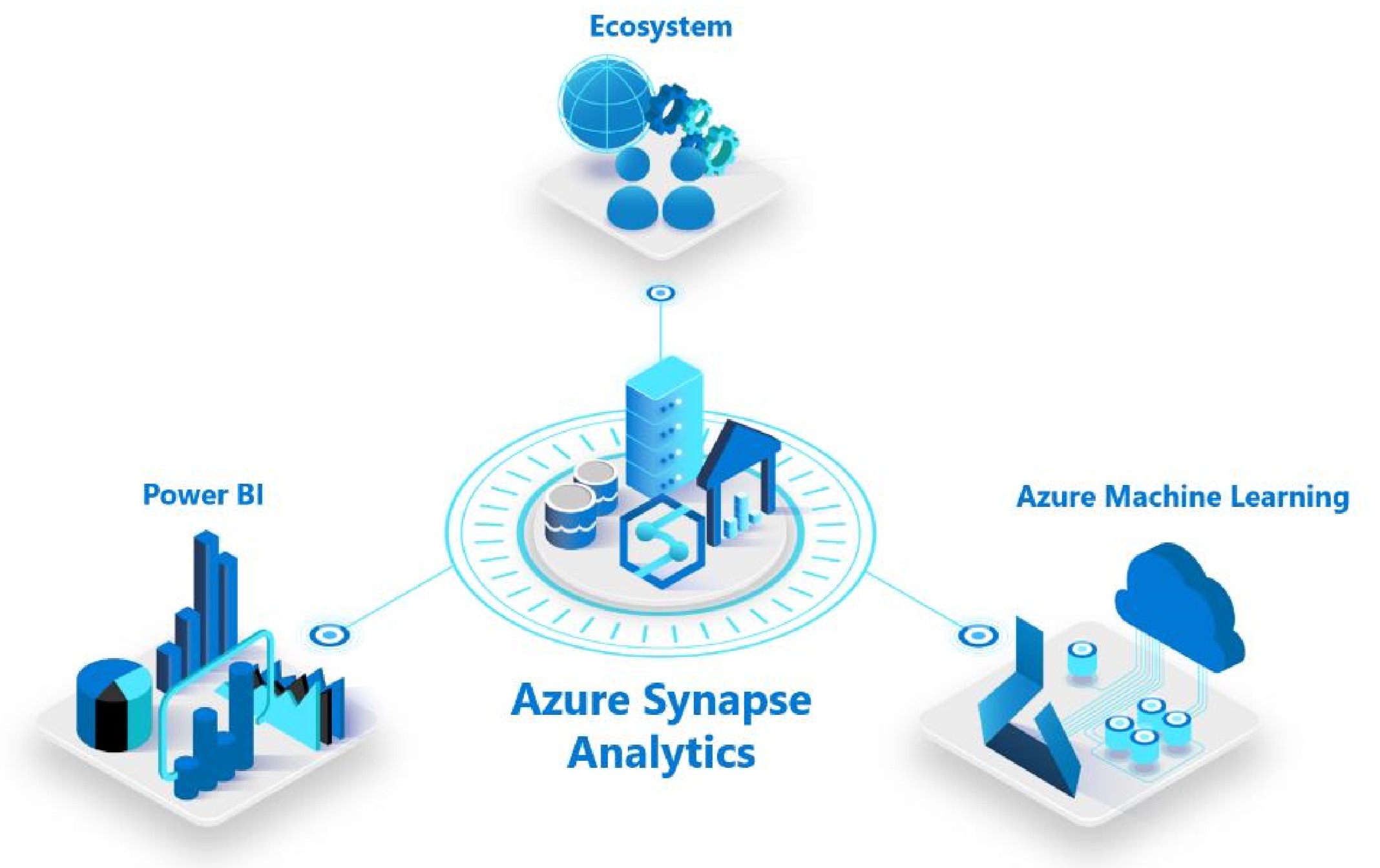 Azure Synapse veut unifier ces deux univers de données et offrir aux IT comme aux explorateurs de la donnée une expérience unifiée pour ingérer, préparer, gérer et délivrer la donnée aussi bien pour des besoins analytiques immédiats (Self BI) que pour des besoins de Machine Learning.
Azure Synapse veut unifier ces deux univers de données et offrir aux IT comme aux explorateurs de la donnée une expérience unifiée pour ingérer, préparer, gérer et délivrer la donnée aussi bien pour des besoins analytiques immédiats (Self BI) que pour des besoins de Machine Learning.
Dévoilé lors de sa conférence Ignite (du 4 au 6 novembre), Azure Synapse Analytics est en réalité une évolution majeure de l’ancienne offre d’entrepôts de données dans le cloud : Azure SQL Data Warehouse. Dès lors, les clients actuels d’Azure SQL Data Warehous n’ont pas à migrer leurs ressources pour directement profiter des nouvelles fonctionnalités d’Azure Synapse.
Ce nouveau service analytique est décrit comme « sans limites » et permet d’interroger les données soit en mode serverless soit selon des ressources provisionnées en fonction des contrôles de dépenses choisis par l’entreprise.
