
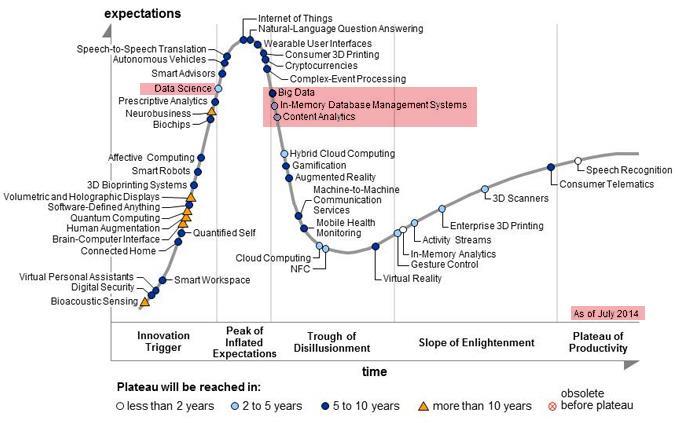
Hadoop fait l’objet d’un engouement important – Gartner parlerait de hype – mais la réalité de l’utilisation du framework synonyme de big data est encore relativement modeste.
« Pour permettre un traitement distribué des données accumulées par le moteur d’indexation libre Nutch, Doug Cutting entama une implémentation libre de MapReduce en Java qu’il appela Hadoop, du nom de l’éléphant Doudou de son fils »[i]. Le projet a ensuite été confié à la fondation Apache (Apache hadoop) et a ensuite connu un rapide développement en devenant un des projets open source les plus actifs. Aujourd’hui, hadoop est quasiment devenu synonyme de big data. Mais malgré un très fort intérêt et des réussites significatives dans les entreprises qui l’ont mis en œuvre, 54 % des décideurs interrogés déclarent ne pas avoir de projet d’installer et 18 % n’ont pas de projet dans les deux ans à venir. C’est ce qu’indique le Gartner dans une enquête sur la diffusion du logiciel (Survey Analysis: Hadoop Adoption Drivers and Challenges) selon laquelle 26 % seulement des décideurs interrogés ont expérimenté, réalisé un pilote ou installé hadoop. Cette enquête est en phase avec le graphique hype cycle (datant de juillet 2014) montrant le big data dans la phase critique dite « Trough of Disillusionnement » (Creux de la désillusion).
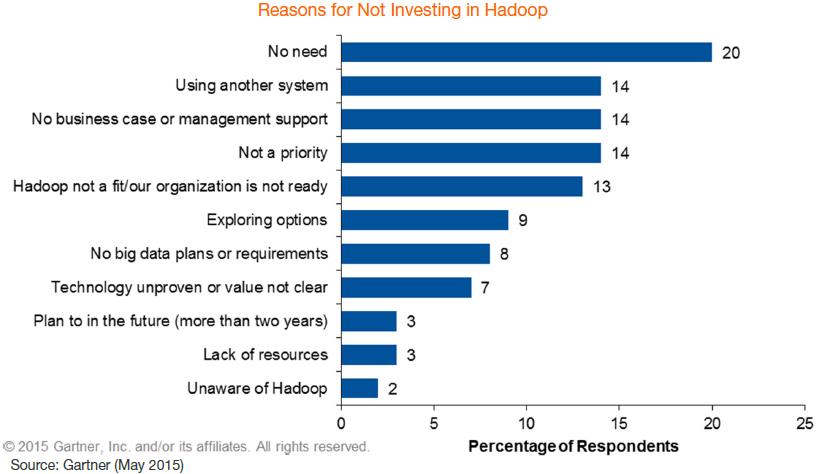
 Quelles sont les raisons de cette position d’attentisme face à une technologie aussi prometteuse ? D’abord, hadoop n’est tout simplement pas une priorité. Ce qui n’est pas trop surprenant étant donné l’éventail des tâches que les DSI ont a réalisé. Ensuite, que les technologies sont surdimensionnées par rapport aux défis que doivent relever les entreprises, ce qui se traduit par des coûts trop élevé par rapport aux bénéfices.
