
Databricks veut faciliter la création d’applications exploitant du ML grâce à un nouveau service « Model Serving » qui fluidifie et simplifie la mise en production des modèles.
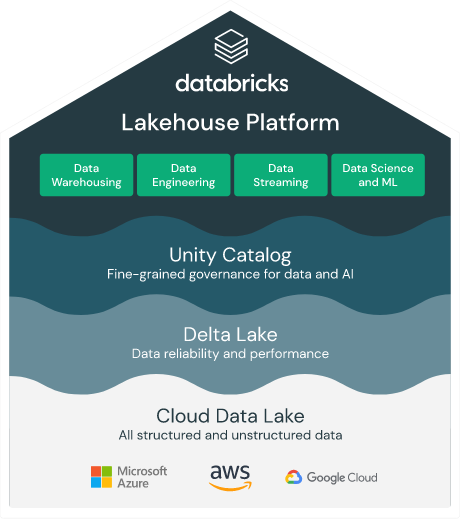
Pionnier de l’analytique unifié dans le cloud, Databricks a depuis étendu sa vision au Machine Learning et aux chaînes ML. L’éditeur est ainsi considéré par Gartner comme l’un des leaders des plateformes cloud de Data Science. Sa plateforme Lakehouse offre une vue cohérente des données tout au long du cycle de vie ML, ce qui accélère les déploiements et réduit les erreurs, sans avoir à assembler des services disparates.
En matière de ML, la difficulté n’est pas uniquement d’être capable d’élaborer des modèles adaptés à l’entreprise et à ses métiers. Il faut aussi, sans cesse, améliorer et réentraîner les modèles pour qu’ils soient toujours plus pertinents et qu’ils le restent en prenant en compte l’incessant flux de nouvelles données. C’est pourquoi l’éditeur focalise en ce moment ses efforts pour fluidifier la chaîne ML et faire en sorte de simplifier autant que possible le déploiement et l’exécution de modèles ML en production.
Databricks annonce cette semaine la disponibilité de « Databricks Model Serving », un nouveau service ‘serverless’ destiné à fluidifier tout ce processus et rendre les modèles ML plus efficaces et plus rapidement disponibles (notamment en les exposant sous forme d’API REST).
Le service supprime les besoins et la complexité liés à la construction d’une infrastructure MLops. Il prend en charge toutes les tâches lourdes associées au processus de déploiement des modèles ML, de la configuration de l’infra jusqu’à la gestion des instances, le contrôle des compatibilités, l’application des correctifs, la montée en charge ou la réduction des ressources dynamiquement en fonction des besoins, etc.
 « Databricks Model Serving permet aux équipes de data scientists d’accélérer la mise en production en simplifiant les déploiements, en réduisant les coûts et en offrant une expérience entièrement intégrée directement dans la plateforme Lakehouse », explique Patrick Wendell, cofondateur et vice-président de l’ingénierie chez Databricks. « Cette offre permettra aux clients de déployer des modèles plus nombreux, dans des délais de mise en production optimisés, tout en réduisant le coût total de possession et la difficulté de la gestion d’une infrastructure complexe. »
« Databricks Model Serving permet aux équipes de data scientists d’accélérer la mise en production en simplifiant les déploiements, en réduisant les coûts et en offrant une expérience entièrement intégrée directement dans la plateforme Lakehouse », explique Patrick Wendell, cofondateur et vice-président de l’ingénierie chez Databricks. « Cette offre permettra aux clients de déployer des modèles plus nombreux, dans des délais de mise en production optimisés, tout en réduisant le coût total de possession et la difficulté de la gestion d’une infrastructure complexe. »
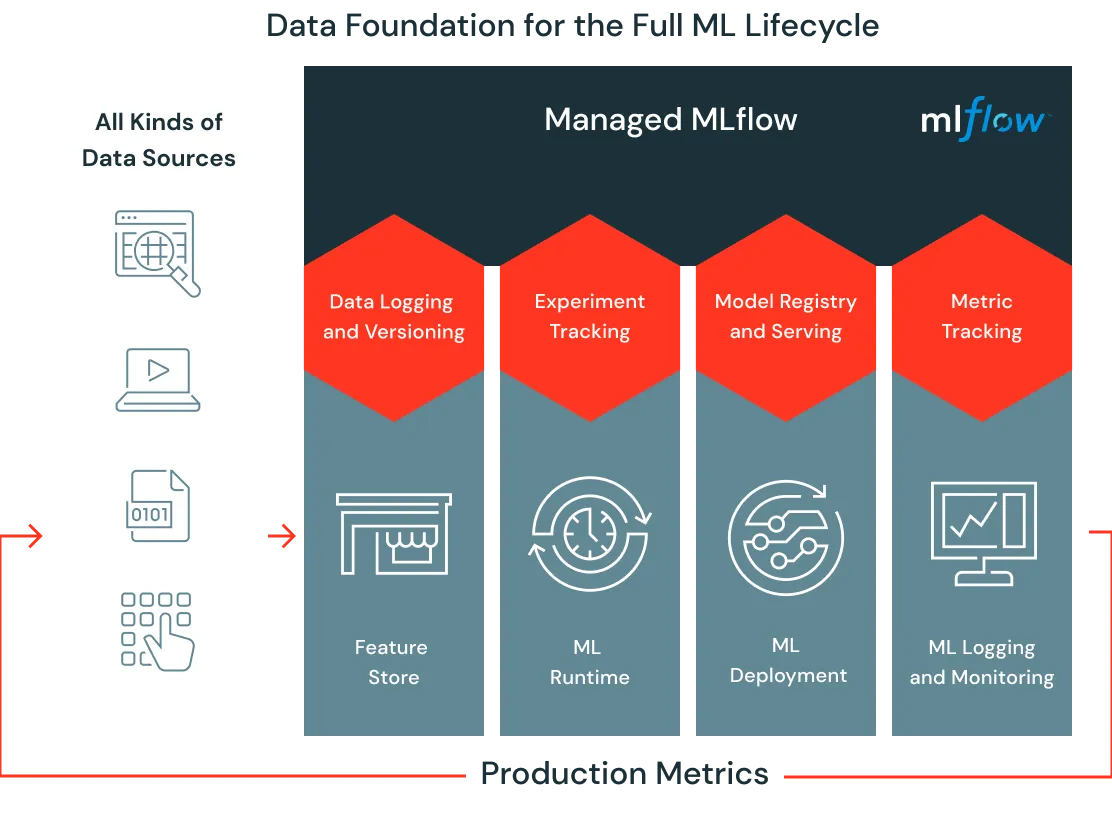
Entièrement managé, ce nouveau service s’intègre bien évidemment aux composantes clés de la plateforme Lakekouse en commençant par le Feature Store (pour centraliser, gérer et réutiliser les caractéristiques, attributs et propriétés, sur lesquels s’appuient les modèles ML), MLflow () et le service de gouvernance des données « Unified Data Governance ».
Databricks annonce également travailler à enrichir cette plateforme pour l’étendre à davantage de modèles et offrir ainsi la même fluidité aux modèles Deep Learning par exemple. Il est vrai que la concurrence s’intensifie entre DataBrick, Dremio, Snowflake, Dataiku et les propres plateformes data cloud de Microsoft, Google Cloud et AWS. Faire une pause dans les innovations n’est pas à l’ordre du jour. Même si bien des entreprises n’ont pas la maturité pour profiter pleinement de telles plateformes.

 puis
puis