
La startup française lève 25 millions d’euros pour accompagner son développement international et imposer le concept DataOps dans les entreprises.
L’univers de la Data Science ne connaît pas que des succès. Loin de là. Seulement 5 à 15% des projets de Big Data et IA atteignent une mise en production si l’on en croit l’un des récents CIO Survey du Gartner. Et ce n’est pas si surprenant. Même s’ils sont focalisés sur la donnée, ces projets restent avant tout des projets informatiques qui rencontrent les mêmes problématiques de tests, évaluations en pré-production et mises en production que les projets applicatifs traditionnels.
Si la chaîne de production des projets Data aboutit à une partie « Ops » finalement très similaire à celle d’une chaîne DevOps, la partie en amont diffère notablement du « Dev » de « DevOps » même si on y parle développement et langages. Les outils et les technologies diffèrent. Cependant Data Engineers, Data Stewards, Data Architects, Data Scientists et Business Analysts ont des besoins collaboratifs fondamentaux similaires à ceux des équipes de développement du monde DevOps. Et, comme dans ce dernier, chaque équipe tend à venir avec ses propres technologies d’analyse de données et ses propres frameworks de Machine Learning et de Deep Learning.
L’ère du DataOps
C’est ainsi qu’a émergé il y a quelques années l’idée d’un DataOps. Gartner, qui reconnaît cette approche comme l’une des technologies émergentes montantes, définit la chaîne DataOps comme « une pratique de gestion collaborative des données axée sur l’amélioration de la communication, de l’intégration et de l’automatisation des flux de données entre les gestionnaires de données et les consommateurs de données dans l’ensemble d’une organisation. L’objectif de DataOps est de fournir plus rapidement de la valeur en créant une livraison prévisible et une gestion des modifications des données, des modèles de données et des artefacts connexes. DataOps utilise la technologie pour automatiser la conception, le déploiement et la gestion de la livraison des données avec des niveaux de gouvernance appropriés, et utilise les métadonnées pour améliorer l’utilisation et la valeur des données dans un environnement dynamique ».
Bref, DataOps cherche à industrialiser le monde de la Data un peu comme DevOps (et sa chaîne CI/CD) a industrialisé le monde du développement logiciel. Avec une promesse : améliorer et optimiser le cycle de vie des projets Data & Analytics en matière de rapidité et de qualité.
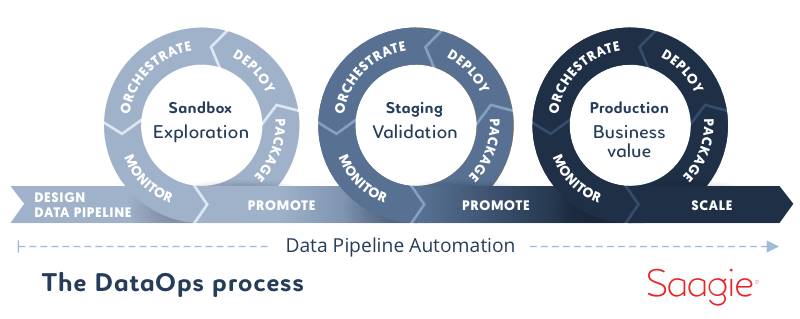
Un orchestrateur DataOps made in France
 Et, cocorico, l’un des spécialistes du DataOps est justement une startup française (née en 2013 avec une vision services mais qui a pivoté depuis 2016 dans l’univers du logiciel) dénommée Saagie.
Et, cocorico, l’un des spécialistes du DataOps est justement une startup française (née en 2013 avec une vision services mais qui a pivoté depuis 2016 dans l’univers du logiciel) dénommée Saagie.