Quelles sont les raisons de cette position d’attentisme face à une technologie aussi prometteuse ? D’abord, hadoop n’est tout simplement pas une priorité. Ce qui n’est pas trop surprenant étant donné l’éventail des tâches que les DSI ont a réalisé. Ensuite, que les technologies sont surdimensionnées par rapport aux défis que doivent relever les entreprises, ce qui se traduit par des coûts trop élevé par rapport aux bénéfices.
Lorsqu’hadoop est adopté, ce sont les DSI ou les CDO (Chief Data Officer) qui sont en première ligne et prennent les décisions, notamment techniques, dans plus de la moitié des situations. Les architectes et les développeurs sont également impliqués dans cette aventure du big data. L’adoption d’hadoop intervient souvent comme une évidence dans un projet d’analytics car « c’est l’arbre le plus grand de la forêt du big data ».
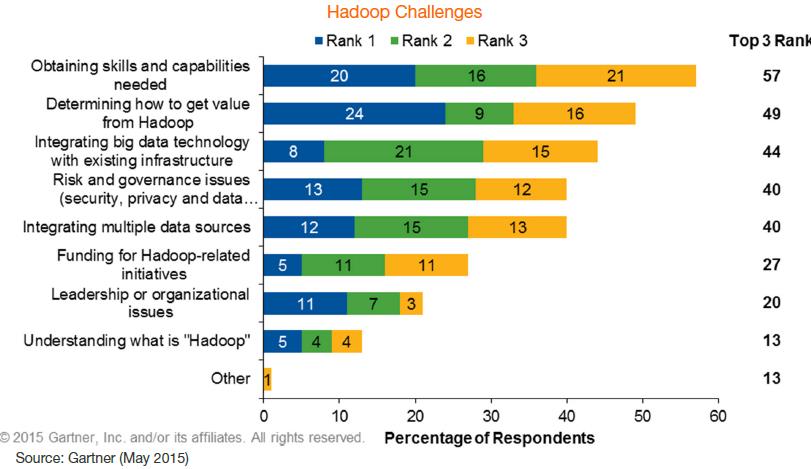
Quels sont alors les défis posés par l’adoption d’hadoop et un projet de big data ? Le premier d’entre eux est clairement le manque de compétences techniques sur un domaine qui, qu’on le veuille ou non, est encore très technique et relativement complexe. Avec le temps, des développements d’outils masquant cette complexité et permettant à une frange plus large d’utilisateurs puissent les mettre en œuvre. Une évolution qu’on a connue dans le domaine de la BI traditionnelle. Deuxième défi posé par la mise en œuvre d’hadoop et pas des moindres, la difficulté de démontrer la valeur d’hadoop. Un problème majeur pour ceux qui essaient de « vendre » un tel projet à leur direction générale. Troisième écueil de la mise en œuvre d’hadoop est l’intégration des technologies de big data avec les infrastructures existantes.
Les recommandations du Gartner
Les DSI, Chief Data Officer ou autres responsables qui souhaitent installer les hadoop doivent :
- Eviter de déployer hadoop avec la peur d’être en retard par rapport aux autres entreprises. Hadoop est encore en phase d’adoption précoce où les compétences et les réussites sont assez rares ;
- Démarrer avec des projets modestes avec le soutien d’un responsable métier est nécessaire. Un tel attelage permet d’acquérir des compétences et montrer quelques réussites avant de se lancer dans des projets d’envergure ;
- Se concentrer sur ceux qui utilisent le logiciel – incluant les applications et les outils qui seront dans les mains des utilisateurs finals.
Hortonworks fait mieux que prévu
Hortonworks, fournisseur de la seule distribution Hadoop 100 % open source, enregistre pour le premier trimestre de son année fiscale 2015 un chiffre d’affaires (GAAP) en augmentation de 167 % d’une année sur l’autre, atteignant 22,8 millions de dollars – bien au-delà des 18,2 millions attendus par les analystes de Wall Street.
Créé en 2011, Hortonworks a connu une croissance rapide avec une introduction en bourse en décembre dernier et est aujourd’hui valorisé à près d’un milliard de dollars.
[i] Les bases de données NoSQL et le Big data – Rahi Bruchez – Eyrolles – Avril 2015

 puis
puis