
Les équipes opérationnelles, communément appelées “Ops”, sont garantes du bon fonctionnement du système informatique. Le rôle des Ops est d’assurer que ce cœur battant technologique de l’entreprise ne soit ni perturbé ni arrêté, car tous les autres organes de l’organisation s’en verraient affectés.
Cependant, par manque de temps, de moyens ou des deux, l’attention des Ops est souvent focalisée sur des préoccupations comme la performance ou la conformité des systèmes, sans pour autant assurer les “bases”. Or, faire l’impasse sur la cyber-hygiène voue à l’échec tout chantier construit sur le système d’information (SI).
Voici les 4 étapes successives, formant une pyramide de maturité des Ops, et illustrant le cheminement nécessaire pour gérer efficacement leur SI et les missions qui leur sont confiées.
1/ La découverte et l’inventaire des appareils, le point de départ
Avant d’établir des standards, appliquer une politique de patching, édicter des règles de configuration ou assurer la maintenance des applications tierces, les Ops doivent s’assurer, en premier lieu, d’avoir identifié l’intégralité des endpoints à surveiller. Or, on ne protège bien que ce que l’on voit. Ce principe, bien acquis dans le domaine de la sécurité IT, l’est beaucoup moins parmi les Ops. Par conséquent, cet inventaire repose aujourd’hui encore bien (trop) souvent sur du déclaratif ou du manuel. Or, des outils de découverte peuvent automatiser cette procédure et en améliorer considérablement les résultats. Ces outils ont l’avantage de scanner tous les endpoints quel que soit l’endroit où ils se trouvent, et non de se concentrer uniquement sur le siège et le réseau de l’entreprise. Dans le contexte d’équipes distribuées que nous connaissons actuellement, le parc utilisé dans les différentes branches de la structure, ses boutiques, ses entrepôts, ses usines doit être inventorié…
Ce n’est qu’une fois cet inventaire connu, entretenu et cartographié que les Ops seront en mesure de progresser dans la gestion de leur parc informatique. En effet, comment établir une politique de patching si personne n’a connaissance de la présence de MacOS dans le système d’information ? Ce genre d’exemple est frappant mais fréquent, tout comme le constat que les projets de sécurité, de conformité, de gestion sont souvent entrepris alors que la connaissance des endpoints dans le SI est approximative. Cette approche ne peut en aucun cas être couronnée de succès.
Retour de terrain : On constate aujourd’hui qu’environ 10% des endpoints (ordinateurs portables et fixes, serveurs) ne sont pas gérés par les Ops, d’une part car ils ne sont pas connus des systèmes actuels, et d’autre part parce que leur méthode de découverte est souvent basée sur des référentiels voués à être imprécis (ex: les sites Active Directory se basant sur une topologie réseau souvent très macro et non à jour).
Ainsi, pourquoi démarrer un projet de déploiement d’un EDR s’il n’est, de facto, pas déployé sur 10% des appareils ?
2/ Conformité et correctifs interviennent dans un second temps
Une fois les endpoints découverts et inventoriés, les Ops peuvent s’attacher à établir des standards de conformité. Ils définissent alors les comportements normaux sur leur parc informatique (reprenant l’exemple précédent, est-il normal que des Mac figurent parmi les postes de l’entreprise ?). Le tout, dans le respect des règles de l’entreprise et des aspects légaux, notamment dans des secteurs hautement réglementés comme la banque-finance, la santé, etc.
Une fois que les Ops ont acquis ces connaissances sur leur parc informatique, ils sont capables de créer une base de référence des normes et de déployer la politique adéquate de gestion des correctifs pour chaque système d’exploitation.
A contrario, les Ops victimes de shadow IT (c’est-à-dire quand des employés utilisent des solutions matérielles ou logicielles à l’insu des responsables informatique) ne sont pas en mesure de déployer ces politiques de manière efficace car ils ne savent pas exactement quels outils sont présents dans le parc. Pire encore : bien qu’ils aient connaissance des failles exploitées par les hackers, ils ignorent que leur parc est potentiellement vulnérable à des attaques les exploitant et ne prennent donc pas les mesures nécessaires. C’est la raison pour laquelle, depuis cinq ans, certaines entreprises sont toujours vulnérables à WannaCry.
Retour de terrain : Les récentes menaces apportées par des logiciels tiers comme SolarWinds et Kaseya ont mis en exergue la difficulté des entreprises à savoir rapidement si elles étaient concernées par la présence de ces solutions dans leur parc. Ces solutions étant faciles à acquérir et déployer par des filiales un peu éloignées ou indépendantes du siège, il est difficile de savoir si elles sont vraiment absentes sur 100% des appareils. Pour lever ce doute, il est donc essentiel d’avoir un inventaire à jour et exhaustif, permettant d’assurer le « 100% » (pour qu’il ne soit pas en réalité un 90%) et d’interroger en temps réel son environnement.