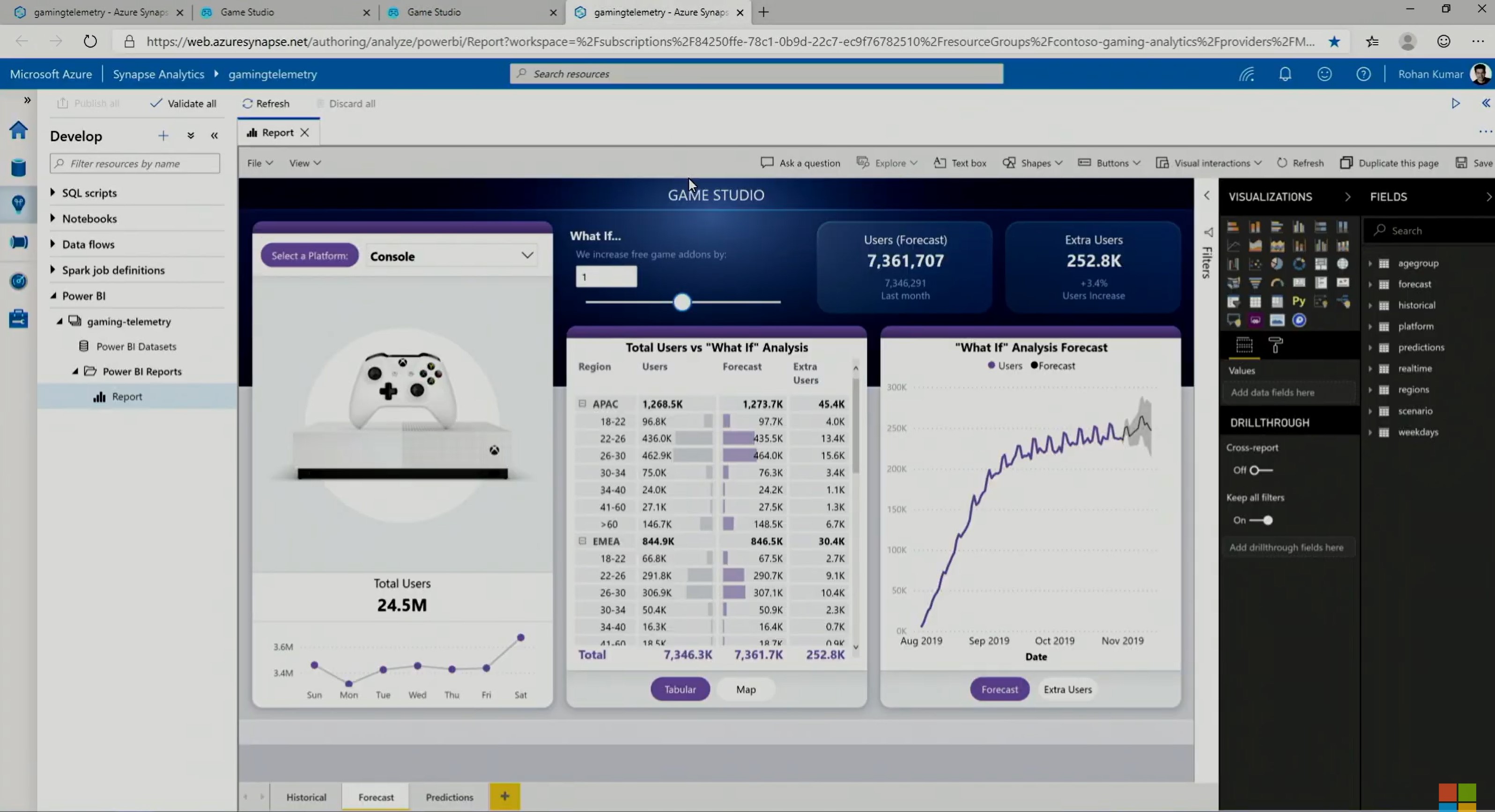 Il s’accompagne d’une nouvelle interface conviviale destinée à tous les acteurs de la donnée : Azure Synapse Studio offre des espaces de travail collaboratifs pour préparer et gérer les données mais aussi régenter les pipelines de données de façon très interactive, que ce soit à des fins de BI ou d’IA.
Il s’accompagne d’une nouvelle interface conviviale destinée à tous les acteurs de la donnée : Azure Synapse Studio offre des espaces de travail collaboratifs pour préparer et gérer les données mais aussi régenter les pipelines de données de façon très interactive, que ce soit à des fins de BI ou d’IA.
Bien évidemment, Azure Synapse offre une intégration naturelle à Power BI pour tous les besoins de visualisation ou de reporting et à Azure Machine Learning pour l’apprentissage et la construction de modèles. Mais le système est aussi très ouvert et d’ores et déjà supporté par un vaste écosystème de partenaires dans lequel on retrouve notamment Databricks, Informatica, Accenture, Talend, Attunity, Pragmatic Works and Adatis.
Mieux encore, Azure Synapse offre une intégration native avec Apache Spark, le moteur de traitement de données en open source réputé pour ses performances, sa simplicité et les analyses sophistiquées qu’il permet.