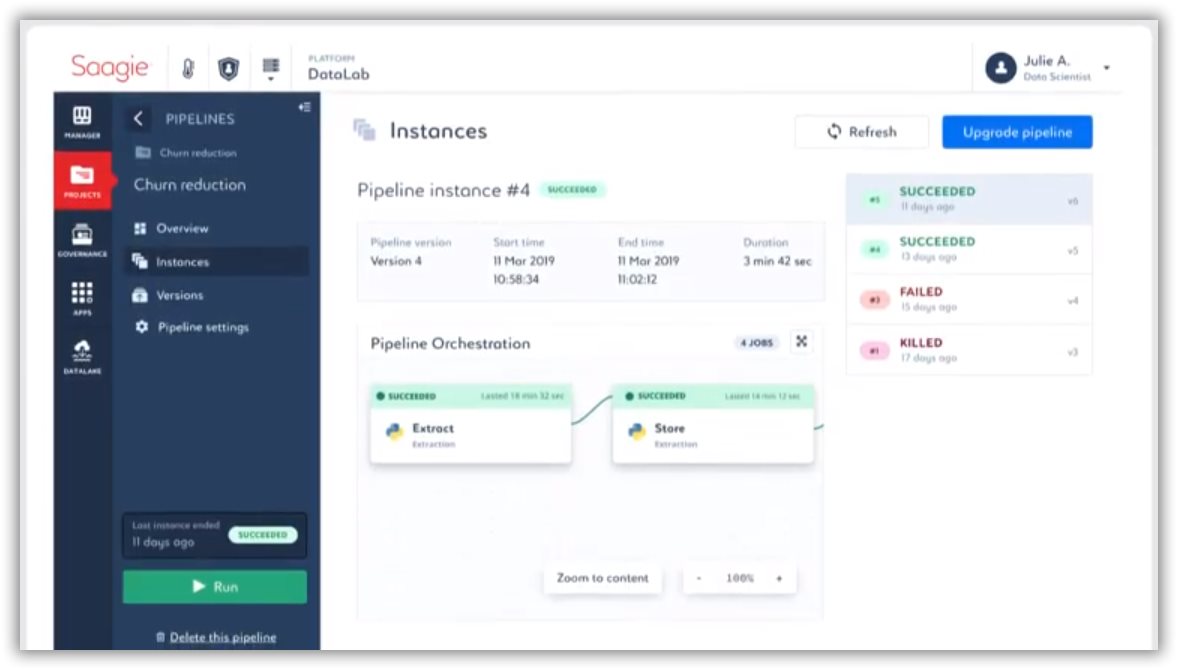
Sa solution est un orchestrateur DataOps. Il permet de mettre en place et orchestrer une chaîne Data de bout en bout en s’appuyant sur les technologies existantes. Il se déploie soit sur les clouds publics, soit sur un cluster Kubernetes interne, soit sur des appliances maison (construites à partir de Moonshots de HPE).
Objectif : non seulement améliorer la collaboration entre les différents métiers de la donnée (intégration, préparation, ingénierie) et les consommateurs de la donnée (data science, BI, data viz, …), mais aussi simplifier l’accès aux différentes briques technologiques par une interface visuelle conviviale et fournir un socle technique permettant de déployer en production, de façon fiable, rapide et automatisée, les multiples projets Data de l’entreprise.
L’orchestrateur offre une vue unifiée de la chaîne Data qui va de l’extraction des données jusqu’à leur consommation en passant par leur traitement et le déploiement sur les infrastructures des briques nécessaires. Il fournit également une métrologie complète se comportant comme une véritable tour de contrôle de la chaîne Data pour surveiller toutes les opérations et les sécuriser.
L’orchestrateur DataOps de Saagie s’appuie sur les différentes technologies open source de l’univers de la donnée. Il s’interface avec les ETL du marché, les principaux services ML et cognitifs dans le cloud (AWS, Azure, GCP, …), les différents Datalakes et Datawarehouses du marché grâce à une boîte à outils, des plugins et un SDK (qui permet notamment de lier l’orchestrateur aux solutions métiers de l’entreprise).
Une expansion à l’international
Saagie a annoncé cette semaine une levée de fonds de 25 millions d’euros. Réalisée en plein confinement et crise pandémique, cette dernière démontre la confiance des investisseurs en cette technologie. « Dans l’univers du numérique et de la data, il faut se penser global très vite« , explique Jerôme Tredan, CEO de Saagie.
La startup française, qui vient d’ouvrir un bureau à Londres et un autre à New-York, veut ainsi s’appuyer sur cette levée de fonds pour renforcer son aura à l’international mais également continuer à investir dans sa technologie pour multiplier les technologies supportées et enrichir son pipeline DataOps.
Elle compte déjà plus d’une cinquantaine de gros clients en production dont le Ministère des armées, la Matmut ou encore BVA.
La montée en puissance d’une startup française dans le domaine du DataOps est une bonne nouvelle à l’heure où la crise actuelle remet à l’ordre les sujets de souveraineté numérique et de souveraineté des données. Pour les responsables de Saagie, entre la vision chinoise des données très orientée contrôle des populations et celle beaucoup plus mercantile des américains, il existe une approche purement européenne du rôle et du traitement de la donnée, approche que la startup compte bien défendre et étendre au-delà de nos frontières.

 puis
puis