
Plus qu’une tendance, les Data Hubs suscitent toujours plus d’attention ! De nombreuses entreprises étudient actuellement les différentes solutions du marché, implémentent les leurs, avec pour objectif à terme, de pouvoir gérer et gouverner leurs données critiques. Cependant, cette technologie est encore parfois considérée comme une alternative aux Data Warehouses (ou entrepôts de données) ou aux Data Lakes.
Selon le cabinet d’analystes Gartner, « les requêtes de clients se référant aux Data Hubs ont augmenté de 20% entre 2018 et 2019« .
Il est intéressant de noter que le cabinet d’analystes a remarqué que « plus de 25% de ces requêtes relèvent en fait du concepts de data lake« .
Vous êtes vous déjà demandé si vous avez besoin de mettre en place un Data Warehouse, un Data Lake ou un Data Hub? Probablement…
Il y a encore beaucoup de confusion autour de ces trois concepts, car ils semblent similaires. En réalité, ils présentent des différences fondamentales que tous devrait pouvoir identifier.
Voici la définition et les capacités de chacun d’entre eux, pour vous aider à mieux les distinguer :
Le Data Warehouse (entrepôt de données)
Le Data Warehouse est un dépôt central de données intégrées et structurées provenant de deux ou plusieurs sources différentes. Ce dispositif est principalement utilisé pour le reporting et l’analyse des données, et est considéré comme un élément essentiel de la business intelligence (BI). Les entrepôts de données permettent de réaliser des modèles d’analyse prédéfinis et reproductibles, distribués à un grand nombre d’utilisateurs dans l’entreprise.
Le Data Lake (lac de données)
Le Data Lake est un dépôt unique de toutes les données structurées et non structurées de l’entreprise. Il héberge des données brutes avec une faible qualité et exige de la part de l’utilisateur un traitement et une valorisation manuelle des données. Les Data Lakes sont, en général, une base solide pour la préparation des données, les rapports, la visualisation, l’analyse approfondie, la data science et le « machine learning ».
Le Data Hub (Hub de données)
Le Data Hub est à la fois un système de gestion de données, une source de données fiable et un système de référence pour les processus opérationnels et analytiques. Il centralise les données de l’entreprise qui sont essentielles pour toutes les applications et permet un partage transparent des données entre les différents systèmes de stockage, tout en étant le point unique de vérité pour l’initiative de gouvernance des données.
Les data hubs fournissent des données de référence aux applications et aux processus des entreprises. Ils sont également utilisés pour connecter les applications d’entreprise aux structures analytiques telles que les Data Warehouses et les Data Lakes.
Semblables en apparence mais différents en réalité
En bref, les Data Warehouses et les Data Lakes sont des dispositifs de collecte de données qui existent pour soutenir l’analyse de données dans l’entreprise tandis que les Data Hubs servent de médiateurs et de points de partage des données. Les data hubs ne sont pas uniquement axés sur les utilisations analytiques des données.
Dans certains cas, les Data Warehouses et les Data Lakes permettent la gouvernance de données, mais uniquement de manière réactive, tandis que les Data Hubs appliquent de manière proactive la gouvernance aux données présentes dans le système d’information.
Les Data Warehouses, les Data Lakes et les Data Hubs ne se substituent pas les uns aux autres. Néanmoins, ils sont complémentaires et, combinés, ils peuvent soutenir les initiatives “data-driven” et la transformation digitale des entreprises.
Le tableau ci-dessous résume leurs similitudes et leurs différences :
|
Data Hub |
Data Warehouse | Data Lake | |
| Usage primaire | Processus Opérationnels | Analytique et reporting | Analytique, reporting et Machine Learning |
| Type de données | Structurées | Structurées | Structurées et non structurées |
| Gouvernance | Pilier fondamental pour toutes les règles d’application de la gouvernance des données. | Gouvernance « après coup » du fait de l’utilisation des données opérationnelles existantes. | Une approche “à utiliser à vos risques et périls”.
Peu ou pas de gouvernance. |
| Qualité de la donnée | Très haute | Haute | Moyenne / faible |
| Intégration avec les applications d’entreprise | Bi-directionnelle
En temps-réel.
Intégration avec les processus métiers existants via des APIs. |
Mono-directionnelle ETL ou ELT en mode batch.
Les données transformées et traitées sont rafraîchies à fréquence basse (heure, jour ou semaine). |
Mono-directionnelle ETL ou ELT en mode batch.
Les données sont déversées sans contrôle dans le data lake en attendant que le consommateur les traite manuellement. |
| Interactions des utilisateurs métier | Peut être la principale source de production de données clés telles que les données master e et les données de référence. Offre des interfaces ergonomiques pour la création, la gestion et la recherche de données.
|
Propose un accès en lecture seule à des données agrégées et rapprochées par le biais de rapports, de tableaux de bord analytiques ou de requêtes ad-hoc. | Nécessite un traitement / une préparation des données avant leur utilisation. L’accès aux utilisateurs métier est principalement assuré par des rapports, des tableaux de bord ou des requêtes ad-hoc. Utilisé pour préparer des ensembles de données pour le Machine Learning. |
| Processus opérationnels de l’entreprise | Référentiel principal pour les données fiables provenant des processus d’entreprise.
Peut être le coordinateur principal des processus opérationnels de l’entreprise. |
Sert principalement aux processus analytiques. | Sert principalement aux processus analytiques et au Machine Learning. |
___________________
Par Youssra El Harrab, Directrice Marketing Global chez Semarchy.
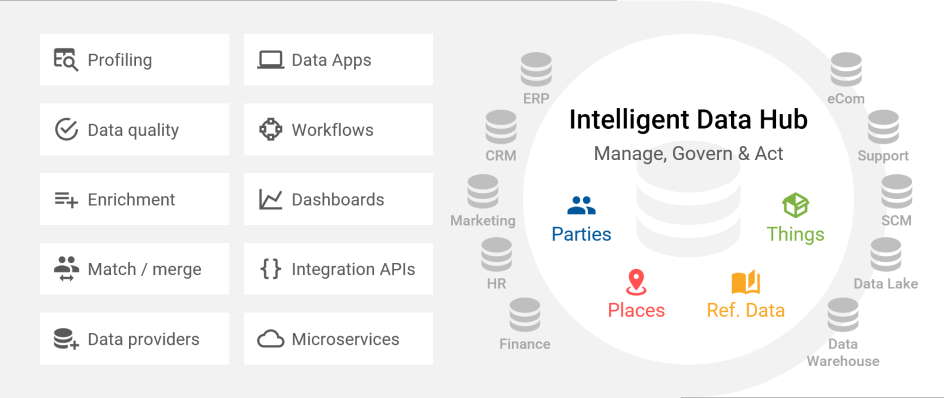
En savoir plus sur l’Intelligent Data Hub.

 puis
puis