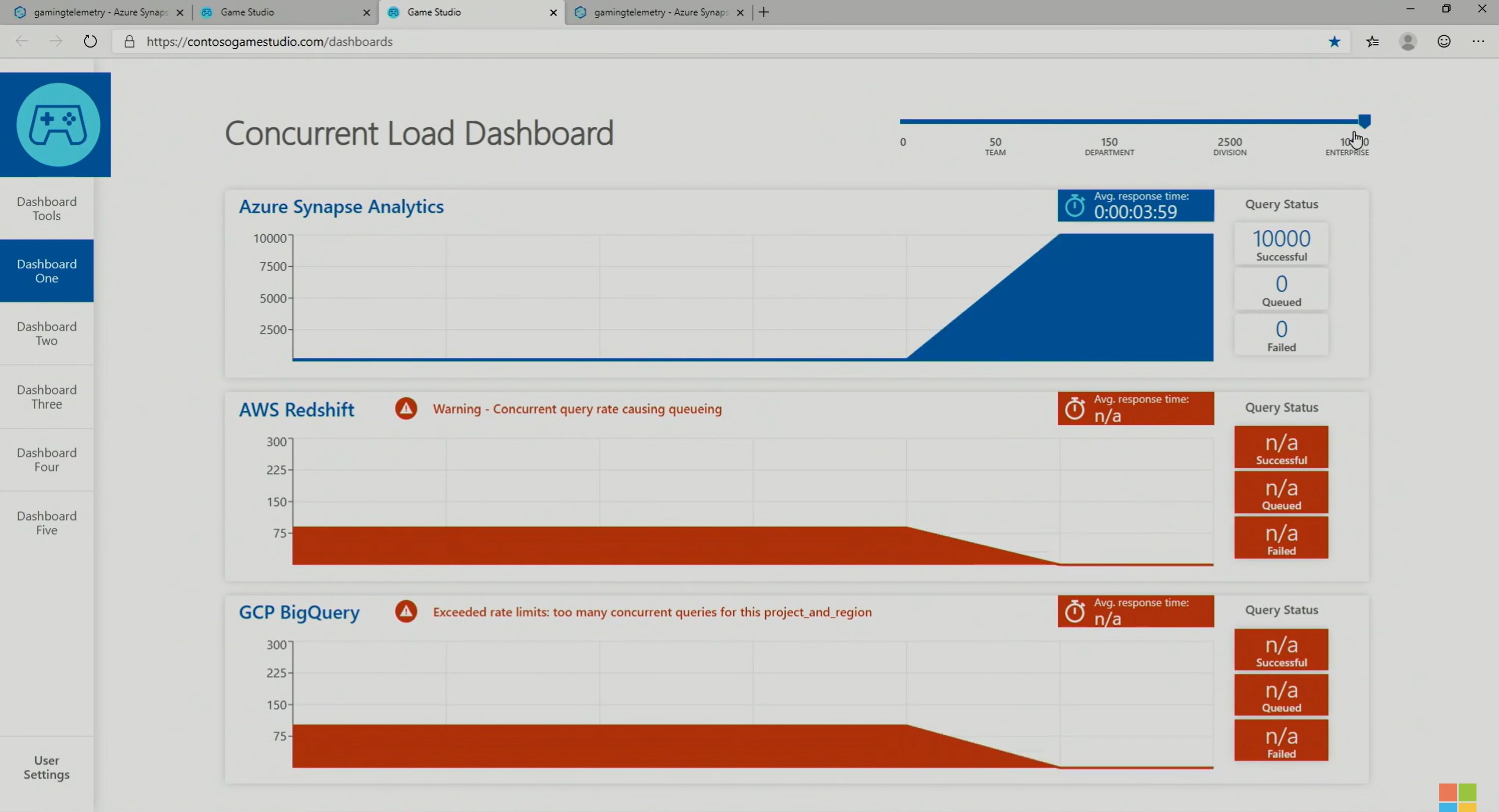 Lors de ses démonstrations sur Ignite, Microsoft a largement insisté sur les capacités « limitless » de son nouveau service n’hésitant pas à le comparer à AWS RedShift et Google BigQuery. Lors d’une même interrogation sur plus d’un péta-octet de données, Azure Synapse se montre 2 à 5 fois plus rapide que ses concurrents. Plus important encore, le service supporte aisément plus de 10.000 requêtes concurrentes là où ses concurrents commencent à souffrir dès la centaine de requêtes concurrentes atteinte (mettant les autres requêtes en attente).
Lors de ses démonstrations sur Ignite, Microsoft a largement insisté sur les capacités « limitless » de son nouveau service n’hésitant pas à le comparer à AWS RedShift et Google BigQuery. Lors d’une même interrogation sur plus d’un péta-octet de données, Azure Synapse se montre 2 à 5 fois plus rapide que ses concurrents. Plus important encore, le service supporte aisément plus de 10.000 requêtes concurrentes là où ses concurrents commencent à souffrir dès la centaine de requêtes concurrentes atteinte (mettant les autres requêtes en attente).

 puis
puis