3/ La politique de configuration des appareils et le maintien à jour des applications tierces
Lorsque la conformité est définie et la base de correctifs mise en place sur un parc intégralement inventorié et mis à jour, vient le temps de définir et d’appliquer la politique de configuration des endpoints. Cela permet d’avoir un état des lieux en temps réel de chaque endpoint. En effet, à ce stade les Ops maîtrisent donc « ce qu’elles opèrent », « ce qui est standard » et « ce qui existe » dans leur SI. Les conditions sont alors réunies pour se pencher sur la gestion des applications tierces. C’est seulement dans ce contexte que l’homogénéité du parc informatique est assurée et qu’il est possible de le gérer uniformément. Cela implique également de s’assurer que les applications embarquées sur des robots ou des machines-outils soient également mises à jour, et de s’assurer que l’éditeur/le fabricant s’engage bien à proposer et/ou effectuer les mises à jour requises. Ce qui met en lumière le rôle plus décisif et plus « mature » des Ops, leur capacité à apporter du conseil aux métiers, bien souvent décisionnaires des achats informatiques industriels.
Retour de terrain : C’est sur cet aspect que les Ops sont souvent dépassés. Les métiers étant la priorité pour le business d’une entreprise, les critères d’acquisition des machines industrielles sont bien souvent non-IT ou liés à la sécurité. Parce que leurs inventaires ne le permettent pas, les Ops découvrent souvent les limitations de ces équipements bien trop tard. Voilà pourquoi il est primordial d’acquérir dans un premier temps la visibilité sur son parc informatique, puis, si le contexte le permet, d’y intégrer l’équipement industriel et de le considérer comme tout autre endpoint.
4/ Cartographier les services applicatifs et surveiller les performances
Dès lors que leur environnement est connu, conforme et maintenu à jour, les Ops peuvent ajouter d’autres services, tels que la cartographie des applications et de leurs dépendances, afin de prévenir les pannes ou de maximiser leurs performances. Ainsi, les Ops deviennent proactives et garantissent aux utilisateurs finaux qu’ils disposent des outils et des ressources adéquats pour leurs cas d’usage spécifiques.
La performance est un des sujets prioritaires au sein des DSI de nos jours. Pourtant, les équipes Ops ou Sécurité ont fréquemment accumulé des solutions par couches successives, pour acquérir la visibilité dont elles ne disposaient pas ou pour répondre à de nouveaux cas d’usage. Bien souvent, l’inventaire de base n’était même pas maîtrisé. De ce fait, les performances utilisateur sont impactées par un empilement de solutions (qu’elles reposent sur un agent local ou sur le scan à distance).
Retour de terrain : On voit souvent des projets, ou plutôt des ‘task forces’ d’urgence se mettre en place pour répondre à des plaintes de performance sur le SI. Comme tout chantier, si les Ops n’ont ni la maîtrise première de leur inventaire, de leur conformité, du maintien à jour des applications et systèmes ni la capacité de connaître leur dépendances, alors celui-ci se révèlera long, poussif et, bien souvent, sans réelle amélioration in fine. « L’hygiène » du SI est ici essentielle avant de pouvoir suspecter un éventuel souci de performances, qui, majoritairement, est dû à des équipements sous-dimensionnés, des applications non mises à jour ou des dépendances non connues.
Un défi de taille
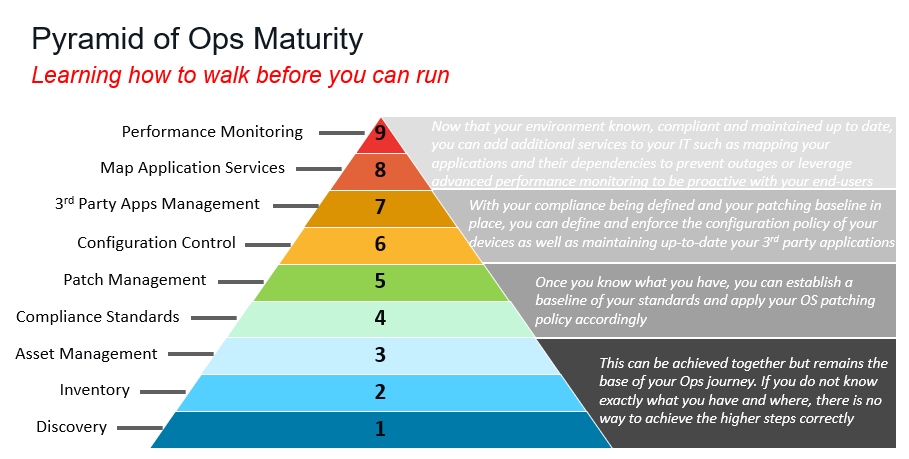
Pyramide de maturité Ops
La connaissance exhaustive du parc informatique de l’entreprise constitue un prérequis indispensable pour assurer le succès des missions que les Ops doivent effectuer afin de garantir le bon fonctionnement des métiers nécessaires au succès de l’entreprise. De plus en plus préoccupés par la qualité de l’expérience utilisateur, malgré l’augmentation de la diversité des besoins métiers et des endpoints employés, ils ne doivent néanmoins pas se laisser détourner des actions fondamentales à réaliser, et en premier lieu l’identification et l’inventaire de l’intégralité de leur parc informatique.
Les entreprises ont, certes, pris conscience de l’importance de bien connaître leur parc informatique pour en optimiser le fonctionnement. Cependant, avoir une visibilité exhaustive sur ce parc reste encore aujourd’hui un défi prioritaire et difficile à relever.
___________________
par Damien Bénazet, Directeur, Technical Account Management chez Tanium

 puis
puis