
Lors de sa conférence « Data+AI Summit 2024 », Databricks a annoncé une refonte complète de sa plateforme cloud pour un fonctionnement en total « serverless ». Une refonte qui sera opérationnelle dès le 1er juillet !
Au fil des années, Databricks s’est imposée comme l’une des grandes plateformes de données Cloud et le principal concurrent de Snowflake. Sa plateforme de données fonctionne sur Azure, AWS et Google Cloud et s’appuie notamment sur S3, Azure Lake Cloud Storage (ALCS) et Google Cloud Storage.
Pour autant, mettre en œuvre toute la solution est une tâche longue et complexe notamment parce qu’il faut – pour bien des fonctionnalités centrales – monter semi-manuellement un VPC (Virtual Private Cloud) pour héberger les clusters Databricks dans votre environnement AWS/Azure/GCP. Pas simple.
Pourquoi une telle complexité ? Parce que la plateforme n’était pas à l’origine « Serverless » et imposait une gestion de l’environnement IaaS qui l’exécutait. Ce qui au début, alors que les entreprises n’avaient aucune confiance dans le cloud et voulaient contrôler l’infrastructure, pouvait séduire. Mais les temps ont changé. D’ailleurs, au fil des années, certaines fonctionnalités Databricks ont adopté un mode serverless sans que ce soit pour autant le cas de la plateforme sous-jacente.
Mais cette époque est révolue. À partir du 1er juillet 2024, Databricks disposera d’un déploiement totalement serverless. Non seulement les clients existants pourront opter pour un redéploiement dans ce mode, mais Databricks ne cache pas que cette formule aura désormais sa préférence et que les prochaines évolutions et fonctionnalités de sa plateforme ne seront probablement implémentées que sur sa nouvelle architecture serverless. Il faut dire que l’entreprise a lourdement investi et qu’il aura fallu trois ans à ses ingénieurs pour réécrire intégralement la plateforme dans une conception réellement serverless.
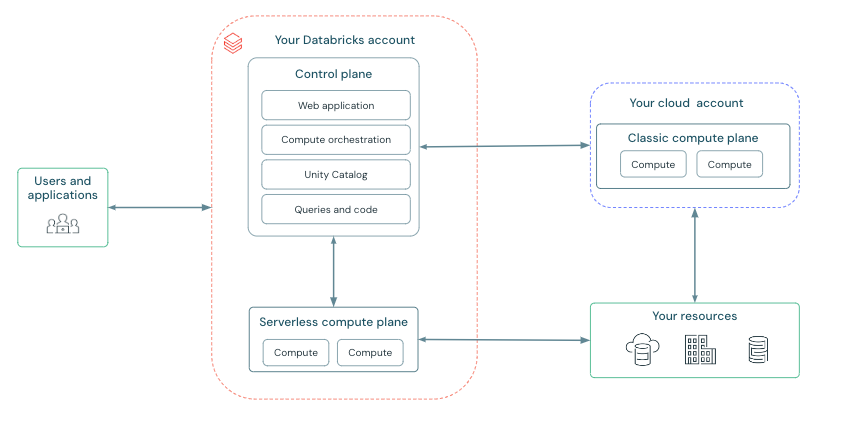
Mode 100% serverless (en rouge) versus mode classique (en bleu)
Selon Databricks, les clients ont désormais tout intérêt à basculer dans ce mode :
– Le serverless rend la plateforme plus simple, plus accessible, plus évolutive. Il n’y a plus de cluster à configurer et gérer, plus de type de machines à définir, plus d’options autoscale à activer, plus d’instances spot à négocier. Toutes ces complexités disparaissent et Databricks s’occupe de tout. Y compris des optimisations des datasets ce qui n’était pas le cas avant.
– Selon l’éditeur, le mode serverless est plus économique parce que l’on ne paye que ce que l’on consomme et que l’on ne paye pas les « idle times » (les temps d’inactivité), contrairement à ce qui se passe avec un VPC sur votre compte AWS/Azure/GCP.
– Avec le Serverless, toutes les responsabilités basculent sur Databricks : il n’y a plus de répartition entre ce que l’organisation cliente opère dans le cloud public hébergeur, ce que le cloud public opère et ce que Databricks opère. Là, c’est directement Databricks qui opère tous les nœuds de compute dans le cloud hébergeur. D’ailleurs l’entreprise cliente n’a plus avoir de compte AWS/Azure/GCP pour gérer son Databricks et se contente d’un seul compte Databricks (ça c’est la théorie, en pratique il faut bien des comptes Cloud pour vos données stockées dans le cloud).
Reste maintenant à savoir combien des 12.000 clients actuels de Databricks demanderont à rapidement basculer en Serverless. A priori, ils ont tout à y gagner…

 puis
puis